Paper Reading|HM-ANN When ANNS Meets Heterogeneous Memory
HM-ANN: Efficient Billion-Point Nearest Neighbor Search on Heterogenous Memory is a research paper that was accepted at the 2020 Conference on Neural Information Processing Systems (NeurIPS 2020). In this paper, a novel algorithm for graph-based similarity search, called HM-ANN, is proposed. This algorithm considers both memory heterogeneity and data heterogeneity in a modern hardware setting. HM-ANN enables billion-scale similarity search on a single machine without compression technologies. Heterogeneous memory (HM) represents the combination of fast but small dynamic random-access memory (DRAM) and slow but large persistent memory (PMem). HM-ANN achieves low search latency and high search accuracy, especially when the dataset cannot fit into DRAM. The algorithm has a distinct advantage over the state-of-art approximate nearest neighbor (ANN) search solutions.
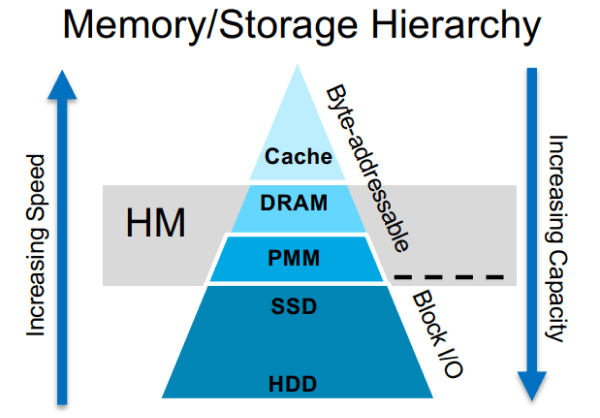
Since their inception, ANN search algorithms have posed a fundamental tradeoff between query accuracy and query latency due to the limited DRAM capacity. To store indexes in DRAM for fast query access, it is necessary to limit the number of data points or store compressed vectors, both of which hurt search accuracy. Graph-based indexes (e.g. Hierarchical Navigable Small World, HNSW) have superior query runtime performance and query accuracy. However, these indexes can also consume 1-TiB-level DRAM when operating on billion-scale datasets.
There are other workarounds to avoid letting DRAM store billion-scale datasets in raw format. When a dataset is too large to fit into memory on a single machine, compressed approaches such as product quantization of the dataset’s points are used. But the recall of those indexes with the compressed dataset is normally low because of the loss of precision during quantization. Subramanya et al. [1] explore leveraging solid-state drive (SSD) to achieve billion-scale ANN search using a single machine with an approach called Disk-ANN, where the raw dataset is stored on SSD and the compressed representation on DRAM.
 1.png
1.png
Heterogeneous memory (HM) represents the combination of fast but small DRAM and slow but large PMem. DRAM is normal hardware that can be found in every modern server, and its access is relatively fast. New PMem technologies, such as Intel® Optane™ DC Persistent Memory Modules, bridge the gap between NAND-based flash (SSD) and DRAM, eliminating the I/O bottleneck. PMem is durable like SSD, and directly addressable by the CPU, like memory. Renen et al. [2] discover that the PMem read bandwidth is 2.6× lower, and the write bandwidth 7.5× lower, than DRAM in the configured experiment environment.
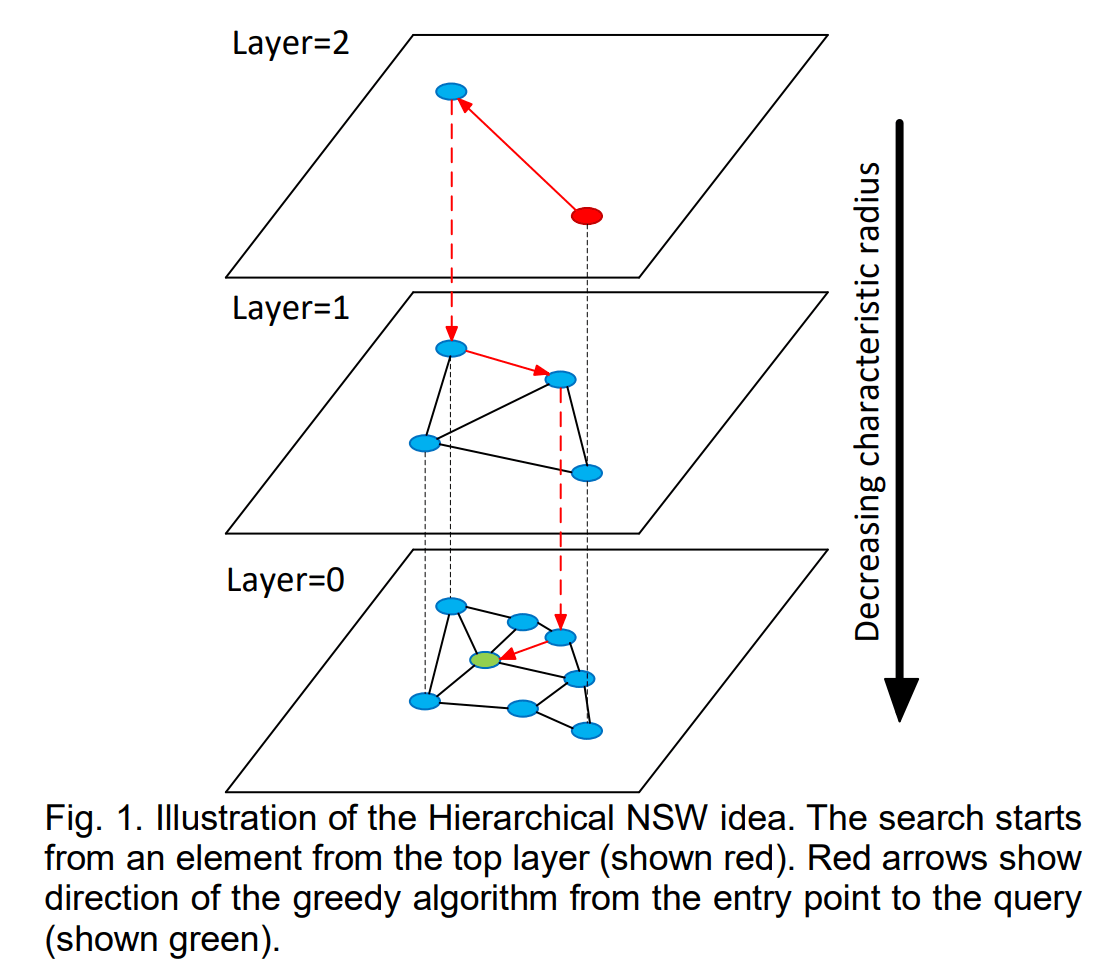
HM-ANN is an accurate and fast billion-scale ANN search algorithm that runs on a single machine without compression. The design of HM-ANN generalizes the idea of HNSW, whose hierarchical structure naturally fits into HM. HNSW consists of multiple layers—only layer 0 contains the whole dataset, and each remaining layer contains a subset of elements from the layer directly underneath it.
 2.png
2.png
- Elements in the upper layers, which include only subsets of the dataset, consume a small portion of the whole storage. This observation makes them decent candidates to be placed in DRAM. In this way, the majority of searches on HM-ANN are expected to happen in the upper layers, which maximizes the utilization of the fast access characteristic of DRAM. However, in the cases of HNSW, most searches happen in the bottom layer.
- The bottom-most layer carries the whole dataset, which makes it suitable to be placed in PMem. Since accessing layer 0 is slower, it is preferable to have only a small portion accessed by each query and the access frequency reduced.
Graph Construction Algorithm
 3.png
3.png
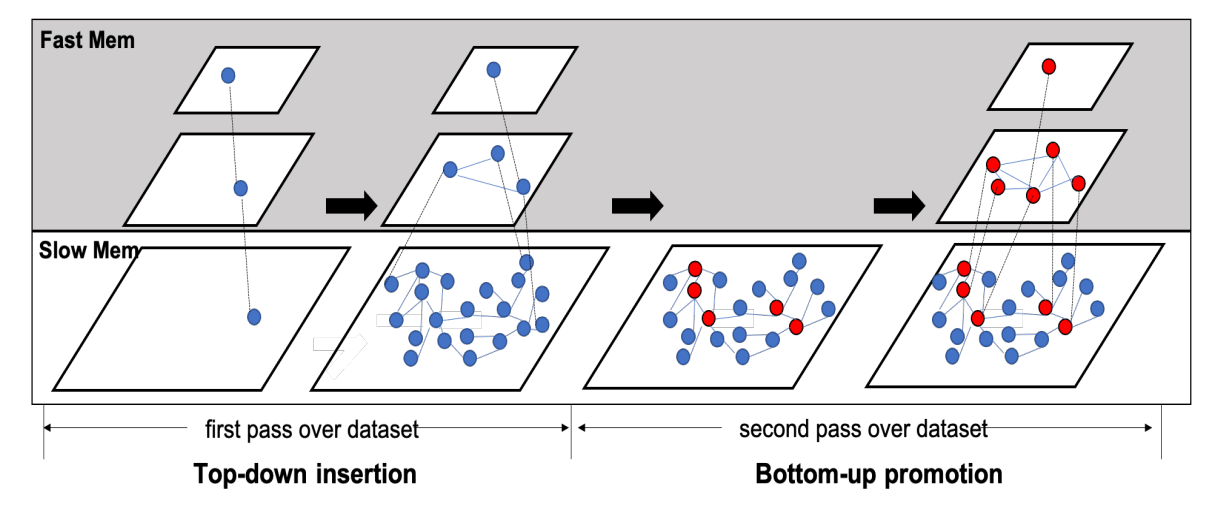
The key idea of HM-ANN’s construction is to create high-quality upper layers, in order to provide better navigation for search at layer 0. Thus most memory access happens in DRAM, and access in PMem is reduced. To make this possible, the construction algorithm of HM-ANN has a top-down insertion phase and a bottom-up promotion phase.
The top-down insertion phase builds a navigable small-world graph as the bottom-most layer is placed on the PMem.
The bottom-up promotion phase promotes pivot points from the bottom layer to form upper layers that are placed on DRAM without losing much accuracy. If a high-quality projection of elements from layer 0 is created in layer 1, search in layer 0 finds the accurate nearest neighbors of the query with only a few hops.
- Instead of using HNSW’s random selection for promotion, HM-ANN uses a high-degree promotion strategy to promote elements with the highest degree in layer 0 into layer 1. For higher layers, HM-ANN promotes high-degree nodes to the upper layer based on a promotion rate.
- HM-ANN promotes more nodes from layer 0 to layer 1 and sets a larger maximum number of neighbors for each element in layer 1. The number of nodes in the upper layers is decided by the available DRAM space. Since layer 0 is not stored in DRAM, making each layer stored in DRAM denser increases the search quality.
Graph Seach Algorithm
 4.png
4.png
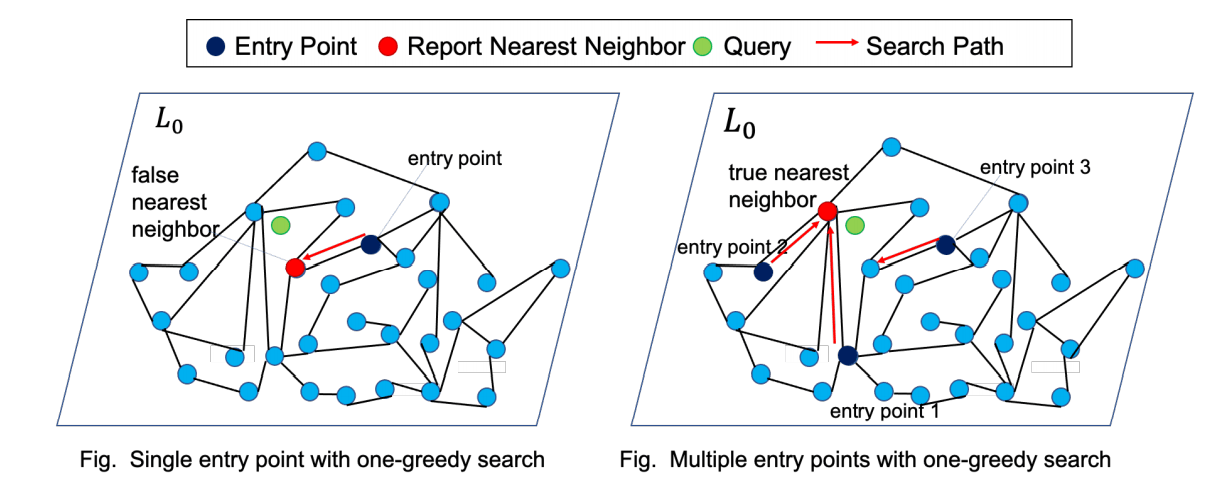
The search algorithm consists of two phases: fast memory search and parallel layer-0 search with prefetching.
Fast memory search
As the same as in HNSW, the search in DRAM begins at the entry point in the very top layer and then performs 1-greedy search from top to layer 2. To narrow down the search space in layer 0, HM-ANN performs the search in layer 1 with a search budget with efSearchL1, which limits the size of the candidate list in layer 1. Those candidates of the list are used as multiple entry points for search in layer 0, to enhance search quality in layer 0. While HNSW using only one entry point, the gap between layer 0 and layer 1 is more specially handled in HM-ANN than gaps between any other two layers.
Parallel layer-0 search with prefetching
In the bottom layer, HM-ANN evenly partitions the aforementioned candidates from searching layer 1 and sees them as entry points to perform a parallel multi-start 1-greedy search with threads. The top candidates from each search are collected to find the best candidates. As known, going down from layer 1 to layer 0 is exactly going to PMem. Parallel search hides the latency of PMem and makes the best use of memory bandwidth, to improve search quality without increasing search time.
HM-ANN implements a software-managed buffer in DRAM to prefetch data from PMem before the memory access happens. When searching layer 1, HM-ANN asynchronously copies neighbor elements of those candidates in efSearchL1 and the neighbor elements’ connections in layer 1 from PMem to the buffer. When the search in layer 0 happens, a portion of to-be-accessed data is already prefetched in DRAM, which hides the latency to access PMem and leads to shorter query time. It matches the design goal of HM-ANN, where most memory accesses happen in DRAM and memory accesses in PMem are reduced.
In this paper, an extensive evaluation is conducted. All experiments are done on a machine with Intel Xeon Gold 6252 CPU@2.3GHz. It uses DDR4 (96GB) as fast memory and Optane DC PMM (1.5TB) as slow memory. Five datasets are evaluated: BIGANN, DEEP1B, SIFT1M, DEEP1M, and GIST1M. For billion-scale tests, the following schemes are included: billion-scale quantization-based methods (IMI+OPQ and L&C), the non-compression-based methods (HNSW and NSG).
Billion-scale algorithm comparison
 5.png
5.png
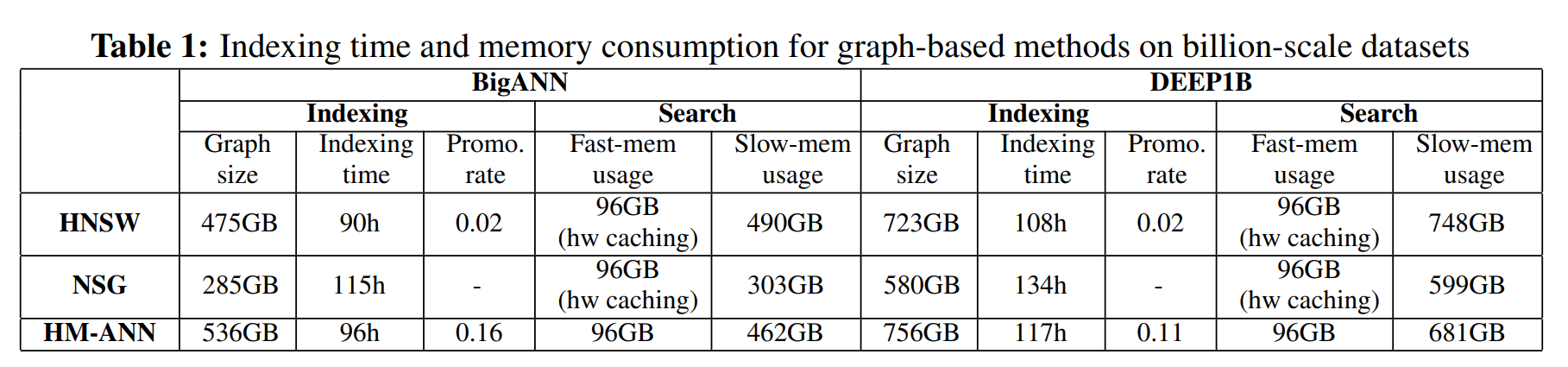
In table 1, the build time and storage of different graph-based indexes are compared. HNSW takes the shortest build time and HM-ANN needs 8% additional time than HNSW. In terms of whole storage usage, HM-ANN indexes are 5–13% larger than HSNW, because it promotes more nodes from layer 0 to layer 1.
 6.png
6.png
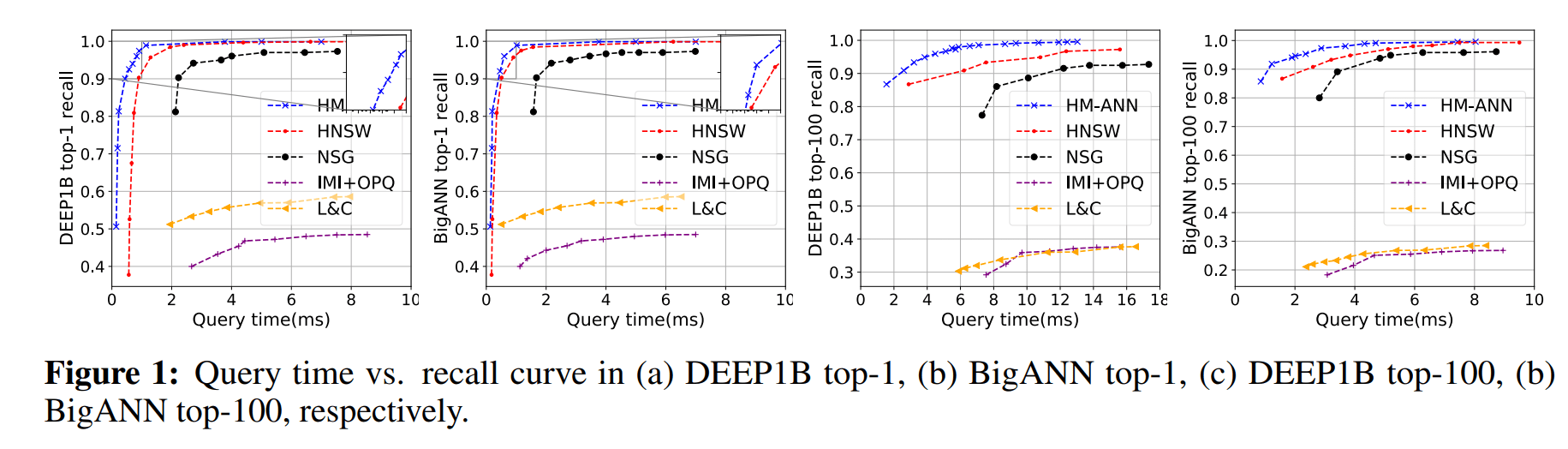
In Figure 1, the query performance of different indexes is analyzed. Figure 1 (a) and (b) show that HM-ANN achieves the top-1 recall of > 95% within 1ms. Figures 1 © and (d) show that HM-ANN obtains top-100 recall of > 90% within 4 ms. HM-ANN provides the best latency-vs-recall performance than all other approaches.
Million-scale algorithm comparison
 7.png
7.png
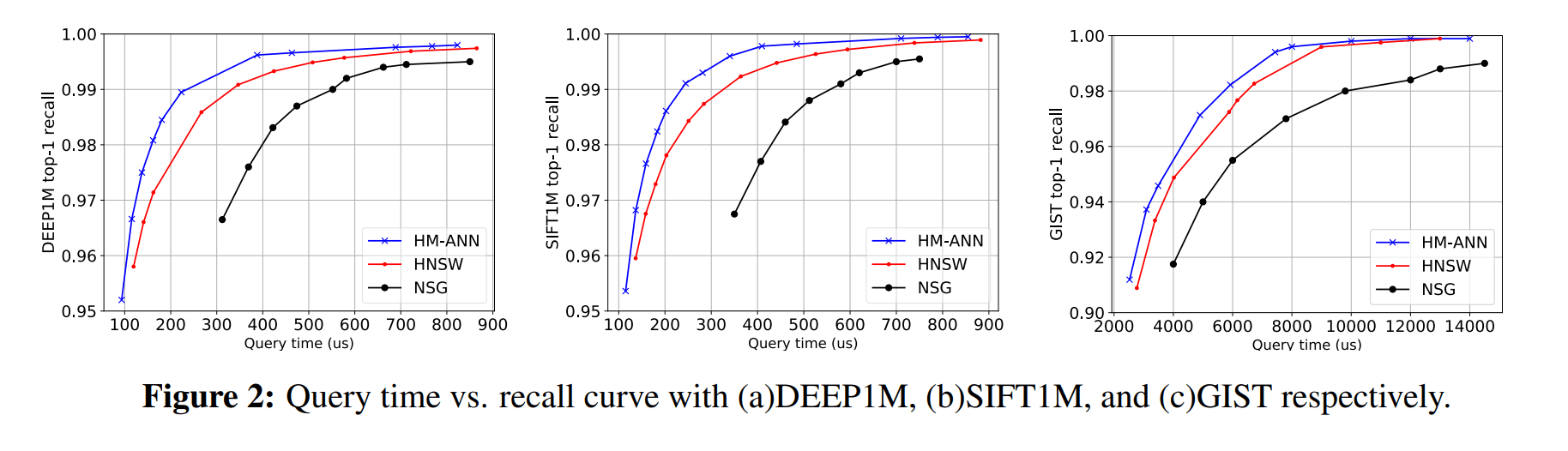
In Figure 2, the query performance of different indexes is analyzed in a pure DRAM setting. HNSW, NSG, and HM-ANN are evaluated with the three million-scale datasets fitting in DRAM. HM-ANN still achieves better query performance than HNSW. The reason is that the total number of distance computations from HM-ANN is lower (on average 850/query) than that of HNSW (on average 900/query) to achieve 99% recall target.
 8.png
8.png
Effectiveness of high-degree promotion
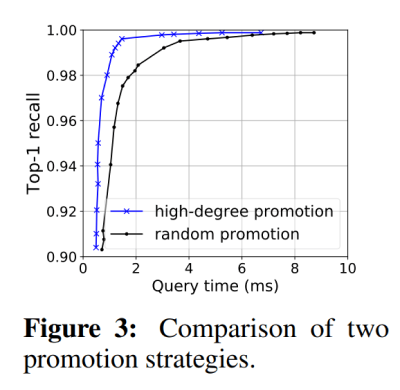
In Figure 3, the random promotion and high-degree promotion strategies are compared in the same configuration. The high-degree promotion outperforms the baseline. The high-degree promotion performs 1.8x, 4.3x, and 3.9x faster than the random promotion to reach 95%, 99%, and 99.5% recall targets, respectively.
 10.png
10.png
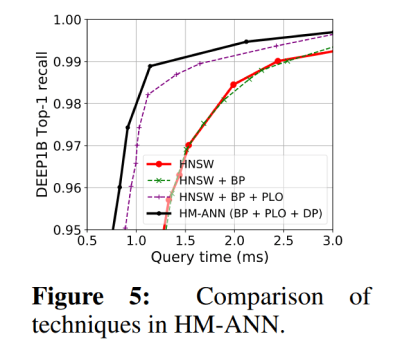
Performance benefit of memory management techniques
Figure 5 contains a series of steps between HNSW and HM-ANN to show how each optimization of HM-ANN contributes to its improvements. BP stands for the Bottom-up Promotion while building index. PL0 represents for Parallel layer-0 search, while DP for data prefetching from PMem to DRAM. Step by step, HM-ANN’s search performance is pushed further.
A new graph-based indexing and search algorithm, called HM-ANN, maps the hierarchical design of the graph-based ANNs with memory heterogeneity in HM. Evaluations show that HM-ANN belongs to the new state-of-the-art indexes in billion point datasets.
We notice a trend in academia as well as in industry, where building indexes on persistent storage devices is focused on. To offload the pressure of DRAM, Disk-ANN [1] is an index built on SSD, whose throughput is significantly lower than PMem. However, the building of HM-ANN still takes few days, where no huge differences compared with Disk-ANN is established. We believe it is possible to optimize the build time of HM-ANN, when we utilize PMem’s characteristics more carefully, e.g. to be aware of PMem’s granularity (256 Bytes) and to use streaming instruction to bypass cachelines. We also believe there would be more approaches with durable storage devices are proposed in the future.
[1]: Suhas Jayaram Subramanya and Devvrit and Rohan Kadekodi and Ravishankar Krishaswamy and Ravishankar Krishaswamy: DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node, NIPS, 2019
DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node - Microsoft Research
DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node
[2]: Alexander van Renen and Lukas Vogel and Viktor Leis and Thomas Neumann and Alfons Kemper: Persistent Memory I/O Primitives, CoRR & DaMoN, 2019
- Graph Construction Algorithm
- Graph Seach Algorithm
- Fast memory search
- Parallel layer-0 search with prefetching
- Billion-scale algorithm comparison
- Million-scale algorithm comparison
- Effectiveness of high-degree promotion
- Performance benefit of memory management techniques
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word


