Accelerating Compilation 2.5X with Dependency Decoupling & Testing Containerization
Compile time can be compounded by complex internal and external dependencies that evolve throughout the development process, as well as changes in compilation environments such as the operating system or hardware architectures. Following are common issues one may encounter when working on large-scale AI or MLOps projects:
Prohibitively long compilation - Code integration is done hundreds of times each day. With hundreds of thousands of lines of code in place, even a small change could result in a full compilation that typically takes one or more hours.
Complex compilation environment - The project code needs to be compiled under different environments, which involve different operating systems, such as CentOS and Ubuntu, underlying dependencies, such as GCC, LLVM, and CUDA, and hardware architectures. And compilation under a specific environment normally may not work under a different environment.
Complex dependencies - Project compilation involves more than 30 between-component and third-party dependencies. Project development often leads to changes in dependencies, inevitably causing dependency conflicts. The version control between dependencies is so complex that updating version of dependencies will easily affect other components.
Third-party dependency download is slow or fails - Network delays or unstable third-party dependency libraries cause slow resource downloads or access failures, seriously affecting code integration.
By decoupling dependencies and implementing testing containerization, we managed to decrease average compile time by 60% while working on the open-source embeddings similarity search project Milvus.
Decouple the dependencies of the project
Project compilation usually involves a large number of internal and external component dependencies. The more dependencies a project has, the more complex it becomes to manage them. As software grows, it becomes more difficult and costly to change or remove dependencies, as well as identify the effects of doing so. Regular maintenance is required throughout the development process to ensure the dependencies functions properly. Poor maintenance, complex dependencies, or faulty dependencies can cause conflicts that slow or stall development. In practice, this can mean lagging resource downloads, access failures that negatively impact code integration, and more. Decoupling project dependencies can mitigate defects and reduce compile time, accelerating system testing and avoiding unnecessary drag on software development.
Therefore, we recommend decouple dependencies your project:
- Split up components with complex dependencies
- Use different repositories for version management.
- Use configuration files to manage version information, compilation options, dependencies, etc.
- Add the configuration files to the component libraries so that they are updated as the project iterates.
Compile optimization between components — Pull and compile the relevant component according to the dependencies and the compile options recorded in the configuration files. Tag and pack the binary compilation results and the corresponding manifest files, and then upload them to your private repository. If no change is made to a component or the components it depends on, playback its compilation results according to the manifest files. For issues such as network delays or unstable third-party dependency libraries, try setting up an internal repository or using mirrored repositories.
To optimize compilation between components:
1.Create dependency relationship graph — Use the configuration files in the component libraries to create dependency relationship graph. Use the dependency relationship to retrieve the version information (Git Branch, Tag, and Git commit ID) and compilation options and more of both upstream and downstream dependent components.
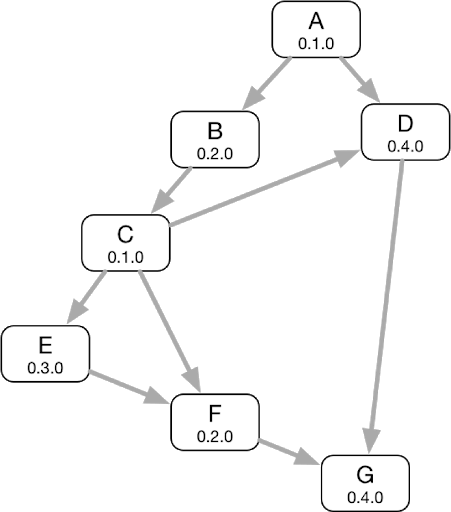 1.png
1.png
2.Check for dependencies — Generate alerts for circular dependencies, version conflicts, and other issues that arise between components.
3.Flatten dependencies — Sort dependencies by Depth First Search (DFS) and front-merge components with duplicate dependencies to form a dependency graph.
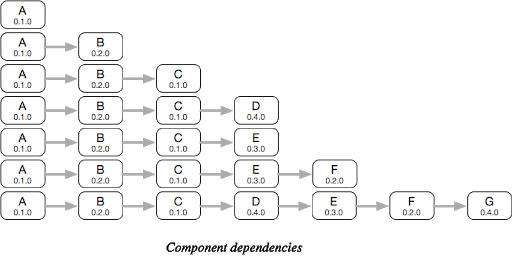 2.png
2.png
4.Use MerkleTree algorithm to generate a hash (Root Hash) containing dependencies of each component based on version information, compilation options, and more. Combined with information such as component name, the algorithm forms a unique tag for each component.
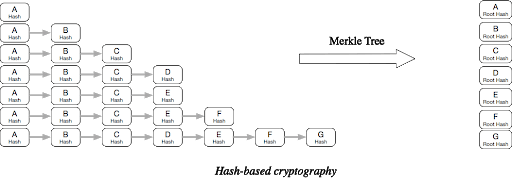 3.png
3.png
5.Based on the component’s unique tag information, check if a corresponding compilation archive exists in the private repo. If a compilation archive is retrieved, unzip it to get the manifest file for playback; if not, compile the component, mark up the generated compilation object files and manifest file, and upload them to the private repo.
Implement compilation optimizations within components — Choose a language-specific compilation cache tool to cache the compiled object files, and upload and store them in your private repository. For C/C++ compilation, choose a compilation cache tool like CCache to cache the C/C++ compilation intermediate files, and then archive the local CCache cache after compilation. Such compile cache tools simply cache the changed code files one by one after compilation, and copy the compiled components of the unchanged code file so that they can be directly involved in the final compilation. Optimization of the compilation within components includes the following steps:
- Add the necessary compilation dependencies to Dockerfile. Use Hadolint to perform compliance checks on Dockerfile to ensure that the image conforms to Docker’s best practices.
- Mirror the compilation environment according to the project sprint version (version + build), operating system, and other information.
- Run the mirrored compilation environment container, and transfer the image ID to the container as an environment variable. Here’s an example command for getting image ID: “docker inspect ‘ — type=image’ — format ‘{{.ID}}’ repository/build-env:v0.1-centos7”.
- Choose the appropriate compile cache tool: Enter your containter to integrate and compile your codes and check in your private repository if an appropriate compile cache exists. If yes, download and extract it to the specified directory. After all components are compiled, the cache generated by the compile cache tool is packaged and uploaded to your private repository based on the project version and image ID.
Further compilation optimization
Our initially-built occupies too much disk space and network bandwidth, and takes a long time to deploy, we took the following measures:
- Choose the leanest base image to reduce the image size, e.g. alpine, busybox, etc.
- Reduce the number of image layers. Reuse dependencies as much as possible. Merge multiple commands with “&&”.
- Clean up the intermediate products during image building.
- Use image cache to build image as much as possible.
As our project continues to progress, disk usage and network resource began to soar as the compilation cache increases, while some of the compilation caches are underutilized. We then made the following adjustments:
Regularly clean up cache files — Regularly check the private repository (using scripts for example), and clean up cache files that have not changed for a while or have not been downloaded much.
Selective compile caching — Only cache resource-demanding compiles, and skip caching compiles that do not require much resource.
Leveraging containerized testing to reduce errors, improve stability and reliability
Codes have to be compiled in different environments, which involve variety of operating systems (e.g. CentOS and Ubuntu), underlying dependencies (e.g. GCC, LLVM, and CUDA), and specific hardware architectures. Code that successfully compiles under a specific environment fail in a different environment. By running tests inside containers, the testing process becomes faster and more accurate.
Containerization ensures that the test environment is consistent, and that an application is working as expected. The containerized testing approach packages tests as image containers and builds a truly-isolated test environment. Our testers found that this approach pretty useful, which ended up reducing compile times by as much as 60%.
Ensure a consistent compile environment — As the compiled products are sensitive to changes in the system environment, unknown errors may occur in different operating systems. We have to tag and archive the compiled product cache according to the changes in the compile environment, but they are difficult to categorize. So we introduced containerization technology to unify the compile environment to solve such issues.
Conclusion
By analyzing project dependencies, this article introduces different methods for compilation optimization between and within components, providing ideas and best practices for building stable and efficient continuous code integration. These methods helped solve slow code integration caused by complex dependencies, unify operations inside the container to ensure the consistency of the environment, and improve compilation efficiency through the playback of the compilation results and the use of compilation cache tools to cache the intermediate compilation results.
This above-mentioned practices have reduced the compile time of the project by 60% on average, greatly improving the overall efficiency of code integration. Moving forward, we will continue parallelizing compilation between and within components to further reduce compilation times.
The following sources were used for this article:
- “Decoupling Source Trees into Build-Level Components”
- “Factors to consider when adding third party dependencies to a project”
- “Surviving Software Dependencies”
- “Understanding Dependencies: A Study of the Coordination Challenges in Software Development”
About the author
Zhifeng Zhang is a senior DevOps engineer at Zilliz.com working on Milvus, an open-source vector database, and authorized instructor of the LF open-source software university in China. He received his bachelor’s degree in Internet of Things (IOT) from Software Engineering Institute of Guangzhou. He spends his career participating in and leading projects in the area of CI/CD, DevOps, IT infrastructure management, Cloud-Native toolkit, containerization, and compilation process optimization.
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



