JSON Shredding in Milvus: 88.9x Faster JSON Filtering with Flexibility
Modern AI systems are producing more semi-structured JSON data than ever before. Customer and product information are compacted to a JSON object, microservices emit JSON logs on every request, IoT devices stream sensor readings in lightweight JSON payloads, and today’s AI applications increasingly standardize on JSON for structured output. The result is a flood of JSON-like data flowing into vector databases.
Traditionally, there are two ways to handle JSON documents:
Predefine every field of JSON into a fixed schema and build an index: This approach delivers solid query performance, but it’s rigid. Once the data format changes, every new or modified field triggers another round of painful Data Definition Language (DDL) updates and schema migrations.
Store the entire JSON object as a single column (both JSON type and Dynamic Schema in Milvus use this approach): This option offers excellent flexibility, but at the cost of query performance. Each request requires runtime JSON parsing and often a full table scan, resulting in latency that spikes as the dataset grows.
It used to be a dilemma of flexibility and performance.
Not anymore with the newly introduced JSON Shredding feature in Milvus.
With the introduction of JSON Shredding, Milvus now achieves schema-free agility with the performance of columnar storage, finally making large-scale semi-structured data both flexible and query-friendly.
How JSON Shredding Works
JSON shredding speeds up JSON queries by transforming row-based JSON documents into highly optimized columnar storage. Milvus preserves the flexibility of JSON for data modeling while automatically optimizing columnar storage—significantly improving data access and query performance.
To handle sparse or rare JSON fields efficiently, Milvus also has an inverted index for shared keys. All of this happens transparently to users: you can insert JSON documents as usual, and leave it to Milvus to manage the optimal storage and indexing strategy internally.
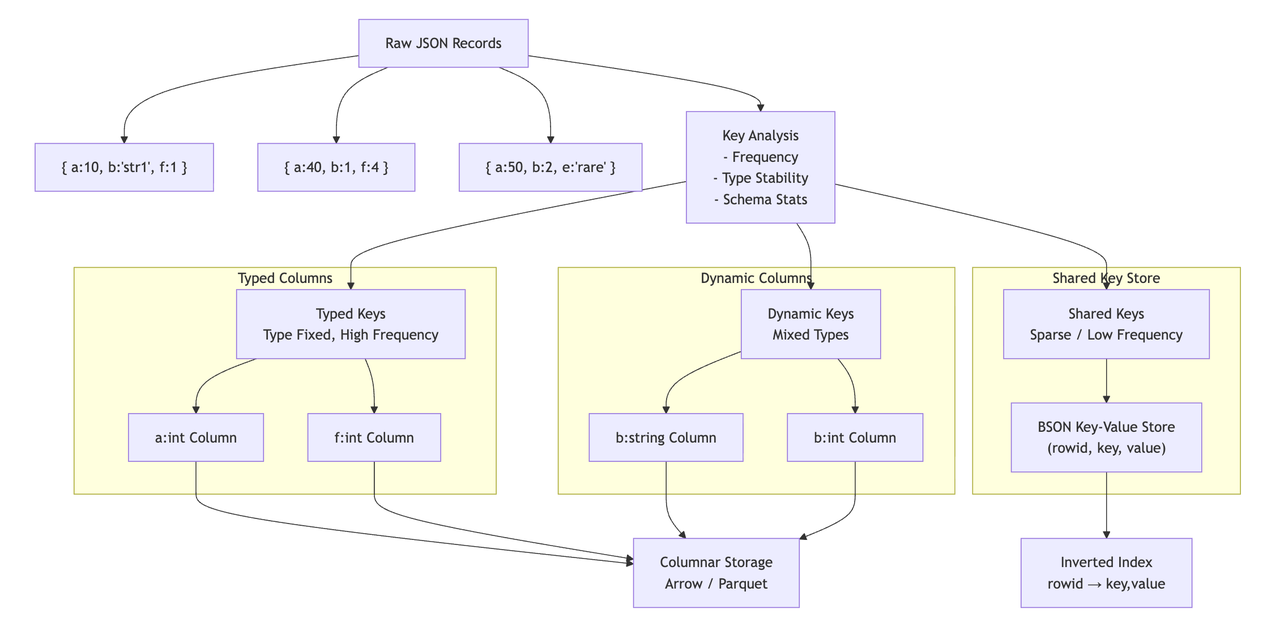
When Milvus receives raw JSON records with varying shapes and structures, it analyzes each JSON key for its occurrence ratio and type stability (whether its data type is consistent across documents). Based on this analysis, each key is classified into one of three categories:
Typed keys: Keys that appear in most documents and always have the same data type (e.g., all integers or all strings).
Dynamic keys: Keys that appear frequently but have mixed data types (e.g., sometimes a string, sometimes an integer).
Shared keys: Keys that are infrequent, sparse, or nested, falling below a configurable frequency threshold.
Milvus handles each category differently to maximize efficiency:
Typed keys are stored in dedicated, strongly typed columns.
Dynamic keys are placed into dynamic columns based on the actual value type observed at runtime.
Both typed and dynamic columns are stored in Arrow/Parquet columnar formats for fast scanning and highly optimized query execution.
Shared keys are consolidated into a compact binary-JSON column, accompanied by a shared-key inverted index. This index accelerates queries on low-frequency fields by pruning irrelevant rows early and restricting the search to only those documents that contain the queried key.
This combination of adaptive columnar storage and inverted indexing forms the core of Milvus’s JSON shredding mechanism, enabling both flexibility and high performance at scale.
The overall workflow is illustrated below:
Now that we’ve covered the basics of how JSON Shredding works, let’s take a closer look at the key capabilities that make this approach both flexible and high-performance.
Shredding and Columnarization
When a new JSON document is written, Milvus breaks it down and reorganizes it into optimized columnar storage:
Typed and dynamic keys are automatically identified and stored in dedicated columns.
If the JSON contains nested objects, Milvus generates path-based column names automatically. For example, a
namefield inside auserobject can be stored with the column name/user/name.Shared keys are stored together in a single, compact binary JSON column. Because these keys appear infrequently, Milvus builds an inverted index for them, enabling fast filtering and allowing the system to quickly locate the rows that contain the specified key.
Intelligent Column Management
Beyond shredding JSON into columns, Milvus adds an additional layer of intelligence through dynamic column management, ensuring that JSON Shredding stays flexible as data evolves.
Columns created as needed: When new keys appear in incoming JSON documents, Milvus automatically groups values with the same key into a dedicated column. This preserves the performance advantages of columnar storage without requiring users to design schemas upfront. Milvus also infers the data type of new fields (e.g., INTEGER, DOUBLE, VARCHAR) and selects an efficient columnar format for them.
Every key is handled automatically: Milvus analyzes and processes every key in the JSON document. This ensures broad query coverage without forcing users to predefine fields or build indexes in advance.
Query Optimization
Once the data is reorganized into the right columns, Milvus selects the most efficient execution path for each query:
Direct column scans for typed and dynamic keys: If a query targets a field that has already been split into its own column, Milvus can scan that column directly. This reduces the total amount of data that needs to be processed and leverages SIMD-accelerated columnar computation for even faster execution.
Indexed lookup for shared keys: If the query involves a field that was not promoted into its own column—typically a rare key—Milvus evaluates it against the shared-key column. The inverted index built on this column allows Milvus to quickly identify which rows contain the specified key and skip over the rest, significantly improving performance for low-frequency fields.
Automatic metadata management: Milvus continuously maintains global metadata and dictionaries so that queries remain accurate and efficient, even as the structure of incoming JSON documents evolves over time.
Performance benchmarks
We designed a benchmark to compare the query performance of storing the entire JSON document as a single raw field versus using the newly released JSON Shredding feature.
Test environment and methodology
Hardware: 1 core/8GB cluster
Dataset: 1 million documents from JSONBench
Methodology: Measure QPS and latency across different query patterns
Results: typed keys
This test measured performance when querying a key present in most documents.
| Query Expression | QPS (without shredding) | QPS (with shredding) | Performance Boost |
|---|---|---|---|
| json[‘time_us’] > 0 | 8.69 | 287.5 | 33x |
| json[‘kind’] == ‘commit’ | 8.42 | 126.1 | 14.9x |
Results: shared keys
This test focused on querying sparse, nested keys that fall into the “shared” category.
| Query Expression | QPS (without shredding) | QPS (with shredding) | Performance Boost |
|---|---|---|---|
| json[‘identity’][‘seq’] > 0 | 4.33 | 385 | 88.9x |
| json[‘identity’][‘did’] == ‘xxxxx’ | 7.6 | 352 | 46.3x |
Shared-key queries show the most dramatic improvements (up to 89× faster), while typed-key queries deliver consistent 15–30× speedups. Overall, every query type benefits from JSON Shredding, with clear performance gains across the board.
Try It Now
Whether you’re working with API logs, IoT sensor data, or rapidly evolving application payloads, JSON Shredding gives you the rare ability to have both flexibility and high performance.
The feature is now available and welcome to try it out now. You can also check this doc for more details.
Have questions or want a deep dive on any feature of the latest Milvus? Join our Discord channel or file issues on GitHub. You can also book a 20-minute one-on-one session to get insights, guidance, and answers to your questions through Milvus Office Hours.
- How JSON Shredding Works
- Shredding and Columnarization
- Intelligent Column Management
- Query Optimization
- Performance benchmarks
- Test environment and methodology
- Results: typed keys
- Results: shared keys
- Try It Now
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



