How We Built a Semantic Highlighting Model for RAG Context Pruning and Token Saving
The Problem: RAG Noise and Token Waste
Vector search is a solid foundation for RAG systems—enterprise assistants, AI agents, customer support bots, and more. It reliably finds the documents that matter. But retrieval alone doesn’t solve the context problem. Even well-tuned indexes return chunks that are broadly relevant, while only a small fraction of the sentences inside those chunks actually answer the query.
In production systems, this gap shows up immediately. A single query may pull in dozens of documents, each thousands of tokens long. Only a handful of sentences contain the actual signal; the rest is context that bloats token usage, slows inference, and often distracts the LLM. The problem becomes even more obvious in agent workflows, where the queries themselves are the output of multi-step reasoning and only match small parts of the retrieved text.
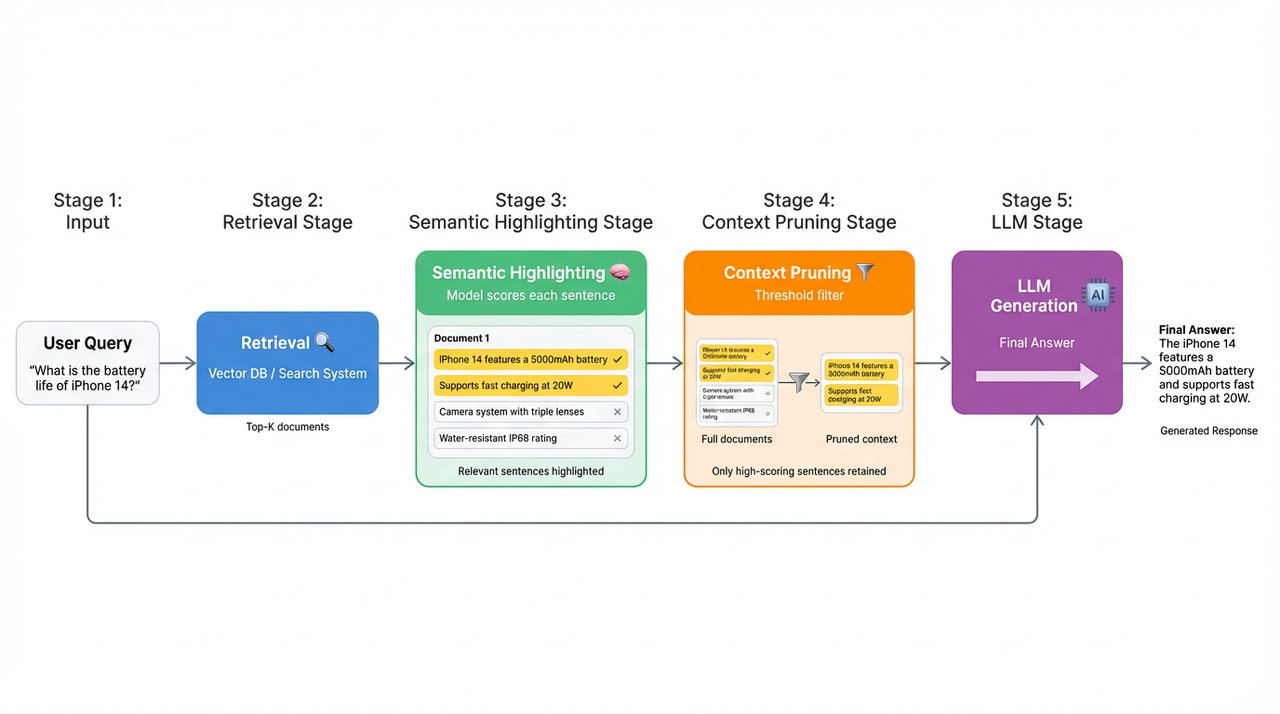
This creates a clear need for a model that can identify and highlight the useful sentences and ignore the rest—essentially, sentence-level relevance filtering, or what many teams refer to as context pruning. The goal is simple: keep the parts that matter and drop the noise before it ever reaches the LLM.
Traditional keyword-based highlighting can’t solve this problem. For example, if a user asks, “How do I improve Python code execution efficiency?”, a keyword highlighter will pick out “Python” and “efficiency,” but miss the sentence that actually answers the question—“Use NumPy vectorized operations instead of loops”—because it shares no keywords with the query. What we need instead is semantic understanding, not string matching.
A Semantic Highlighting Model for RAG Noise Filtering and Context Pruning
To make this easy for RAG builders, we trained and open-sourced a Semantic Highlighting model that identifies and highlights the sentences in retrieved documents that are more semantically aligned with the query. The model currently delivers the state-of-the-art performance on both English and Chinese and is designed to slot directly into existing RAG pipelines.
Model Details
HuggingFace: zilliz/semantic-highlight-bilingual-v1
License: MIT (commercial-friendly)
Architecture: 0.6B encoder-only model based on BGE-M3 Reranker v2
Context Window: 8192 tokens
Supported Languages: English and Chinese
Semantic Highlighting provides the relevance signals needed to select only the useful parts of long retrieved documents. In practice, this model enables:
Improved interpretability, showing which parts of a document actually matter
70–80% reduction in token cost by sending only highlighted sentences to the LLM
Better answer quality, since the model sees less irrelevant context
Easier debugging, because engineers can inspect sentence-level matches directly
Evaluation Results: Achieving SOTA Performance
We evaluated our Semantic Highlighting model across multiple datasets spanning both English and Chinese, in both in-domain and out-of-domain conditions.
The benchmark suites include:
English multi-span QA: multispanqa
English out-of-domain Wikipedia: wikitext2
Chinese multi-span QA: multispanqa_zh
Chinese out-of-domain Wikipedia: wikitext2_zh
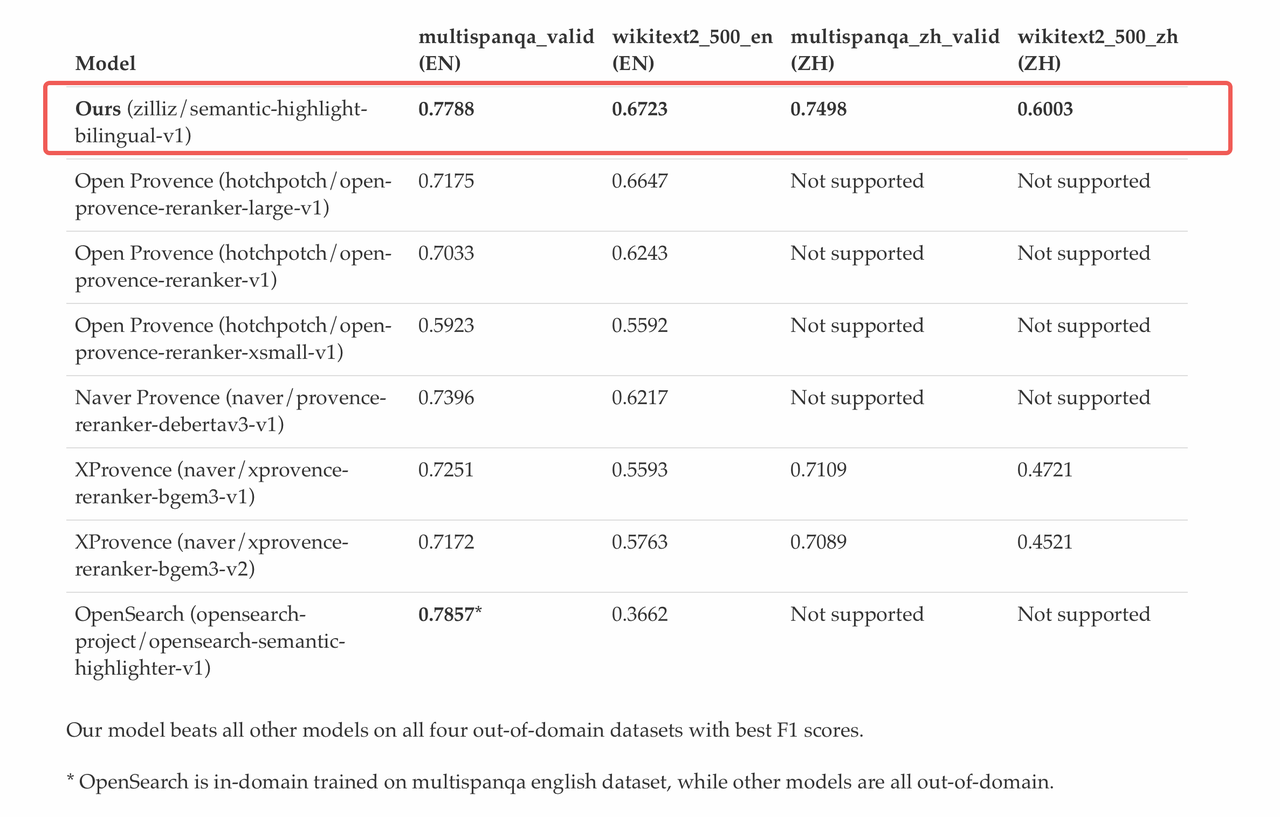
Evaluated models include:
Open Provence series
Naver’s Provence/XProvence series
OpenSearch’s semantic-highlighter
Our trained bilingual model: zilliz/semantic-highlight-bilingual-v1
Across all four datasets, our model achieves the top ranking. More importantly, it is the only model that performs consistently well on both English and Chinese. Competing models either focus exclusively on English or show clear performance drops on Chinese text.
How We Built This Semantic Highlighting Model
Training a model for this task isn’t the hard part; training a good model that handles the earlier problems and delivers near-SOTA performance is where the real work happens. Our approach focused on two things:
Model architecture: use an encoder-only design for fast inference.
Training data: generate high-quality relevance labels using reasoning-capable LLMs and scale data generation with local inference frameworks.
Model Architecture
We built the model as a lightweight encoder-only network that treats context pruning as a token-level relevance scoring task. This design is inspired by Provence, a context-pruning approach introduced by Naver at ICLR 2025, which reframes pruning from “choose the right chunk” to “score every token.” That framing aligns naturally with semantic highlighting, where fine-grained signals are essential.
Encoder-only models aren’t the newest architecture, but they remain extremely practical here: they’re fast, easy to scale, and can produce relevance scores for all token positions in parallel. For a production RAG system, that speed advantage matters far more than using a larger decoder model.
Once we compute token-level relevance scores, we aggregate them into sentence-level scores. This step turns noisy token signals into a stable, interpretable relevance metric. Sentences above a configurable threshold are highlighted; everything else is filtered out. This produces a simple and reliable mechanism for selecting the sentences that actually matter to the query.
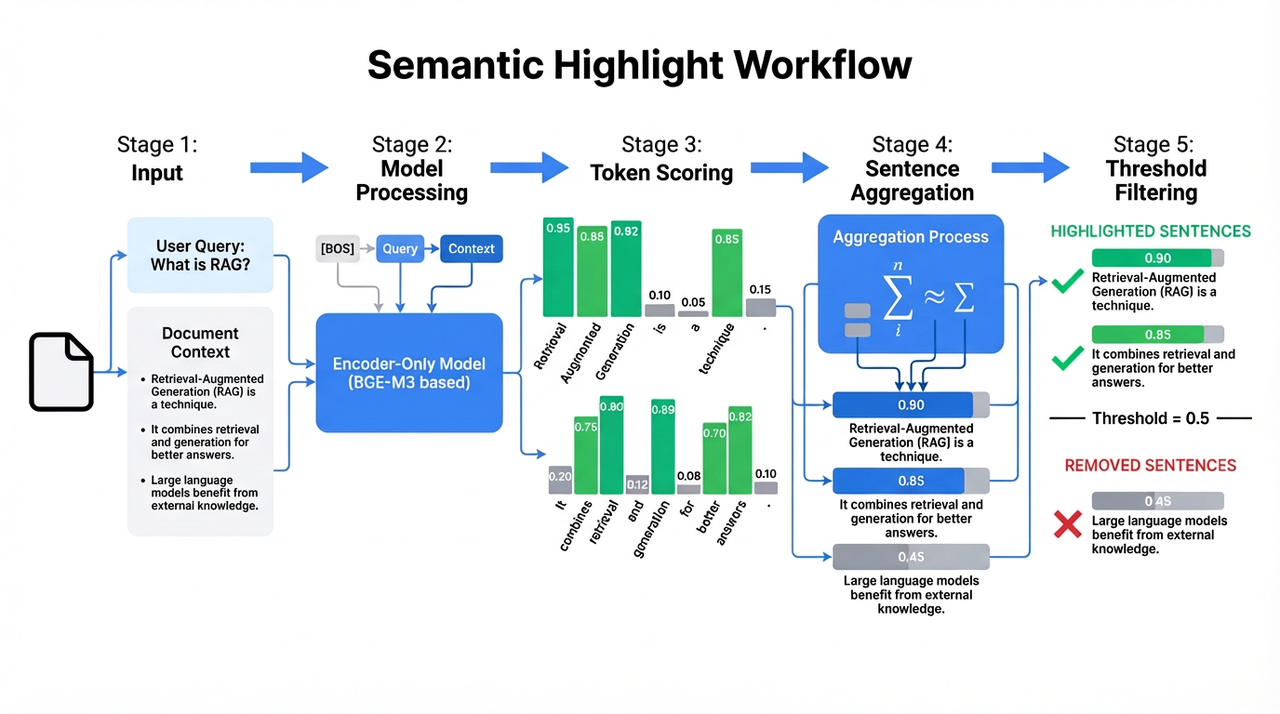
Inference Process
At runtime, our semantic highlighting model follows a simple pipeline:
Input— The process starts with a user query. Retrieved documents are treated as candidate context for relevance evaluation.
Model Processing— The query and context are concatenated into a single sequence: [BOS] + Query + Context
Token Scoring— Each token in the context is assigned a relevance score between 0 and 1, reflecting how strongly it is related to the query.
Sentence Aggregation— Token scores are aggregated at the sentence level, typically by averaging, to produce a relevance score for each sentence.
Threshold Filtering— Sentences with scores above a configurable threshold are highlighted and retained, while low-scoring sentences are filtered out before being passed to the downstream LLM.
Base Model: BGE-M3 Reranker v2
We selected BGE-M3 Reranker v2 as our base model for several reasons:
It employs an Encoder architecture suitable for token and sentence scoring
Supports multiple languages with optimization for both English and Chinese
Provides an 8192-token context window appropriate for longer RAG documents
Maintains 0.6B parameters—strong enough without being computationally heavy
Ensures sufficient world knowledge in the base model
Trained for reranking, which closely aligns with relevance judgment tasks
Training Data: LLM Annotation with Reasoning
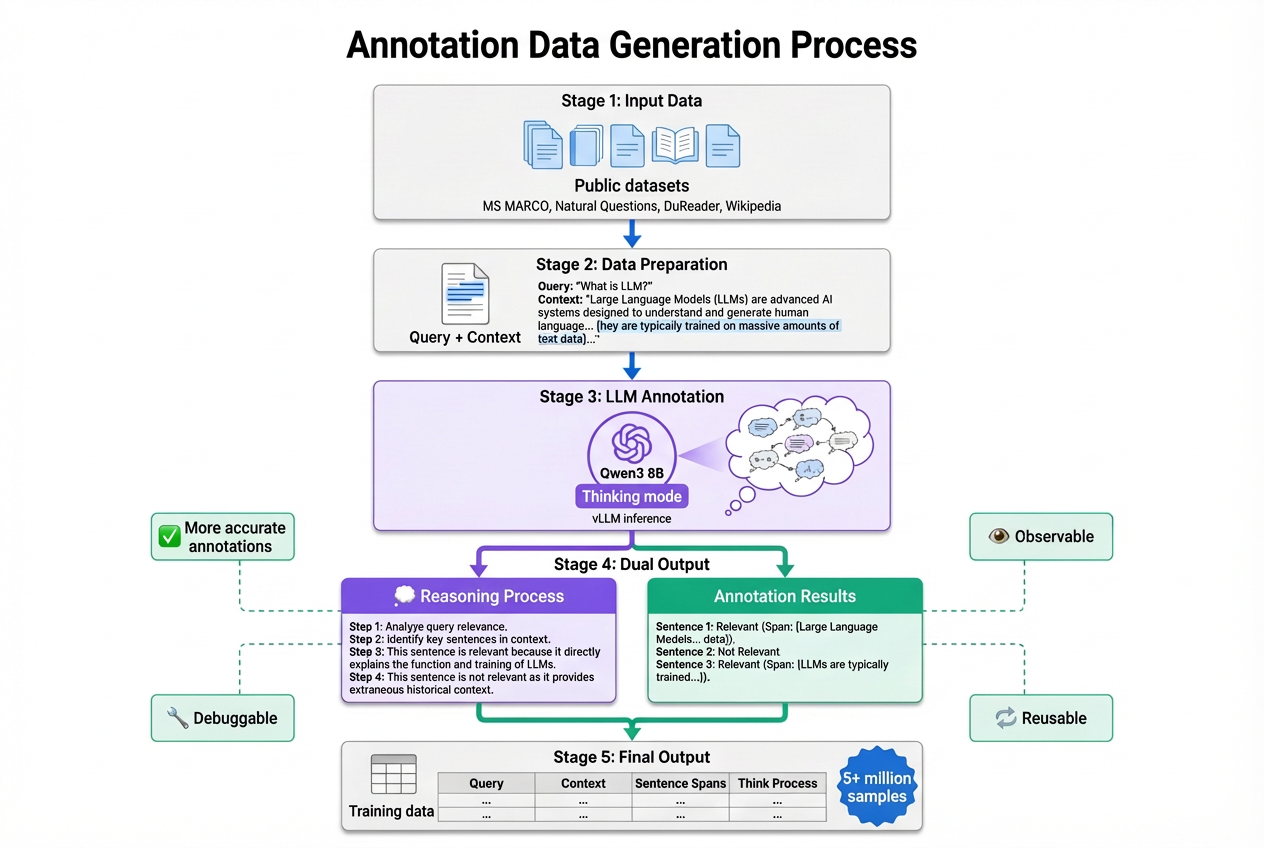
Once we finalized the model architecture, the next challenge was building a dataset that would actually train a reliable model. We started by looking at how Open Provence handles this. Their approach uses public QA datasets and a small LLM to label which sentences are relevant. It scales well and is easy to automate, which made it a good baseline for us.
But we quickly ran into the same issue they describe: if you ask an LLM to output sentence-level labels directly, the results aren’t always stable. Some labels are correct, others are questionable, and it’s hard to clean things up afterward. Fully manual annotation wasn’t an option either—we needed far more data than we could ever label by hand.
To improve stability without sacrificing scalability, we made one change: the LLM must provide a short reasoning snippet for every label it outputs. Each training example includes the query, the document, the sentence spans, and a brief explanation of why a sentence is relevant or irrelevant. This small adjustment made the annotations much more consistent and gave us something concrete to reference when validating or debugging the dataset.
Including the reasoning turned out to be surprisingly valuable:
Higher annotation quality: Writing out the reasoning works as a self-check, which reduces random or inconsistent labels.
Better observability: We can see why a sentence was selected instead of treating the label as a black box.
Easier debugging: When something looks wrong, the reasoning makes it easy to spot whether the issue is the prompt, the domain, or the annotation logic.
Reusable data: Even if we switch to a different labeling model in the future, the reasoning traces remain useful for re-labeling or auditing.
The annotation workflow looks like this:
Qwen3 8B for Annotation
For annotation, we chose Qwen3 8B because it natively supports a “thinking mode” via outputs, making it much easier to extract consistent reasoning traces. Smaller models didn’t give us stable labels, and larger models were slower and unnecessarily expensive for this kind of pipeline. Qwen3 8B hit the right balance between quality, speed, and cost.
We ran all annotations using a local vLLM service instead of cloud APIs. This gave us high throughput, predictable performance, and much lower cost—essentially trading GPU time for API token fees, which is the better deal when generating millions of samples.
Dataset Scale
In total, we built over 5 million bilingual training samples, split roughly evenly between English and Chinese.
English sources: MS MARCO, Natural Questions, GooAQ
Chinese sources: DuReader, Chinese Wikipedia, mmarco_chinese
Part of the dataset comes from re-annotating existing data used by projects like Open Provence. The rest was generated from raw corpora by first creating query–context pairs and then labeling them with our reasoning-based pipeline.
All annotated training data is also available on HuggingFace for community development and training reference: Zilliz Datasets
Training Method
Once the model architecture and dataset were ready, we trained the model on 8× A100 GPUs for three epochs, which took roughly 9 hours end-to-end.
Note: The training only targeted the Pruning Head, which is responsible for the semantic highlighting task. We did not train the Rerank Head, since focusing solely on the pruning objective yielded better results for sentence-level relevance scoring.
Real-World Case Study
Benchmarks only tell part of the story, so here’s a real example that shows how the model behaves on a common edge case: when the retrieved text contains both the correct answer and a very tempting distractor.
Query: Who wrote The Killing of a Sacred Deer?
Context (5 sentences):
1\. The Killing of a Sacred Deer is a 2017 psychological horror film directed by Yorgos Lanthimos,
with a screenplay by Lanthimos and Efthymis Filippou.
2\. The film stars Colin Farrell, Nicole Kidman, Barry Keoghan, Raffey Cassidy,
Sunny Suljic, Alicia Silverstone, and Bill Camp.
3\. The story is based on the ancient Greek playwright Euripides' play Iphigenia in Aulis.
4\. The film tells the story of a cardiac surgeon (Farrell) who secretly
befriends a teenager (Keoghan) connected to his past.
5\. He introduces the boy to his family, who then mysteriously fall ill.
Correct answer: Sentence 1 (explicitly states “screenplay by Lanthimos and Efthymis Filippou”)
This example has a trap: Sentence 3 mentions that “Euripides” wrote the original play. But the question asks “who wrote the film The Killing of a Sacred Deer,” and the answer should be the film’s screenwriters, not the Greek playwright from thousands of years ago.
Model results
| Model | Finds correct answer? | Prediction |
|---|---|---|
| Our Model | ✓ | Selected sentences 1 (correct) and 3 |
| XProvence v1 | ✗ | Only selected sentence 3, missed correct answer |
| XProvence v2 | ✗ | Only selected sentence 3, missed correct answer |
Key Sentence Score Comparison:
| Sentence | Our Model | XProvence v1 | XProvence v2 |
|---|---|---|---|
| Sentence 1 (film screenplay, correct answer) | 0.915 | 0.133 | 0.081 |
| Sentence 3 (original play, distractor) | 0.719 | 0.947 | 0.802 |
XProvence models:
Strongly attracted to “Euripides” and “play,” giving sentence 3 near-perfect scores (0.947 and 0.802)
Completely ignores the actual answer (sentence 1), giving extremely low scores (0.133 and 0.081)
Even when lowering the threshold from 0.5 to 0.2, it still can’t find the correct answer
Our model:
Correctly gives sentence 1 the highest score (0.915)
Still assigns sentence 3 some relevance (0.719) because it’s related to the background
Clearly separates the two with a ~0.2 margin
This example shows the model’s core strength: understanding query intent rather than just matching surface-level keywords. In this context, “Who wrote The Killing of a Sacred Deer” refers to the film, not the ancient Greek play. Our model picks up on that, while others get distracted by strong lexical cues.
Try It Out and Tell Us What You Think
Our zilliz/semantic-highlight-bilingual-v1 model is now fully open-sourced under the MIT license and ready for production use. You can plug it into your RAG pipeline, fine-tune it for your own domain, or build new tools on top of it. We also welcome contributions and feedback from the community.
Download from HuggingFace: zilliz/semantic-highlight-bilingual-v1
All annotated training data: https://huggingface.co/zilliz/datasets
Semantic Highlighting Available in Milvus and Zilliz Cloud
Semantic highlighting is also built directly into Milvus and Zilliz Cloud (the fully managed Milvus), giving users a clear view of why each document was retrieved. Instead of scanning entire chunks, you immediately see the specific sentences that relate to your query — even when the wording doesn’t match exactly. This makes retrieval easier to understand and much faster to debug. For RAG pipelines, it also clarifies what the downstream LLM is expected to focus on, which helps with prompt design and quality checks.
Try Semantic Highlighting in a fully managed Zilliz Cloud for free
We’d love to hear how it works for you—bug reports, improvement ideas, or anything you discover while integrating it into your workflow.
If you want to talk through anything in more detail, feel free to join our Discord channel or book a 20-minute Milvus Office Hours session. We’re always happy to chat with other builders and swap notes.
Acknowledgements
This work builds on a lot of great ideas and open-source contributions, and we want to highlight the projects that made this model possible.
Provence introduced a clean and practical framing for context pruning using lightweight encoder models.
Open Provence provided a solid, well-engineered codebase—training pipelines, data processing, and model heads—under a permissive license. It gave us a strong starting point for experimentation.
On top of that foundation, we added several contributions of our own:
Using LLM reasoning to generate higher-quality relevance labels
Creating nearly 5 million bilingual training samples aligned with real RAG workloads
Choosing a base model better suited for long-context relevance scoring (BGE-M3 Reranker v2)
Training only the Pruning Head to specialize the model for semantic highlighting
We’re grateful to the Provence and Open Provence teams for publishing their work openly. Their contributions significantly accelerated our development and made this project possible.
- The Problem: RAG Noise and Token Waste
- A Semantic Highlighting Model for RAG Noise Filtering and Context Pruning
- Evaluation Results: Achieving SOTA Performance
- How We Built This Semantic Highlighting Model
- Model Architecture
- Inference Process
- Base Model: BGE-M3 Reranker v2
- Training Data: LLM Annotation with Reasoning
- Qwen3 8B for Annotation
- Dataset Scale
- Training Method
- Real-World Case Study
- Model results
- Try It Out and Tell Us What You Think
- Semantic Highlighting Available in Milvus and Zilliz Cloud
- Acknowledgements
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



