How to Add Long-Term Memory to Anthropic's Managed Agents with Milvus
Anthropic’s Managed Agents make agent infrastructure resilient. A 200-step task now survives a harness crash, a sandbox timeout, or a mid-flight infrastructure change without human intervention, and Anthropic reports p50 time-to-first-token dropped roughly 60% and p95 dropped over 90% after the decoupling.
What reliability doesn’t solve is memory. A 200-step code migration that hits a new dependency conflict on step 201 can’t efficiently look back at how it handled the last one. An agent running vulnerability scans for one customer has no idea that another agent already solved the same case an hour ago. Every session starts on a blank page, and parallel brains have no access to what the others have already worked out.
The fix is to pair the Milvus vector database with Anthropic’s Managed Agents: semantic recall within a session, and a shared vector memory layer across sessions. The session contract stays untouched, the harness gets one new layer, and long-horizon agent tasks get qualitatively different capabilities.
What Managed Agents Solved (and What They Didn’t)
Managed Agents solved reliability by decoupling the agent into three independent modules. What it didn’t solve is memory, either as semantic recall inside a single session or as shared experience across parallel sessions. Here’s what got decoupled, and where the memory gap sits inside that decoupled design.
| Module | What it does |
|---|---|
| Session | An append-only event log of everything that happened. Stored outside the harness. |
| Harness | The loop that calls Claude and routes Claude’s tool calls to the relevant infrastructure. |
| Sandbox | The isolated execution environment where Claude runs code and edits files. |
The reframe that makes this design work is stated explicitly in Anthropic’s post:
“The session is not Claude’s context window.”
The context window is ephemeral: bounded in tokens, reconstructed per model call, and discarded when the call returns. The session is durable, stored outside the harness, and represents the system of record for the entire task.
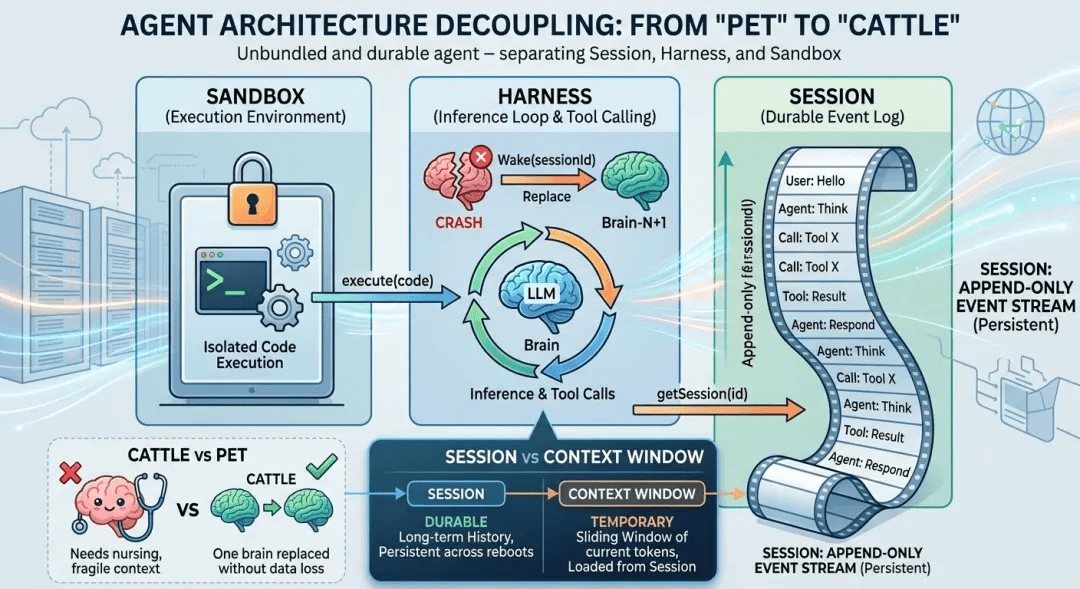
When a harness crashes, the platform starts a fresh one with wake(sessionId). The new harness reads the event log via getSession(id), and the task picks up from the last recorded step, with no custom recovery logic to write and no session-level babysitting to operate.
What the Managed Agents post doesn’t address, and doesn’t claim to, is what the agent does when it needs to remember anything. Two gaps show up the moment you push real workloads through the architecture. One lives inside a single session; the other lives across sessions.
Problem 1: Why Linear Session Logs Fail Past a Few Hundred Steps
Linear session logs fail past a few hundred steps because sequential reads and semantic search are fundamentally different workloads, and the **getEvents()** API serves only the first one. Slicing by position or seeking to a timestamp is enough to answer “where did this session leave off.” It is not enough to answer the question an agent will predictably need on any long task: have we seen this kind of problem before, and what did we do about it?
Consider a code migration at step 200 that hits a new dependency conflict. The natural move is to look back. Did the agent run into something similar earlier in this same task? What approach was tried? Did it hold, or did it regress something else downstream?
With getEvents() there are two ways to answer that, and both are bad:
| Option | Problem |
|---|---|
| Scan every event sequentially | Slow at 200 steps. Untenable at 2,000. |
| Dump a large slice of the stream into the context window | Expensive on tokens, unreliable at scale, and crowds out the agent’s actual working memory for the current step. |
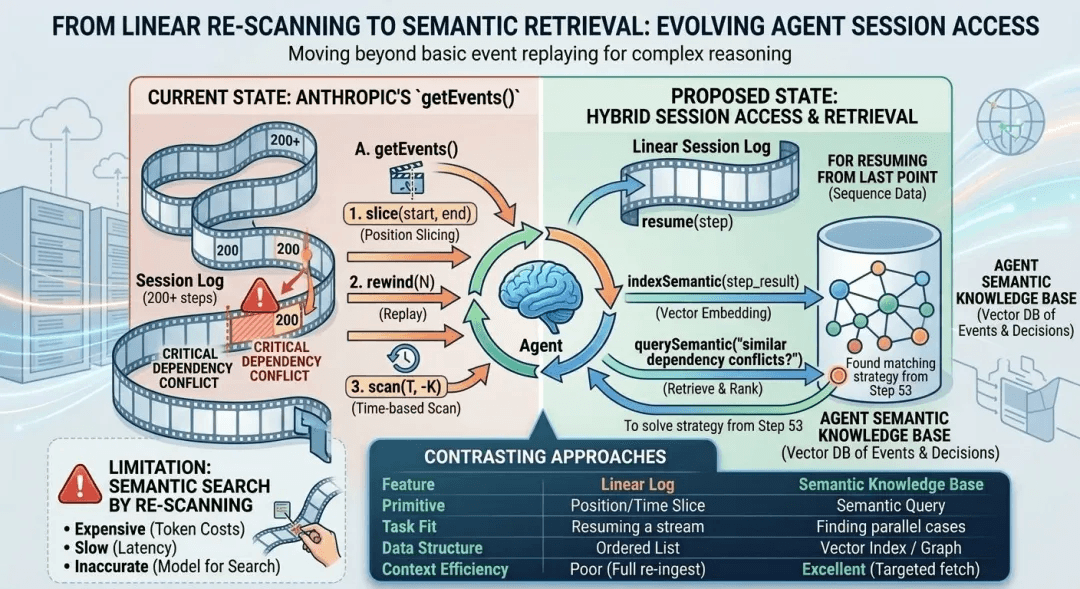
The session is good for recovery and audit, but it was not built with an index that supports “have I seen this before.” Long-horizon tasks are where that question stops being optional.
Solution 1: How to Add Semantic Memory to a Managed Agent’s Session
Add a Milvus collection alongside the session log and dual-write from **emitEvent**. The session contract stays untouched, and the harness gains semantic query over its own past.
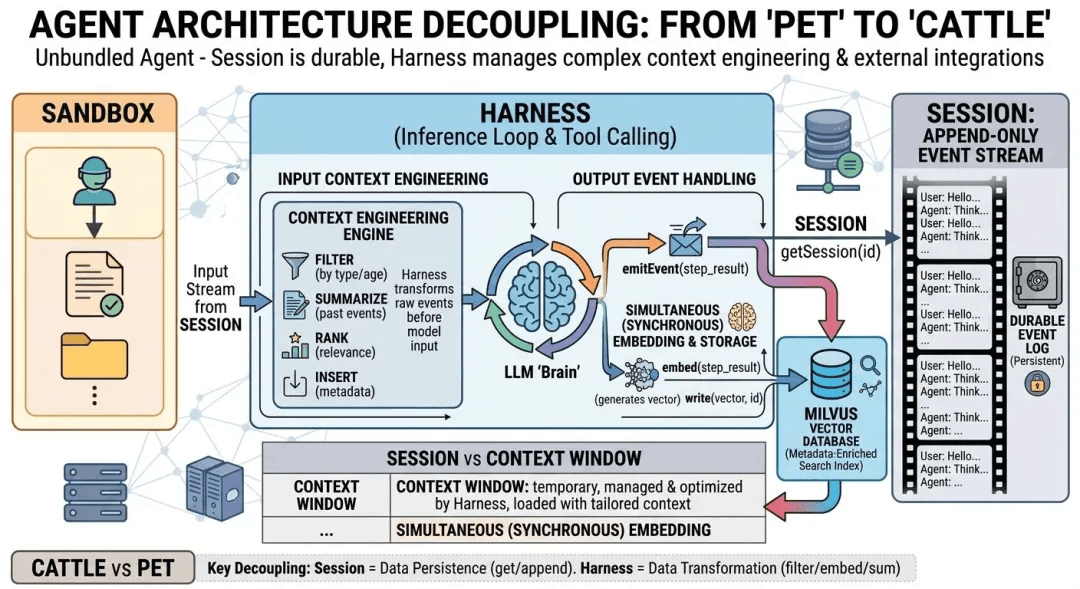
Anthropic’s design leaves headroom for exactly this. Their post states that “any fetched events can also be transformed in the harness before being passed to Claude’s context window. These transformations can be whatever the harness encodes, including context organization… and context engineering.” Context engineering lives in the harness; the session only has to guarantee durability and queryability.
The pattern: every time emitEvent fires, the harness also computes a vector embedding for events worth indexing and inserts them into a Milvus collection.
from pymilvus import MilvusClient
milvus_client = MilvusClient(uri="http://localhost:19530")
# Only index high-signal events. Tool retries and intermediate states are noise.
INDEXABLE_EVENT_TYPES = {"decision", "strategy", "resolution", "error_handling"}
async def emit_event(session_id: str, event: dict):
# Original path: append to the session event stream.
await session_store.append(session_id, event)
# Extended path: embed the event content and insert into Milvus.
if event["type"] in INDEXABLE_EVENT_TYPES:
embedding = await embed(event["content"])
milvus_client.insert(
collection_name="agent_memory",
data=[{
"vector": embedding,
"session_id": session_id,
"step": event["step"],
"event_type": event["type"],
"content": event["content"],
}]
)
When the agent hits step 200 and needs to recall prior decisions, the query is a vector search scoped to that session:
async def recall_similar(query: str, session_id: str, top_k: int = 5):
query_vector = await embed(query)
results = milvus_client.search(
collection_name="agent_memory",
data=[query_vector],
filter=f'session_id == "{session_id}"',
limit=top_k,
output_fields=["step", "event_type", "content"]
)
return results[0] # top_k most relevant past events
Three production details matter before this ships:
- Pick what to index. Not every event deserves an embedding. Tool-call intermediate states, retry logs, and repetitive status events pollute retrieval quality faster than they improve it. The
INDEXABLE_EVENT_TYPESpolicy is task-dependent, not global. - Define the consistency boundary. If the harness crashes between the session append and the Milvus insert, one layer is briefly ahead of the other. The window is small but real. Pick a reconciliation path (retry on restart, write-ahead log, or eventual reconciliation) rather than hoping.
- Control embedding spend. A 200-step session that calls an external embedding API synchronously on every step produces an invoice nobody planned for. Queue embeddings and send them asynchronously in batches.
With those in place, recall takes milliseconds for the vector search plus under 100ms for the embedding call. The top-five most relevant past events land in context before the agent notices friction. The session keeps its original job as the durable log; the harness gains the ability to query its own past semantically rather than sequentially. That’s a modest change at the API surface and a structural change in what the agent can do on long-horizon tasks.
Problem 2: Why Parallel Claude Agents Can’t Share Experience
Parallel Claude agents can’t share experience because Managed Agents sessions are isolated by design. The same isolation that makes horizontal scaling clean also prevents every brain from learning from every other brain.
In a decoupled harness, brains are stateless and independent. That isolation unlocks the latency wins Anthropic reports, and it also keeps every session running in the dark about every other session.
Agent A spends 40 minutes diagnosing a tricky SQL injection vector for one customer. An hour later, Agent B picks up the same case for a different customer and spends its own 40 minutes walking the same dead ends, running the same tool calls, and arriving at the same answer.
For a single user running the occasional agent, that is wasted compute. For a platform running dozens of concurrent AI agents across code review, vulnerability scans, and documentation generation for different customers every day, the cost compounds structurally.
If the experience every session produces evaporates the moment the session ends, the intelligence is disposable. A platform built this way scales linearly but doesn’t get better at anything over time, the way human engineers do.
Solution 2: How to Build a Shared Agent Memory Pool with Milvus
Build one vector collection that every harness reads from at startup and writes to at shutdown, partitioned by tenant so experience pools across sessions without leaking across customers.
When a session ends, the key decisions, problems encountered, and approaches that worked are pushed into the shared Milvus collection. When a new brain initializes, the harness runs a semantic query as part of setup and injects the top-matching past experiences into the context window. Step one of the new agent inherits the lessons of every prior agent.
Two engineering decisions carry this from prototype to production.
Isolating Tenants with the Milvus Partition Key
Partition by **tenant_id**, and Customer A’s agent experiences physically don’t live in the same partition as Customer B’s. That’s isolation at the data layer rather than a query convention.
Brain A’s work on Company A’s codebase should never be retrievable by Company B’s agents. Milvus’s partition key handles this on a single collection, with no second collection per tenant and no sharding logic in application code.
# Declare partition key at schema creation.
schema.add_field(
field_name="tenant_id",
datatype=DataType.VARCHAR,
max_length=64,
is_partition_key=True # Automatic per-tenant partitioning.
)
# Every query filters by tenant. Isolation is automatic.
results = milvus_client.search(
collection_name="shared_agent_memory",
data=[query_vector],
filter=f'tenant_id == "{current_tenant}"',
limit=5,
output_fields=["content", "step", "session_id"]
)
Customer A’s agent experiences never surface in Customer B’s queries, not because the query filter is written correctly (though it has to be), but because the data physically does not live in the same partition as Customer B’s. One collection to operate, logical isolation enforced at the query layer, physical isolation enforced at the partition layer.
See the multi-tenancy strategies docs for when partition key fits versus when separate collections or databases do, and the multi-tenancy RAG patterns guide for production deployment notes.
Why Agent Memory Quality Needs Ongoing Work
Memory quality erodes over time: flawed workarounds that happened to succeed once get replayed and reinforced, and stale entries tied to deprecated dependencies keep misleading agents that inherit them. The defenses are operational programs, not database features.
An agent stumbles on a flawed workaround that happens to succeed once. It gets written to the shared pool. The next agent retrieves it, replays it, and reinforces the bad pattern with a second “successful” usage record.
Stale entries follow a slower version of the same path. A fix pinned to a dependency version that was deprecated six months ago keeps getting retrieved, and keeps misleading agents that inherit it. The older and more heavily used the pool, the more of this accumulates.
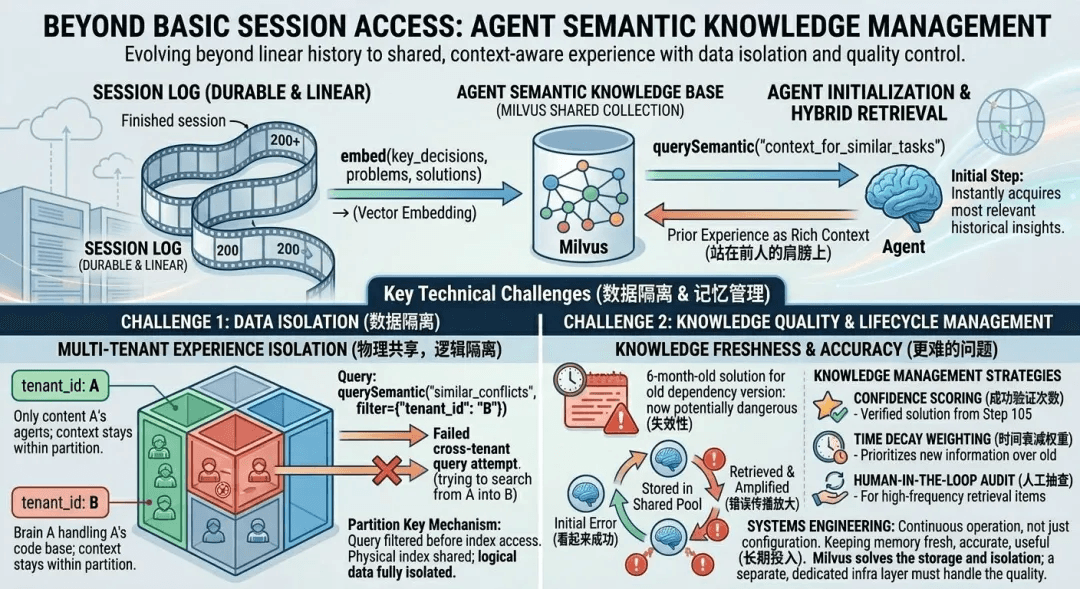
Three operational programs defend against this:
- Confidence score. Track how often a memory has been successfully applied in downstream sessions. Decay entries that fail in replay. Promote entries that succeed repeatedly.
- Time weighting. Prefer recent experiences. Retire entries past a known staleness threshold, often tied to major dependency version bumps.
- Human spot checks. Entries with high retrieval frequency are high-leverage. When one of them is wrong, it is wrong many times, which is where human review pays back fastest.
Milvus alone doesn’t solve this, and neither does Mem0, Zep, or any other memory product. Enforcing one pool with many tenants and zero cross-tenant leakage is something you engineer once. Keeping that pool accurate, fresh, and useful is continuous operational work that no database ships pre-configured.
Takeaways: What Milvus Adds to Anthropic’s Managed Agents
Milvus turns Managed Agents from a reliable-but-forgetful platform into one that compounds experience over time by adding semantic recall inside a session and shared memory across agents.
Managed Agents answered the reliability question cleanly: both brains and hands are cattle, and any one can die without taking the task with it. That’s the infrastructure problem, and Anthropic solved it well.
What stayed open was growth. Human engineers compound over time; years of work turn into pattern recognition, and they don’t reason from first principles on every task. Today’s managed agents don’t, because every session starts on a blank page.
Wiring the session to Milvus for semantic recall inside a task and pooling experience across brains in a shared vector collection is what gives agents a past they can actually use. Plugging in Milvus is the infrastructure piece; pruning wrong memories, retiring stale ones, and enforcing tenant boundaries is the operational piece. Once both are in place, the shape of memory stops being a liability and starts being compounding capital.
Get Started
- Try it locally: spin up an embedded Milvus instance with Milvus Lite. No Docker, no cluster, just
pip install pymilvus. Production workloads graduate to Milvus Standalone or Distributed when you need them. - Read the design rationale: Anthropic’s Managed Agents engineering post walks through the session, harness, and sandbox decoupling in depth.
- Got questions? Join the Milvus Discord community for agent memory design discussions, or book a Milvus Office Hours session to walk through your workload.
- Prefer managed? Sign up for Zilliz Cloud (or sign in) for hosted Milvus with partition keys, scaling, and multi-tenancy built in. New accounts get free credits on a work email.
Frequently Asked Questions
Q: What’s the difference between a session and a context window in Anthropic’s Managed Agents?
The context window is the ephemeral set of tokens a single Claude call sees. It’s bounded and resets per model invocation. The session is the durable, append-only event log of everything that happened across the whole task, stored outside the harness. When a harness crashes, wake(sessionId) spawns a new harness that reads the session log and resumes. The session is the system of record; the context window is working memory. The session is not the context window.
Q: How do I persist agent memory across Claude sessions?
The session itself is already persistent; that’s what getSession(id) retrieves. What’s typically missing is queryable long-term memory. The pattern is to embed high-signal events (decisions, resolutions, strategies) into a vector database like Milvus during emitEvent, then query by semantic similarity at retrieval time. This gives you both the durable session log Anthropic provides and a semantic recall layer for looking back across hundreds of steps.
Q: Can multiple Claude agents share memory?
Not out of the box. Each Managed Agents session is isolated by design, which is what lets them scale horizontally. To share memory across agents, add a shared vector collection (for example in Milvus) that each harness reads from at startup and writes to at shutdown. Use Milvus’s partition key feature to isolate tenants so Customer A’s agent memories never leak into Customer B’s sessions.
Q: What’s the best vector database for AI agent memory?
The honest answer depends on scale and deployment shape. For prototypes and small workloads, a local embedded option like Milvus Lite runs in-process with no infrastructure. For production agents across many tenants, you want a database with mature multi-tenancy (partition keys, filtered search), hybrid search (vector + scalar + keyword), and millisecond-latency at millions of vectors. Milvus is purpose-built for vector workloads at that scale, which is why it appears in production agent memory systems built on LangChain, Google ADK, Deep Agents, and OpenAgents.
- What Managed Agents Solved (and What They Didn't)
- Problem 1: Why Linear Session Logs Fail Past a Few Hundred Steps
- Solution 1: How to Add Semantic Memory to a Managed Agent's Session
- Problem 2: Why Parallel Claude Agents Can't Share Experience
- Solution 2: How to Build a Shared Agent Memory Pool with Milvus
- Takeaways: What Milvus Adds to Anthropic's Managed Agents
- Get Started
- Frequently Asked Questions
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



