Accelerating Candidate Generation in Recommender Systems Using Milvus paired with PaddlePaddle
If you have experience developing a recommender system, you are likely to have fallen victim to at least one of the following:
- The system is extremely slow when returning results due to the tremendous amount of datasets.
- Newly inserted data cannot be processed in real time for search or query.
- Deployment of the recommender system is daunting.
This article aims to address the issues mentioned above and provide some insights for you by introducing a product recommender system project that uses Milvus, an open-source vector database, paired with PaddlePaddle, a deep learning platform.
This article sets out to briefly describe the minimal workflow of a recommender system. Then it moves on to introduce the main components and the implementation details of this project.
The basic workflow of a recommender system
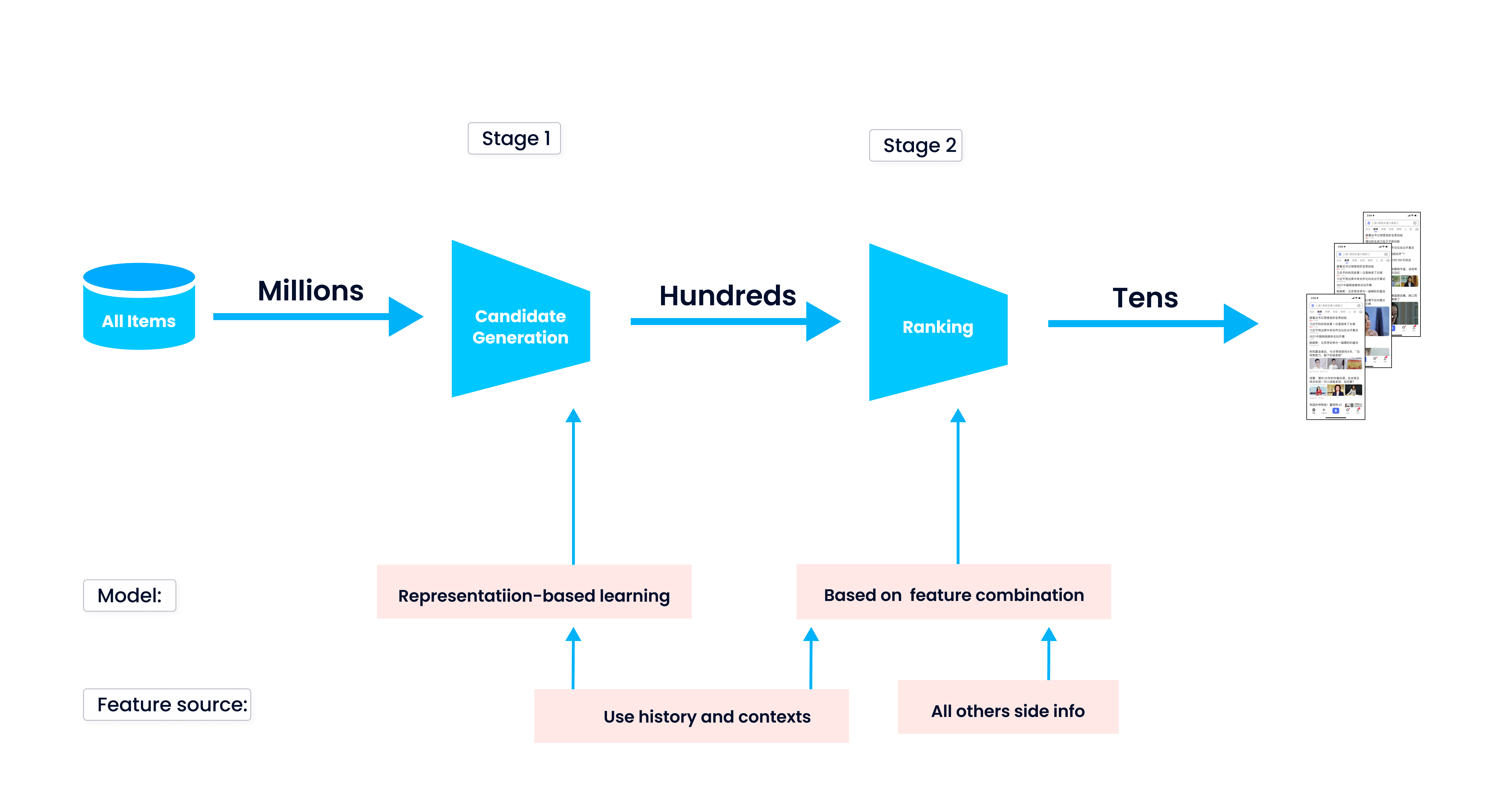
Before going deep into the project itself, let’s first take a look at the basic workflow of a recommender system. A recommender system can return personalized results according to unique user interest and needs. To make such personalized recommendations, the system goes through two stages, candidate generation and ranking.
 2.png
2.png
The first stage is candidate generation, which returns the most relevant or similar data, such as a product or a video that matches the user profile. During candidate generation, the system compares the user trait with the data stored in its database, and retrieves those similar ones. Then during ranking, the system scores and reorders the retrieved data. Finally, those results on the top of the list are shown to users.
In our case of a product recommender system, it first compares the user profile with the characteristics of the products in inventory to filter out a list of products catering to the user’s needs. Then the system scores the products based on their similarity to user profile, ranks them, and finally returns the top 10 products to the user.
 3.png
3.png
System architecture
The product recommender system in this project uses three components: MIND, PaddleRec, and Milvus.
MIND
MIND, short for "Multi-Interest Network with Dynamic Routing for Recommendation at Tmall", is an algorithm developed by Alibaba Group. Before MIND was proposed, most of the prevalent AI models for recommendation used a single vector to represent a user’s varied interests. However, a single vector is far from sufficient to represent the exact interests of a user. Therefore, MIND algorithm was proposed to turn a user’s multiple interests into several vectors.
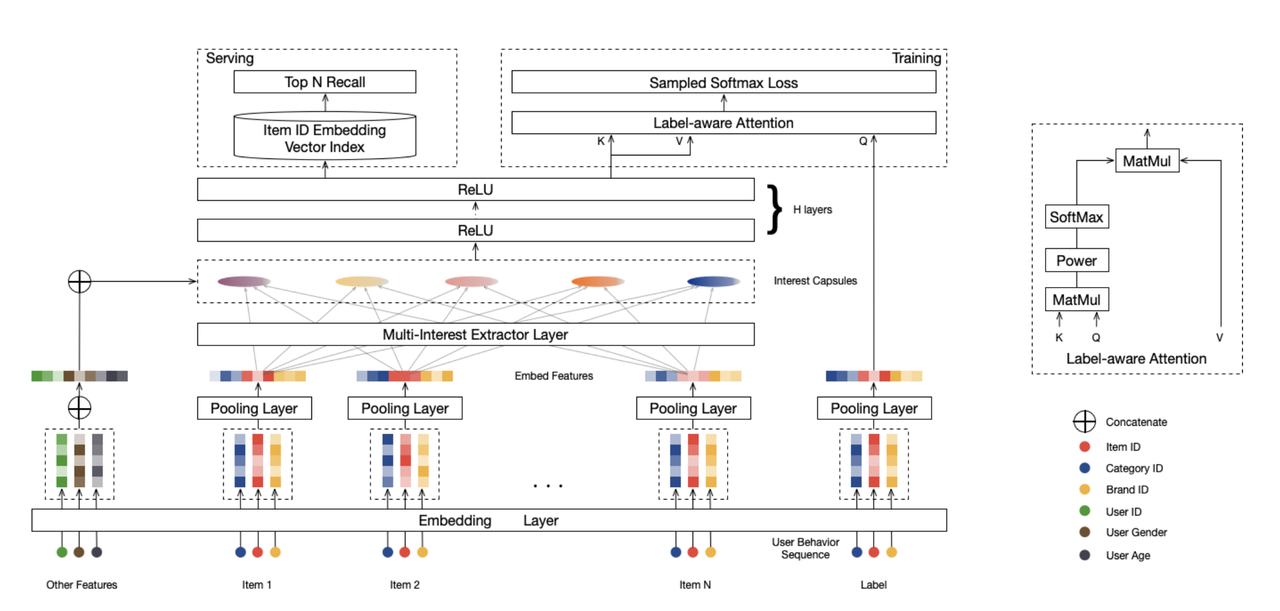
Specifically, MIND adopts a multi-interest network with dynamic routing for processing multiple interests of one user during the candidate generation stage. The multi-interest network is a layer of multi-interest extractor built on capsule routing mechanism. It can be used to combine a user’s past behaviors with his or her multiple interests, to provide an accurate user profile.
The following diagram illustrates the network structure of MIND.
 4.png
4.png
To represent the trait of users, MIND takes user behaviors and user interests as inputs, and then feeds them into the embedding layer to generate user vectors, including user interest vectors and user behavior vectors. Then user behavior vectors are fed into the multi-interest extractor layer to generate users interest capsules. After concatenating the user interest capsules with user behavior embeddings and using several ReLU layers to transform them, MIND outputs several user representation vectors. This project has defined that MIND will ultimately output four user representation vectors.
On the other hand, product traits go through the embedding layer and are converted into sparse item vectors. Then each item vector goes through a pooling layer to become a dense vector.
When all data are converted into vectors, an extra label-aware attention layer is introduced to guide the training process.
PaddleRec
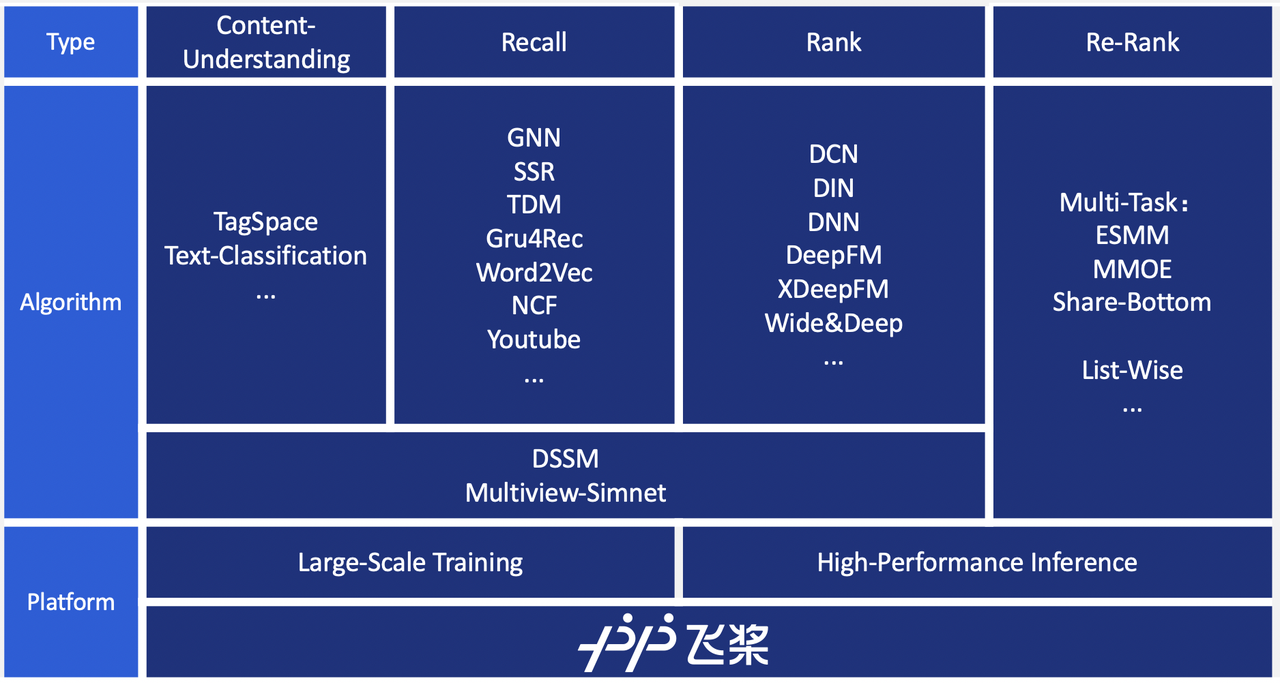
PaddleRec is a large-scale search model library for recommendation. It is part of the Baidu PaddlePaddle ecosystem. PaddleRec aims to provide developers with an integrated solution to build a recommendation system in an easy and rapid way.
 5.png
5.png
As mentioned in the opening paragraph, engineers developing recommender systems often have to face the challenges of poor usability and complicated deployment of the system. However, PaddleRec can help developers in the following aspects:
Ease of use: PaddleRec is an open-source library that encapsulates various popular models in the industry, including models for candidate generation, ranking, reranking, multitasking, and more. With PaddleRec, you can instantly test the effectiveness of the model and improve its efficiency through iteration. PaddleRec offers you an easy way to train models for distributed systems with excellent performance. It is optimized for large-scale data processing of sparse vectors. You can easily scale PaddleRec horizontally and accelerate its computing speed. Therefore, you can quickly build training environments on Kubernetes using PaddleRec.
Support for deployment: PaddleRec provides online deployment solutions for its models. The models are immediately ready for use after training, featuring flexibility and high availability.
Milvus
Milvus is a vector database featuring a cloud-native architecture. It is open sourced on GitHub and can be used to store, index, and manage massive embedding vectors generated by deep neural networks and other machine learning (ML) models. Milvus encapsulates several first-class approximate nearest neighbor (ANN) search libraries including Faiss, NMSLIB, and Annoy. You can also scale out Milvus according to your need. The Milvus service is highly available and supports unified batch and stream processing. Milvus is committed to simplifying the process of managing unstructured data and providing a consistent user experience in different deployment environments. It has the following features:
High performance when conducting vector search on massive datasets.
A developer-first community that offers multi-language support and toolchain.
Cloud scalability and high reliability even in the event of a disruption.
Hybrid search achieved by pairing scalar filtering with vector similarity search.
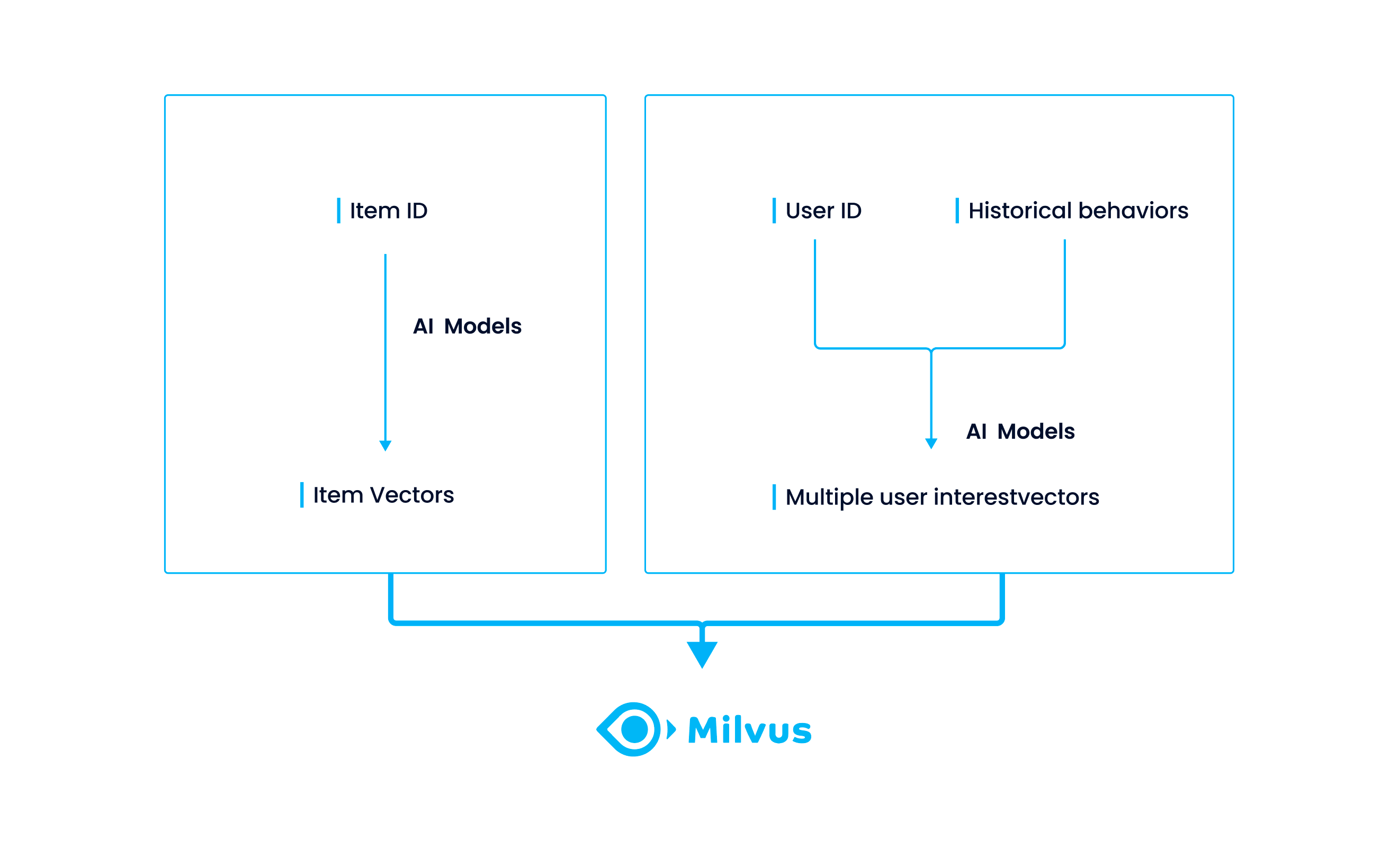
Milvus is used for vector similarity search and vector management in this project because it can solve the problem of frequent data updates while maintaining system stability.
System implementation
To build the product recommender system in this project, you need to go through the following steps:
- Data processing
- Model training
- Model testing
- Generating product item candidates
- Data storage: item vectors are obtained through the trained model and are stored in Milvus.
- Data search: four user vectors generated by MIND are fed into Milvus for vector similarity search.
- Data ranking: each of the four vectors has its own
top_ksimilar item vectors, and four sets oftop_kvectors are ranked to return a final list oftop_kmost similar vectors.
The source code of this project is hosted on the Baidu AI Studio platform. The following section is a detailed explanation of the source code for this project.
Step 1. Data processing
The original dataset comes from the Amazon book dataset provided by ComiRec. However, this project uses the data that is downloaded from and processed by PaddleRec. Refer to the AmazonBook dataset in the PaddleRec project for more information.
The dataset for training is expected to appear in the following format, with each column representing:
Uid: User ID.item_id: ID of the product item that has been clicked by the user.Time: The timestamp or order of click.
The dataset for testing is expected to appear in the following format, with each column representing:
Uid: User ID.hist_item: ID of the product item in historical user click behavior. When there are multiplehist_item, they are sorted according to the timestamp.eval_item: The actual sequence in which the user clicks the products.
Step 2. Model training
Model training uses the processed data in the previous step and adopts the candidate generation model, MIND, built on PaddleRec.
1. Model input
In dygraph_model.py, run the following code to process the data and turn them into model input. This process sorts the items clicked by the same user in the original data according to the timestamp, and combines them to form a sequence. Then, randomly select an item``_``id from the sequence as the target_item, and extract the 10 items before target_item as the hist_item for model input. If the sequence is not long enough, it can be set as 0. seq_len should be the actual length of the hist_item sequence.
def create_feeds_train(self, batch_data):
hist_item = paddle.to_tensor(batch_data[0], dtype="int64")
target_item = paddle.to_tensor(batch_data[1], dtype="int64")
seq_len = paddle.to_tensor(batch_data[2], dtype="int64")
return [hist_item, target_item, seq_len]
Refer to the script /home/aistudio/recommend/model/mind/mind_reader.py for the code of reading the original dataset.
2. Model networking
The following code is an extract of net.py. class Mind_Capsual_Layer defines the multi-interest extractor layer built on the interest capsule routing mechanism. The function label_aware_attention() implements the label-aware attention technique in the MIND algorithm. The forward() function in the class MindLayer models the user characteristics and generates corresponding weight vectors.
class Mind_Capsual_Layer(nn.Layer):
def __init__(self):
super(Mind_Capsual_Layer, self).__init__()
self.iters = iters
self.input_units = input_units
self.output_units = output_units
self.maxlen = maxlen
self.init_std = init_std
self.k_max = k_max
self.batch_size = batch_size
# B2I routing
self.routing_logits = self.create_parameter(
shape=[1, self.k_max, self.maxlen],
attr=paddle.ParamAttr(
name="routing_logits", trainable=False),
default_initializer=nn.initializer.Normal(
mean=0.0, std=self.init_std))
# bilinear mapping
self.bilinear_mapping_matrix = self.create_parameter(
shape=[self.input_units, self.output_units],
attr=paddle.ParamAttr(
name="bilinear_mapping_matrix", trainable=True),
default_initializer=nn.initializer.Normal(
mean=0.0, std=self.init_std))
class MindLayer(nn.Layer):
def label_aware_attention(self, keys, query):
weight = paddle.sum(keys * query, axis=-1, keepdim=True)
weight = paddle.pow(weight, self.pow_p) # [x,k_max,1]
weight = F.softmax(weight, axis=1)
output = paddle.sum(keys * weight, axis=1)
return output, weight
def forward(self, hist_item, seqlen, labels=None):
hit_item_emb = self.item_emb(hist_item) # [B, seqlen, embed_dim]
user_cap, cap_weights, cap_mask = self.capsual_layer(hit_item_emb, seqlen)
if not self.training:
return user_cap, cap_weights
target_emb = self.item_emb(labels)
user_emb, W = self.label_aware_attention(user_cap, target_emb)
return self.sampled_softmax(
user_emb, labels, self.item_emb.weight,
self.embedding_bias), W, user_cap, cap_weights, cap_mask
Refer to the script /home/aistudio/recommend/model/mind/net.py for the specific network structure of MIND.
3. Model optimization
This project uses Adam algorithm as the model optimizer.
def create_optimizer(self, dy_model, config):
lr = config.get("hyper_parameters.optimizer.learning_rate", 0.001)
optimizer = paddle.optimizer.Adam(
learning_rate=lr, parameters=dy_model.parameters())
return optimizer
In addition, PaddleRec writes hyperparameters in config.yaml, so you just need to modify this file to see a clear comparison between the effectiveness of the two models to improve model efficiency. When training the model, the poor model effect can result from model underfitting or overfitting. You can therefore improve it by modifying the number of rounds of training. In this project, you only need to change the parameter epochs in config.yaml to find the perfect number of rounds of training. In addition, you can also change the model optimizer, optimizer.class,or learning_rate for debugging. The following shows part of the parameters in config.yaml.
runner:
use_gpu: True
use_auc: False
train_batch_size: 128
epochs: 20
print_interval: 10
model_save_path: "output_model_mind"
# hyper parameters of user-defined network
hyper_parameters:
# optimizer config
optimizer:
class: Adam
learning_rate: 0.005
Refer to the script /home/aistudio/recommend/model/mind/dygraph_model.py for detailed implementation.
4. Model training
Run the following command to start model training.
python -u trainer.py -m mind/config.yaml
Refer to /home/aistudio/recommend/model/trainer.py for the model training project.
Step 3. Model testing
This step uses test dataset to verify the performance, such as the recall rate of the trained model.
During model testing, all item vectors are loaded from the model, and then imported into Milvus, the open-source vector database. Read the test dataset through the script /home/aistudio/recommend/model/mind/mind_infer_reader.py. Load the model in the previous step, and feed the test dataset into the model to obtain four interest vectors of the user. Search for the most similar 50 item vectors to the four interest vectors in Milvus. You can recommend the returned results to users.
Run the following command to test the model.
python -u infer.py -m mind/config.yaml -top_n 50
During model testing, the system provides several indicators for evaluating model effectiveness, such as Recall@50, NDCG@50, and HitRate@50. This article only introduces modifying one parameter. However, in your own application scenario, you need to train more epochs for better model effect. You can also improve model effectiveness by using different optimizers, setting different learning rates, and increasing the number of rounds of testing. It is recommended that you save several models with different effects, and then choose the one with the best performance and best fits your application.
Step 4. Generating product item candidates
To build the product candidate generation service, this project uses the trained model in the previous steps, paired with Milvus. During candidate generation, FASTAPI is used to provide the interface. When the service starts, you can directly run commands in the terminal via curl.
Run the following command to generate preliminary candidates.
uvicorn main:app
The service provides four types of interfaces:
- Insert : Run the following command to read the item vectors from your model and insert them into a collection in Milvus.
curl -X 'POST' \
'http://127.0.0.1:8000/rec/insert_data' \
-H 'accept: application/json' \
-d ''
- Generate preliminary candidates: Input the sequence in which products are clicked by the user, and find out the next product that the user may click. You can also generate product item candidates in batches for several users at one go.
hist_itemin the following command is a two-dimensional vector, and each row represents a sequence of the products that the user has clicked in the past. You can define the length of the sequence. The returned results are also sets of two-dimensional vectors, each row representing the returneditem ids for users.
curl -X 'POST' \
'http://127.0.0.1:8000/rec/recall' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"top_k": 50,
"hist_item": [[43,23,65,675,3456,8654,123454,54367,234561],[675,3456,8654,123454,76543,1234,9769,5670,65443,123098,34219,234098]]
}'
- Query the total number of product items: Run the following command to return the total number of item vectors stored in the Milvus database.
curl -X 'POST' \
'http://127.0.0.1:8000/rec/count' \
-H 'accept: application/json' \
-d ''
- Delete: Run the following command to delete all data stored in the Milvus database .
curl -X 'POST' \
'http://127.0.0.1:8000/qa/drop' \
-H 'accept: application/json' \
-d ''
If you run the candidate generation service on your local server, you can also access the above interfaces at 127.0.0.1:8000/docs. You can play around by clicking on the four interfaces and entering the value for the parameters. Then click “Try it out” to get the recommendation result.
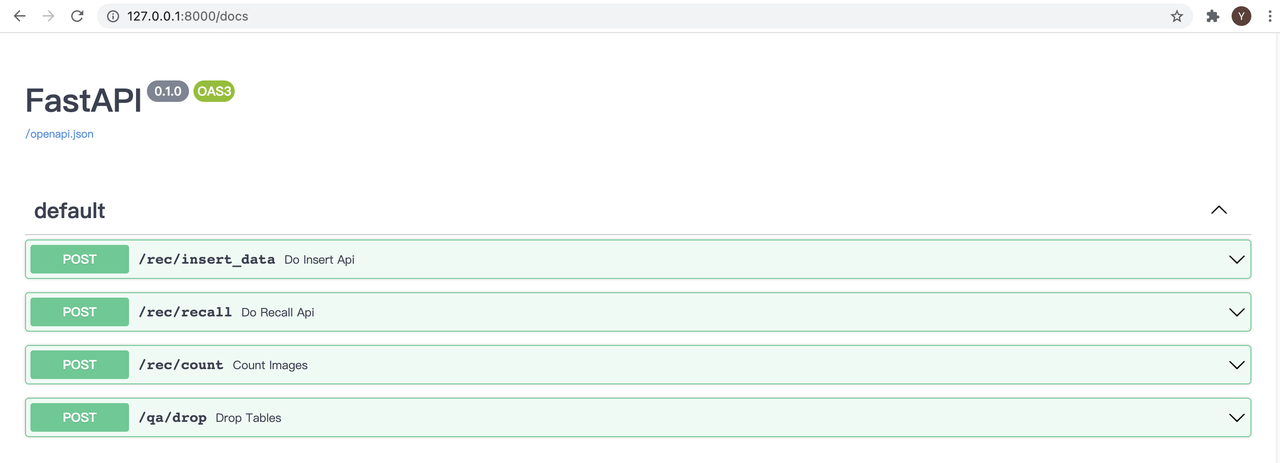 6.png
6.png
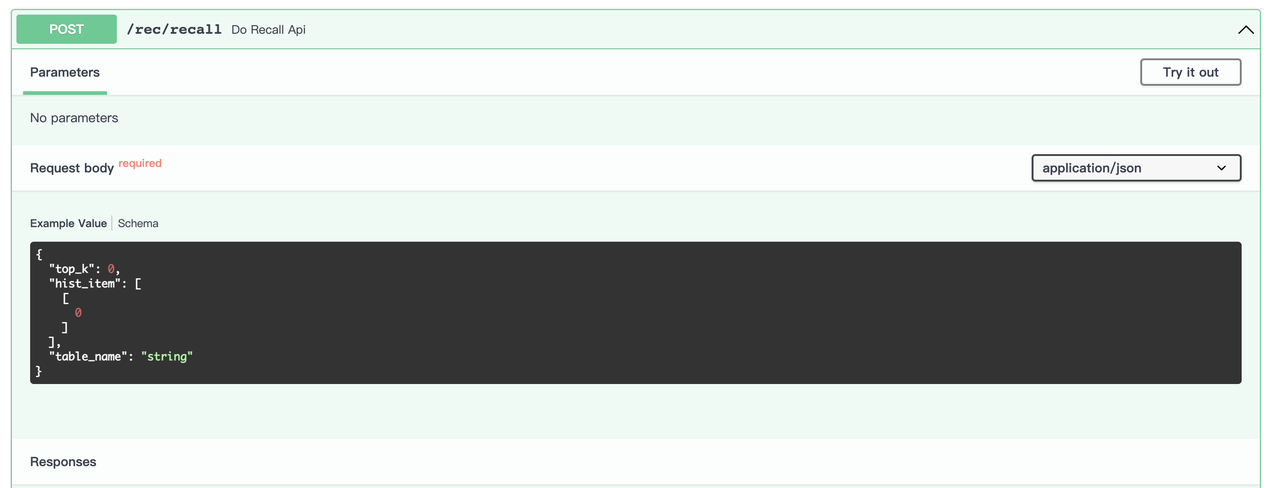 7.png
7.png
Recap
This article mainly focuses on the first stage of candidate generation in building a recommender system. It also provides a solution to accelerating this process by combining Milvus with the MIND algorithm and PaddleRec and therefore has addressed the issue proposed in the opening paragraph.
What if the system is extremely slow when returning results due to the tremendous amount of datasets? Milvus, the open-source vector database, is designed for blazing-fast similarity search on dense vector datasets containing millions, billions, or even trillions of vectors.
What if newly inserted data cannot be processed in real time for search or query? You can use Milvus as it supports unified batch and stream processing and enables you to search and query newly inserted data in real time. Also, the MIND model is capable of converting new user behavior in real-time and inserting the user vectors into Milvus instantaneously.
What if the complicated deployment is too intimidating? PaddleRec, a powerful library that belongs to the PaddlePaddle ecosystem, can provide you with an integrated solution to deploy your recommendation system or other applications in an easy and rapid way.
About the author
Yunmei Li, Zilliz Data Engineer, graduated from Huazhong University of Science and Technology with a degree in computer science. Since joining Zilliz, she has been working on exploring solutions for the open source project Milvus and helping users to apply Milvus in real-world scenarios. Her main focus is on NLP and recommendation systems, and she would like to further deepen her focus in these two areas. She likes to spend time alone and read.
Looking for more resources?
- More user cases of building a recommender system:
- Building a Personalized Product Recommender System with Vipshop with Milvus
- Building a Wardrobe and Outfit Planning App with Milvus
- Building an Intelligent News Recommendation System Inside Sohu News App
- Item-based Collaborative Filtering for Music Recommender System
- Making with Milvus: AI-Powered News Recommendation Inside Xiaomi’s Mobile Browser
- More Milvus projects in collaboration with other communities:
- Engage with our open-source community:
- The basic workflow of a recommender system
- System architecture
- MIND
- PaddleRec
- Milvus
- System implementation
- Step 1. Data processing
- Step 2. Model training
- Step 3. Model testing
- Step 4. Generating product item candidates
- Recap
- About the author
- Looking for more resources?
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



