Power high performance RAG for GenAI with HPE Alletra Storage MP + Milvus
This post was originally published on HPE Community and is reposted here with permission.
HPE Alletra Storage MP X10000 and Milvus power scalable, low-latency RAG, enabling LLMs to deliver accurate, context-rich responses with high-performance vector search for GenAI workloads.
In generative AI, RAG needs more than just an LLM
Context unleashes the true power of generative AI (GenAI) and large language models (LLMs). When an LLM has the right signals to orient its responses, it can deliver answers that are accurate, relevant, and trustworthy.
Think of it this way: if you were dropped into a dense jungle with a GPS device but no satellite signal. The screen shows a map, but without your current position, it is useless for navigation. On the contrary, a GPS with a strong satellite signal doesn’t just show a map; it gives you turn-by-turn guidance.
That’s what retrieval-augmented generation (RAG) does for LLMs. The model already has the map (its pretrained knowledge), but not the direction (your domain-specific data). LLMs without RAG are like GPS devices that are full of knowledge but have no real-time orientation. RAG provides the signal that tells the model where it is and where to go.
RAG grounds model responses in trusted, up-to-date knowledge pulled from your own domain-specific content from policies, product docs, tickets, PDFs, code, audio transcripts, images, and more. Making RAG work at scale is challenging. The retrieval process needs to be fast enough to keep user experiences seamless, accurate enough to return the most relevant information, and predictable even when the system is under heavy load. That means handling high query volumes, ongoing data ingestion, and background tasks like index building without performance degradation. Spinning up a RAG pipeline with a few PDFs is relatively straightforward. However, when scaling to hundreds of PDFs, it becomes significantly more challenging. You can’t keep everything in memory, so a robust and efficient storage strategy becomes essential to manage embeddings, indexes, and retrieval performance. RAG requires a vector database and a storage layer that can keep pace as concurrency and data volumes grow.
Vector databases power RAG
At the heart of RAG is semantic search, finding information by meaning rather than exact keywords. This is where vector databases come in. They store high-dimensional embeddings of text, images, and other unstructured data, enabling similarity search that retrieves the most relevant context for your queries. Milvus is a leading example: a cloud-native, open-source vector database built for billion-scale similarity search. It supports hybrid search, combining vector similarity with keyword and scalar filters for precision, and offers independent scaling of compute and storage with GPU-aware optimization options for acceleration. Milvus also manages data through a smart segment lifecycle, moving from growing to sealed segments with compaction and multiple approximate nearest neighbor (ANN) indexing options such as HNSW and DiskANN, ensuring performance and scalability for real-time AI workloads such as RAG.
The hidden challenge: Storage throughput & latency
Vector search workloads put pressure on every part of the system. They demand high‑concurrency ingestion while maintaining low‑latency retrieval for interactive queries. At the same time, background operations such as index building, compaction, and data reloads must run without disrupting live performance. Many performance bottlenecks in traditional architectures trace back to storage. Whether it’s input/output (I/O) limitations, metadata lookup delays, or concurrency constraints. To deliver predictable, real‑time performance at scale, the storage layer must keep pace with the demands of vector databases.
The storage foundation for high performance vector search
HPE Alletra Storage MP X10000 is a flash-optimized, all-NVMe, S3-compatible object storage platform engineered for real-time performance at scale. Unlike traditional capacity-focused object stores, HPE Alletra Storage MP X10000 is designed for low-latency, high-throughput workloads like vector search. Its log-structured key-value engine and extent-based metadata enable highly parallel reads and writes, while GPUDirect RDMA provides zero-copy data paths that reduce CPU overhead and accelerate data movement to GPUs. The architecture supports disaggregated scaling, allowing capacity and performance to grow independently, and includes enterprise-grade features such as encryption, role-based access control (RBAC), immutability, and data durability. Combined with its cloud-native design, HPE Alletra Storage MP X10000 integrates seamlessly with Kubernetes environments, making it an ideal storage foundation for Milvus deployments.
HPE Alletra Storage MP X10000 and Milvus: A scalable foundation for RAG
HPE Alletra Storage MP X10000 and Milvus complement each other to deliver RAG that is fast, predictable, and easy to scale. Figure 1 illustrates the architecture of scalable AI use cases and RAG pipelines, showing how Milvus components deployed in a containerized environment interact with high performance object storage from HPE Alletra Storage MP X10000.
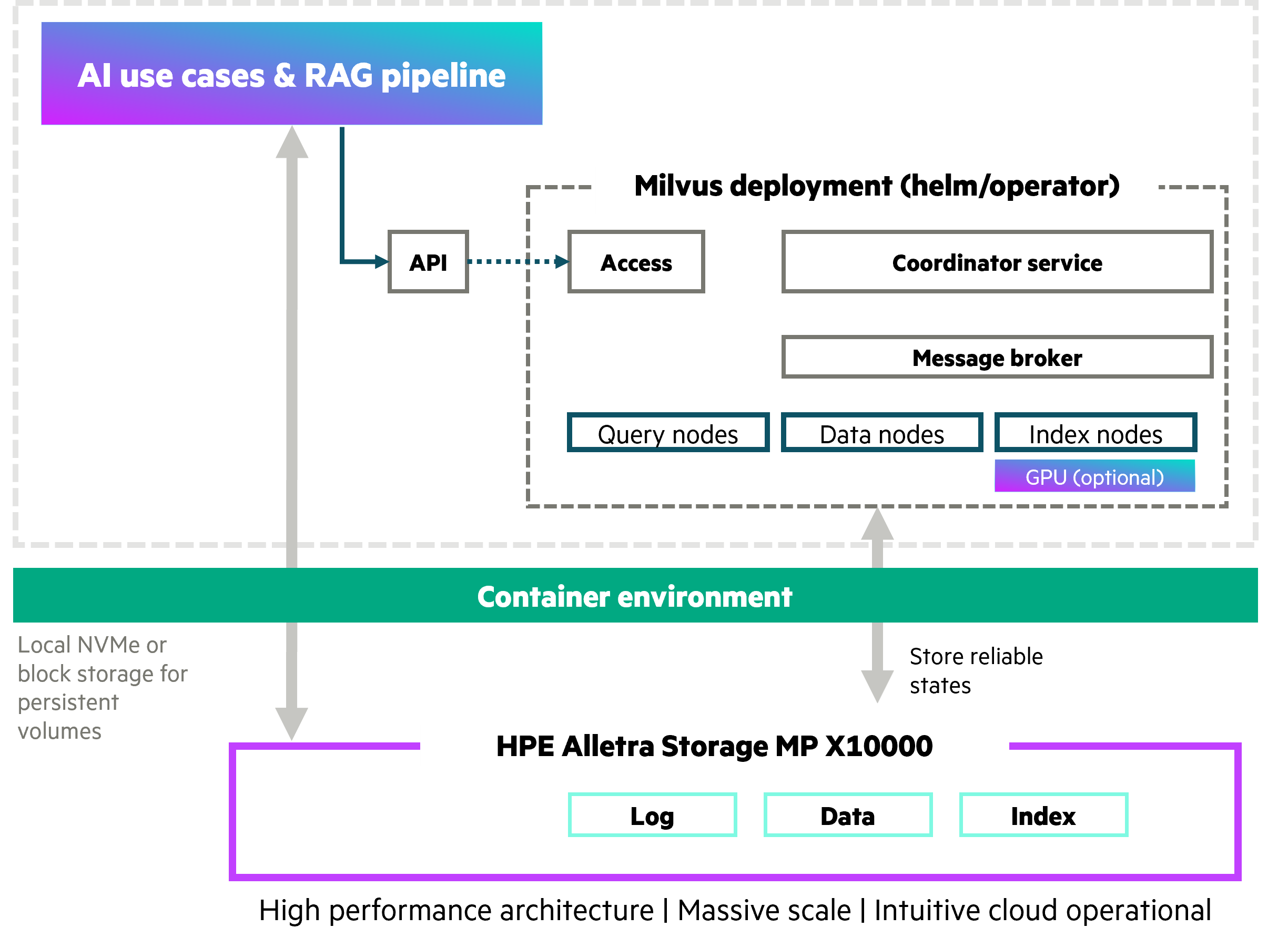
Milvus cleanly separates compute from storage, while HPE Alletra Storage MP X10000 provides high‑throughput, low‑latency object access that keeps pace with vector workloads. Together, they enable predictable scale‑out performance: Milvus distributes queries across shards, and HPE Alletra Storage MP X10000’s fractional, multidimensional scaling keeps latency consistent as data and QPS grow. In simple terms, you add exactly the capacity or performance you need, when you need it. Operational simplicity is another advantage: HPE Alletra Storage MP X10000 sustains maximum performance from a single bucket, eliminating complex tiering, while enterprise features (encryption, RBAC, immutability, robust durability) support on‑prem or hybrid deployments with strong data sovereignty and consistent service-level objectives (SLOs).
When vector search scales, storage is often blamed for slow ingestion, compaction, or retrieval. With Milvus on HPE Alletra Storage MP X10000, that narrative changes. The platform’s all‑NVMe, log‑structured architecture and GPUDirect RDMA option deliver consistent, ultra‑low‑latency object access—even under heavy concurrency and during lifecycle operations like index build and reload. In practice, your RAG pipelines remain compute‑bound, not storage‑bound. As collections grow and query volumes spike, Milvus stays responsive while HPE Alletra Storage MP X10000 preserves I/O headroom, enabling predictable, linear scalability without re‑architecting storage. This becomes especially important as RAG deployments scale beyond initial proof-of-concept stages and move into full production.
Enterprise-ready RAG: Scalable, predictable, and built for GenAI
For RAG and real-time GenAI workloads, the combination of HPE Alletra Storage MP X10000 and Milvus delivers a future-ready foundation that scales with confidence. This integrated solution empowers organizations to build intelligent systems that are fast, elastic, and secure—without compromising on performance or manageability. Milvus provides distributed, GPU-accelerated vector search with modular scaling, while HPE Alletra Storage MP X10000 ensures ultrafast, low-latency object access with enterprise-grade durability and lifecycle management. Together, they decouple compute from storage, enabling predictable performance even as data volumes and query complexity grow. Whether you’re serving real-time recommendations, powering semantic search, or scaling across billions of vectors, this architecture keeps your RAG pipelines responsive, cost-efficient, and cloud-optimized. With seamless integration into Kubernetes and HPE GreenLake cloud, you gain unified management, consumption-based pricing, and the flexibility to deploy across hybrid or private cloud environments. HPE Alletra Storage MP X10000 and Milvus: a scalable, high performance RAG solution built for the demands of modern GenAI.
- In generative AI, RAG needs more than just an LLM
- Vector databases power RAG
- The hidden challenge: Storage throughput & latency
- The storage foundation for high performance vector search
- HPE Alletra Storage MP X10000 and Milvus: A scalable foundation for RAG
- Enterprise-ready RAG: Scalable, predictable, and built for GenAI
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



