Productionizing Semantic Search: How We Built and Scaled Vector Infrastructure at Airtable
This post was originally published on the Airtable Medium channel and is reposted here with permission.
As semantic search at Airtable evolved from a concept into a core product feature, the Data Infrastructure team faced the challenge of scaling it. As detailed in our previous post on Building the Embedding System, we had already designed a robust, eventually consistent application layer to handle the embedding lifecycle. But one critical piece was still missing from our architecture diagram: the vector database itself.
We needed a storage engine capable of indexing and serving billions of embeddings, supporting massive multi-tenancy, and maintaining performance and availability targets in a distributed cloud environment. This is the story of how we architected, hardened, and evolved our vector search platform to become a core pillar of Airtable’s infrastructure stack.
Background
At Airtable, our goal is to help customers work with their data in powerful, intuitive ways. With the emergence of increasingly powerful and accurate LLMs, features that leverage the semantic meaning of your data have become core to our product.
How We Use Semantic Search
Omni (Airtable’s AI Chat) answering real questions from large datasets
Imagine asking a natural-language question of your base (database) with half a million rows, and getting a correct, context-rich answer. For example:
“What are customers saying about battery life lately?”
On small datasets, it’s possible to send all rows directly to an LLM. At scale, that quickly becomes infeasible. Instead, we needed a system capable of:
- Understanding the semantic intent of a query
- Retrieving the most relevant rows via vector similarity search
- Supplying those rows as context to an LLM
This requirement shaped nearly every design decision that followed: Omni needed to feel instant and intelligent, even on very large bases.
Linked record recommendations: Meaning over exact matches
Semantic search also enhances a core Airtable feature: linked records. Users need relationship suggestions based on context rather than exact text matches. For instance, a project description might imply a relationship with “Team Infrastructure” without ever using that specific phrase.
Delivering these on-demand suggestions requires high-quality semantic retrieval with consistent, predictable latency.
Our Design Priorities
To support these features and more, we anchored the system around 4 goals:
- Low-latency queries (500ms p99): predictable performance is critical for user trust
- High-throughput writes: bases change constantly, and embeddings must stay in sync
- Horizontal scalability: the system must support millions of independent bases
- Self-hosting: all customer data must remain inside Airtable-controlled infrastructure
These goals shaped every architectural decision that followed.
Vector Database Vendor Evaluation
In late 2024, we evaluated several vector database options and ultimately selected Milvus based on three key requirements.
- First, we prioritized a self-hosted solution to ensure data privacy and maintain fine-grained control of our infrastructure.
- Second, our write-heavy workload and bursty query patterns required a system that could scale elastically while maintaining low, predictable latency.
- Finally, our architecture required strong isolation across millions of customer tenants.
Milvus emerged as the best fit: its distributed nature supports massive multi-tenancy and allows us to scale ingestion, indexing, and query execution independently, delivering performance while keeping costs predictable.
Architecture Design
After choosing a technology, we then had to determine an architecture to represent Airtable’s unique data shape: millions of distinct “bases” owned by different customers.
The Partitioning Challenge
We evaluated two primary data partitioning strategies:
Option 1: Shared Partitions
Multiple bases share a partition, and queries are scoped by filtering on a base id. This improves resource utilization, but introduces additional filtering overhead and makes base deletion more complex.
Option 2: One Base per Partition
Each Airtable base is mapped to its own physical partition in Milvus. This provides strong isolation, enables fast and simple base deletion, and avoids the performance impact of post-query filtering.
Final Strategy
We chose option 2 for its simplicity and strong isolation. However, early tests showed that creating 100k partitions in a single Milvus collection caused significant performance degradation:
- Partition creation latency increased from ~20 ms to ~250 ms
- Partition load times exceeded 30 seconds
To address this, we capped the number of partitions per collection. For each Milvus cluster, we create 400 collections, each with at most 1,000 partitions. This limits the total number of bases per cluster to 400k, and new clusters are provisioned as additional customers are onboarded.
Indexing & Recall
Index choice turned out to be one of the most consequential trade-offs in our system. When a partition is loaded, its index is cached in memory or on disk. To strike a balance between recall rate, index size, and performance, we benchmarked several index types.
- IVF-SQ8: Offered a small memory footprint but lower recall.
- HNSW: Delivers the best recall (99%-100%) but is memory-hungry.
- DiskANN: Offers a recall similar to HNSW but with higher query latency
Ultimately, we selected HNSW for its superior recall and performance characteristics.
The Application layer
At a high level, Airtable’s semantic search pipeline involves two core flows:
- Ingestion flow: Convert Airtable rows into embeddings and store them in Milvus
- Query flow: Embed user queries, retrieve relevant row IDs, and provide context to the LLM
Both flows must operate continuously and reliably at scale, and we walk through each below. We walk through each below.
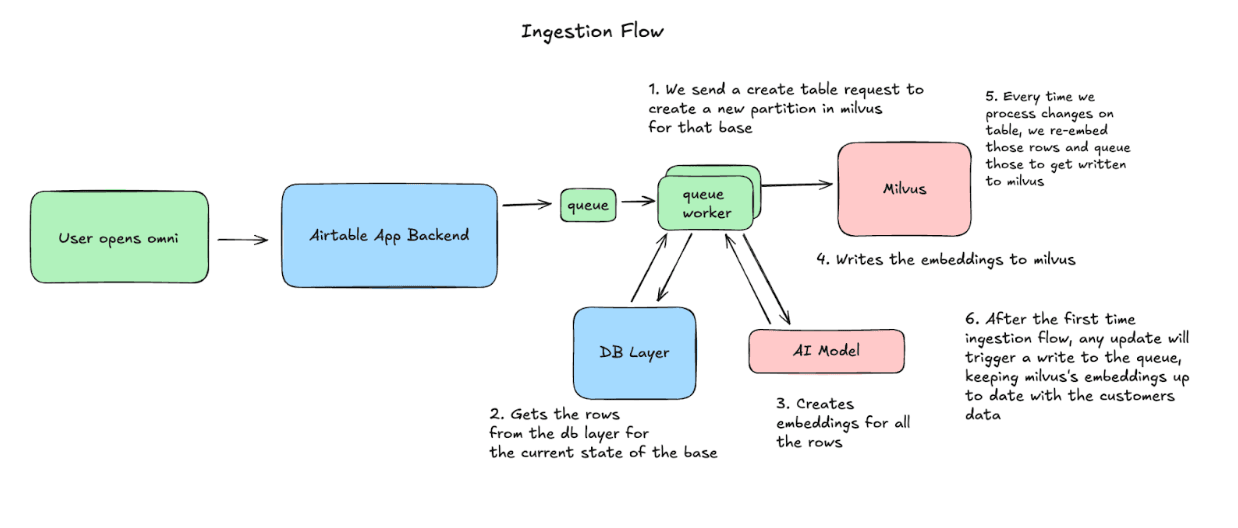
Ingestion Flow: Keeping Milvus in Sync with Airtable
When a user opens Omni, Airtable begins syncing their base to Milvus. We create a partition, then process the rows in chunks, generating embeddings and upserting into Milvus. From then on, we capture any changes made to the base, and re-embed and upsert those rows to keep the data consistent.
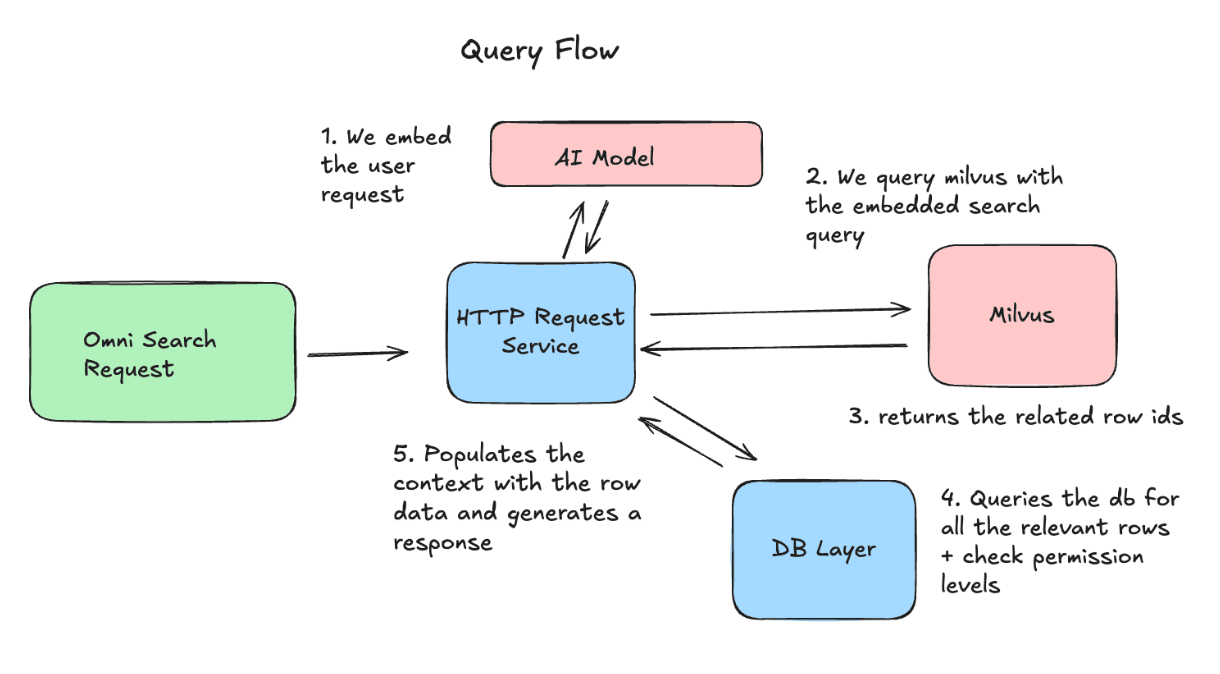
Query Flow: How we use the Data
On the query side, we embed the user’s request and send it to Milvus to retrieve the most relevant row IDs. We then fetch the latest versions of those rows and include them as context in the request to the LLM.
Operational Challenges & How We Solved Them
Building a semantic search architecture is one challenge; running it reliably for hundreds of thousands of bases is another. Below are a few key operational lessons we learned along the way.
Deployment
We deploy Milvus via its Kubernetes CRD with the Milvus operator, allowing us to define and manage clusters declaratively. Every change, whether it’s a configuration update, client improvement, or Milvus upgrade, runs through unit tests and an on-demand load test that simulates production traffic before rolling out to users.
In version 2.5, the Milvus cluster is made up of these core components:
- Query Nodes hold the vector indices in memory and execute vector searches
- Data Nodes handle ingestion and compaction, and persist new data to storage
- Index Nodes build and maintain vector indexes to keep search fast as data grows
- The Coordinator Node orchestrates all cluster activity and shard assignment
- Proxy nodes route API traffic and balance load across nodes
- Kafka provides the log/streaming backbone for internal messaging and data flow
- Etcd stores cluster metadata and coordination state
With CRD-driven automation and a rigorous testing pipeline, we can roll out updates quickly and safely.
Observability: Understanding System Health End-to-End
We monitor the system on two levels to ensure semantic search remains fast and predictable.
At the infrastructure level, we track CPU, memory usage, and pod health across all Milvus components. These signals tell us whether the cluster is operating within safe limits and help us catch issues such as resource saturation or unhealthy nodes before they affect users.
At the service layer, we focus on how well each base is keeping up with our ingestion and query workloads. Metrics like compaction and indexing throughput give us visibility into how efficiently data is being ingested. Query success rates and latency give us an understanding of the user experience querying the data, and partition growth lets us know how our data is growing, so we are alerted if we need to scale.
Node Rotation
For security and compliance reasons, we regularly rotate Kubernetes nodes. In a vector search cluster, this is non-trivial:
- As the query nodes are rotated, the coordinator will rebalance the in-memory data between the query nodes
- Kafka and Etcd store stateful information and require quorum and continuous availability
We address this with strict disruption budgets and a one-node-at-a-time rotation policy. The Milvus coordinator is given time to rebalance before the next node is cycled. This careful orchestration preserves reliability without slowing down our velocity.
Cold Partition Offloading
One of our biggest operational wins was recognizing that our data has clear hot/cold access patterns. By analyzing usage, we found that only ~25% of the data in Milvus is written to or read from in a given week. Milvus lets us offload entire partitions, freeing memory on the Query Nodes. If that data is needed later, we can reload it within seconds. This allows us to keep hot data in memory and offload the rest, reducing costs and allowing us to scale more efficiently over time.
Data Recovery
Before rolling Milvus out broadly, we needed confidence that we could recover quickly from any failure scenario. While most issues are covered by the cluster’s built-in fault tolerance, we also planned for rare cases where data might become corrupted or the system might enter an unrecoverable state.
In those situations, our recovery path is straightforward. We first bring up a fresh Milvus cluster so we can resume serving traffic almost immediately. Once the new cluster is live, we proactively re-embed the most commonly used bases, then lazily process the rest as they are accessed. This minimizes downtime for most-accessed data while the system gradually rebuilds a consistent semantic index.
What’s Next
Our work with Milvus has laid a strong foundation for semantic search at Airtable: powering fast, meaningful AI experiences at scale. With this system in place, we’re now exploring richer retrieval pipelines and deeper AI integrations across the product. There’s a lot of exciting work ahead, and we’re just getting started.
Thanks to all past and present Airtablets on Data Infrastructure and across the organization who contributed to this project: Alex Sorokin, Andrew Wang, Aria Malkani, Cole Dearmon-Moore, Nabeel Farooqui, Will Powelson, Xiaobing Xia.
About Airtable
Airtable is a leading digital operations platform that enables organizations to build custom apps, automate workflows, and manage shared data at enterprise scale. Designed to support complex, cross-functional processes, Airtable helps teams build flexible systems for planning, coordination, and execution on a shared source of truth. As Airtable expands its AI-powered platform, technologies like Milvus play an important role in strengthening the retrieval infrastructure needed to deliver faster, smarter product experiences.
- Background
- How We Use Semantic Search
- Omni (Airtable’s AI Chat) answering real questions from large datasets
- Linked record recommendations: Meaning over exact matches
- Our Design Priorities
- Vector Database Vendor Evaluation
- Architecture Design
- The Partitioning Challenge
- Option 1: Shared Partitions
- Option 2: One Base per Partition
- Final Strategy
- Indexing & Recall
- The Application layer
- Ingestion Flow: Keeping Milvus in Sync with Airtable
- Query Flow: How we use the Data
- Operational Challenges & How We Solved Them
- Deployment
- Observability: Understanding System Health End-to-End
- Node Rotation
- Cold Partition Offloading
- Data Recovery
- What’s Next
- About Airtable
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word