Elasticsearch is Dead, Long Live Lexical Search
By now, everyone knows that hybrid search has improved RAG (Retrieval-Augmented Generation) search quality. While dense embedding search has shown impressive capabilities in capturing deep semantic relationships between queries and documents, it still has notable limitations. These include a lack of explainability and suboptimal performance with long-tail queries and rare terms.
Many RAG applications struggle because pre-trained models often lack domain-specific knowledge. In some scenarios, simple BM25 keyword matching outperforms these sophisticated models. This is where hybrid search bridges the gap, combining the semantic understanding of dense vector retrieval with the precision of keyword matching.
Why Hybrid Search is Complex in Production
While frameworks like LangChain or LlamaIndex make building a proof-of-concept hybrid retriever easy, scaling to production with massive datasets is challenging. Traditional architectures require separate vector databases and search engines, leading to several key challenges:
High infrastructure maintenance costs and operational complexity
Data redundancy across multiple systems
Difficult data consistency management
Complex security and access control across systems
The market needs a unified solution that supports lexical and semantic search while reducing system complexity and cost.
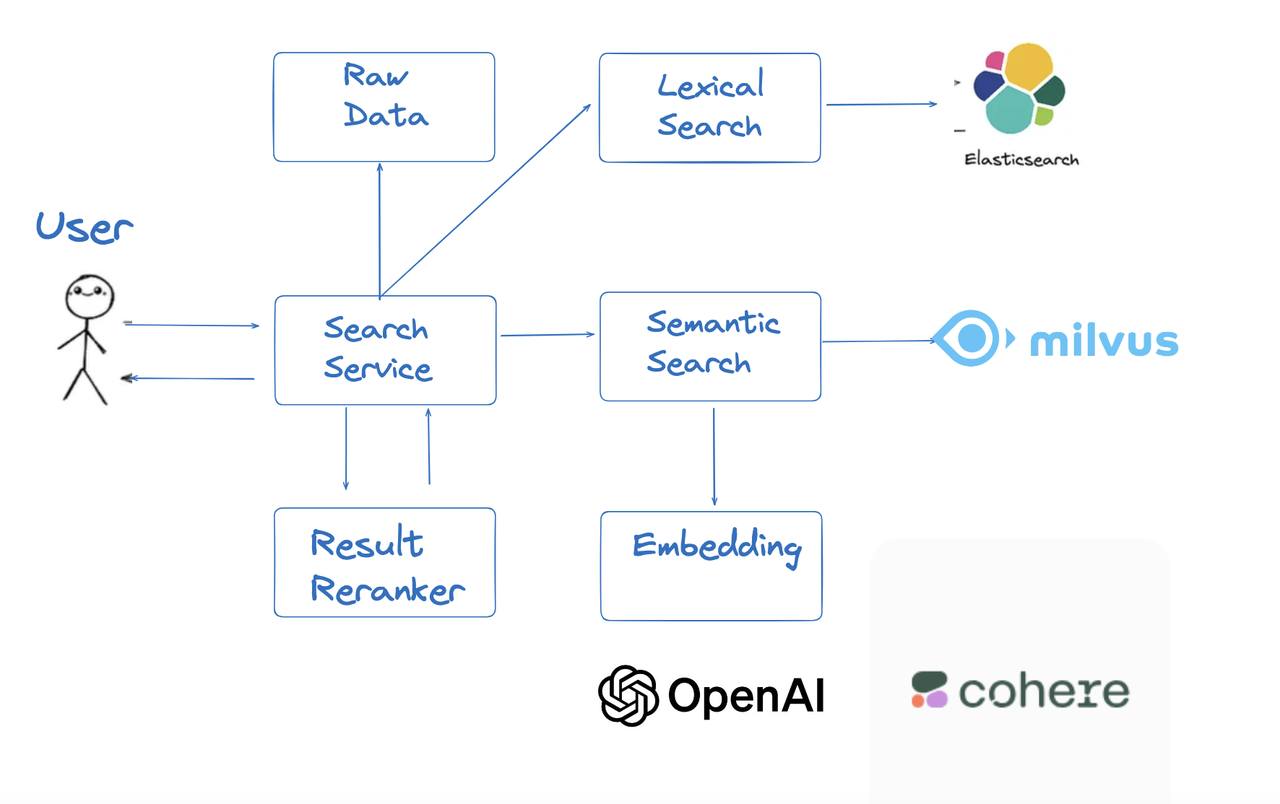
The Pain Points of Elasticsearch
Elasticsearch has been one of the past decade’s most influential open-source search projects. Built on Apache Lucene, it gained popularity through its high performance, scalability, and distributed architecture. While it added vector ANN search in version 8.0, production deployments face several critical challenges:
High Update and Indexing Costs: Elasticsearch’s architecture doesn’t fully decouple write operations, index building, and querying. This leads to significant CPU and I/O overhead during write operations, especially in bulk updates. The resource contention between indexing and querying impacts performance, creating a major bottleneck for high-frequency update scenarios.
Poor Real-time Performance: As a “near real-time” search engine, Elasticsearch introduces noticeable latency in data visibility. This latency becomes particularly problematic for AI applications, such as Agent systems, where high-frequency interactions and dynamic decision-making require immediate data access.
Difficult Shard Management: While Elasticsearch uses sharding for distributed architecture, shard management poses significant challenges. The lack of dynamic sharding support creates a dilemma: too many shards in small datasets lead to poor performance, while too few shards in large datasets limit scalability and cause uneven data distribution.
Non-Cloud-Native Architecture: Developed before cloud-native architectures became prevalent, Elasticsearch’s design tightly couples storage and compute, limiting its integration with modern infrastructure like public clouds and Kubernetes. Resource scaling requires simultaneous increases in both storage and compute, reducing flexibility. In multi-replica scenarios, each shard must build its index independently, increasing computational costs and reducing resource efficiency.
Poor Vector Search Performance: Though Elasticsearch 8.0 introduced vector ANN search, its performance significantly lags behind that of dedicated vector engines like Milvus. Based on the Lucene kernel, its index structure proves inefficient for high-dimensional data, struggling with large-scale vector search requirements. Performance becomes particularly unstable in complex scenarios involving scalar filtering and multi-tenancy, making it challenging to support high-load or diverse business needs.
Excessive Resource Consumption: Elasticsearch places extreme demands on memory and CPU, especially when processing large-scale data. Its JVM dependency requires frequent heap size adjustments and garbage collection tuning, severely impacting memory efficiency. Vector search operations require intensive SIMD-optimized computations, for which the JVM environment is far from ideal.
These fundamental limitations become increasingly problematic as organizations scale their AI infrastructure, making Elasticsearch particularly challenging for modern AI applications requiring high performance and reliability.
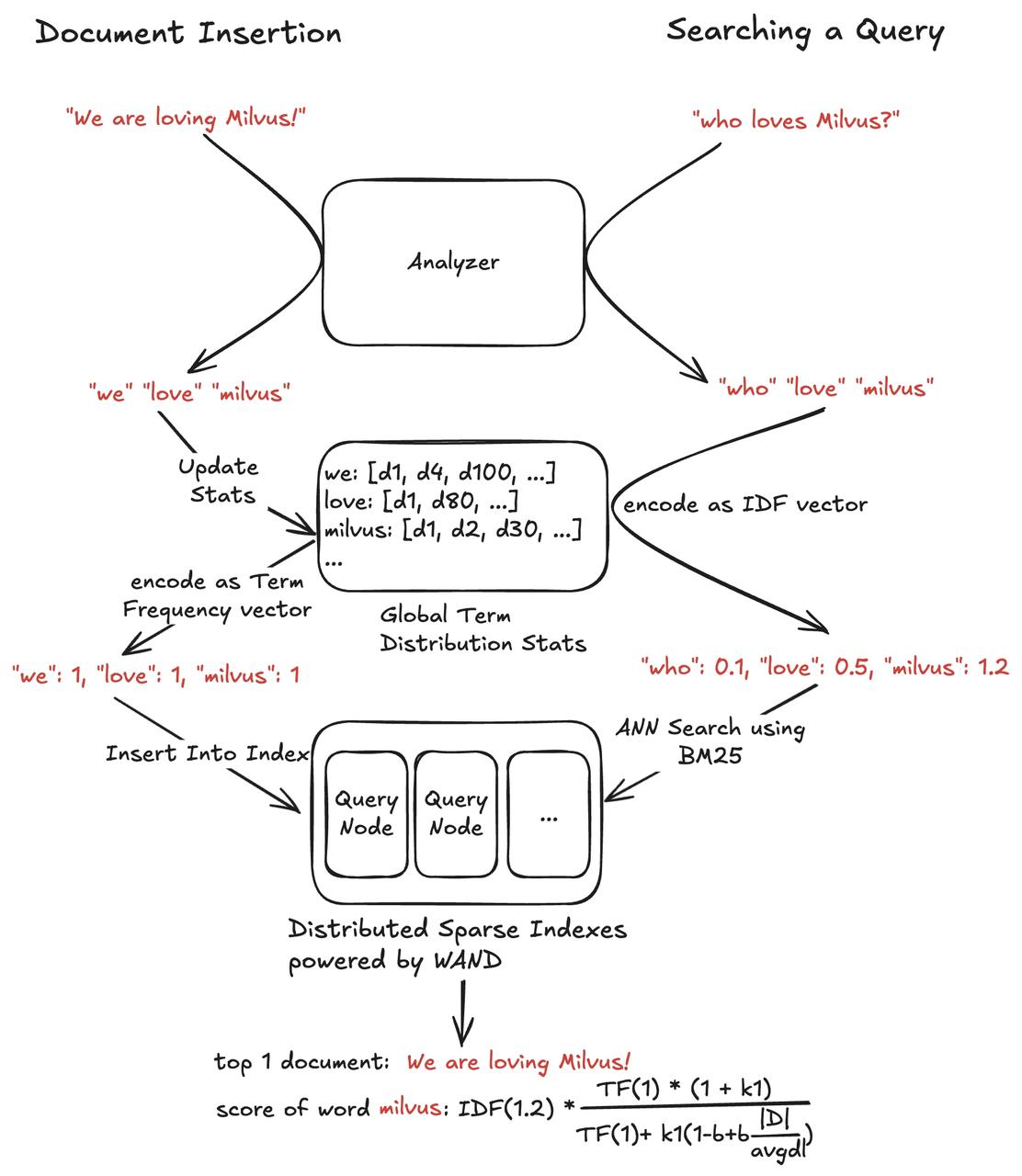
Introducing Sparse-BM25: Reimagining Lexical Search
Milvus 2.5 introduces native lexical search support through Sparse-BM25, building upon the hybrid search capabilities introduced in version 2.4. This innovative approach includes the following key components:
Advanced tokenization and preprocessing via Tantivy
Distributed vocabulary and term frequency management
Sparse vector generation using corpus TF and query TF-IDF
Inverted index support with WAND algorithm (Block-Max WAND and graph index support in development)
Compared to Elasticsearch, Milvus offers significant advantages in algorithm flexibility. Its vector distance-based similarity computation enables more sophisticated matching, including implementing TW-BERT (Term Weighting BERT) based on “End-to-End Query Term Weighting” research. This approach has demonstrated superior performance in both in-domain and out-domain testing.
Another crucial advantage is cost efficiency. By leveraging both inverted index and dense embedding compression, Milvus achieves a fivefold performance improvement with less than 1% recall degradation. Through tail-term pruning and vector quantization, memory usage has been reduced by over 50%.
Long query optimization stands out as a particular strength. Where traditional WAND algorithms struggle with longer queries, Milvus excels by combining sparse embeddings with graph indices, delivering a tenfold performance improvement in high-dimensional sparse vector search scenarios.
Milvus: The Ultimate Vector Database for RAG
Milvus is the premier choice for RAG applications through its comprehensive feature set. Key advantages include:
Rich metadata support with dynamic schema capabilities and powerful filtering options
Enterprise-grade multi-tenancy with flexible isolation through collections, partitions, and partition keys
Industry-first disk vector index support with multi-tier storage from memory to S3
Cloud-native scalability supporting seamless scaling from 10M to 1B+ vectors
Comprehensive search capabilities, including grouping, range, and hybrid search
Deep ecosystem integration with LangChain, LlamaIndex, Dify, and other AI tools
The system’s diverse search capabilities encompass grouping, range, and hybrid search methodologies. Deep integration with tools like LangChain, LlamaIndex, and Dify, as well as support for numerous AI products, places Milvus at the center of the modern AI infrastructure ecosystem.
Looking Forward
As AI transitions from POC to production, Milvus continues to evolve. We focus on making vector search more accessible and cost-effective while enhancing search quality. Whether you’re a startup or an enterprise, Milvus reduces the technical barriers to AI application development.
This commitment to accessibility and innovation has led us to another major step forward. While our open-source solution continues to serve as the foundation for thousands of applications worldwide, we recognize that many organizations need a fully managed solution that eliminates operational overhead.
Zilliz Cloud: The Managed Solution
We’ve built Zilliz Cloud, a fully managed vector database service based on Milvus, over the past three years. Through a cloud-native reimplementation of the Milvus protocol, it offers enhanced usability, cost efficiency, and security.
Drawing from our experience maintaining the world’s largest vector search clusters and supporting thousands of AI application developers, Zilliz Cloud significantly reduces operational overhead and costs compared to self-hosted solutions.
Ready to experience the future of vector search? Start your free trial today with up to $200 in credits, no credit card required.
- Why Hybrid Search is Complex in Production
- The Pain Points of Elasticsearch
- Introducing Sparse-BM25: Reimagining Lexical Search
- Milvus: The Ultimate Vector Database for RAG
- Looking Forward
- Zilliz Cloud: The Managed Solution
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



