Wrapping up
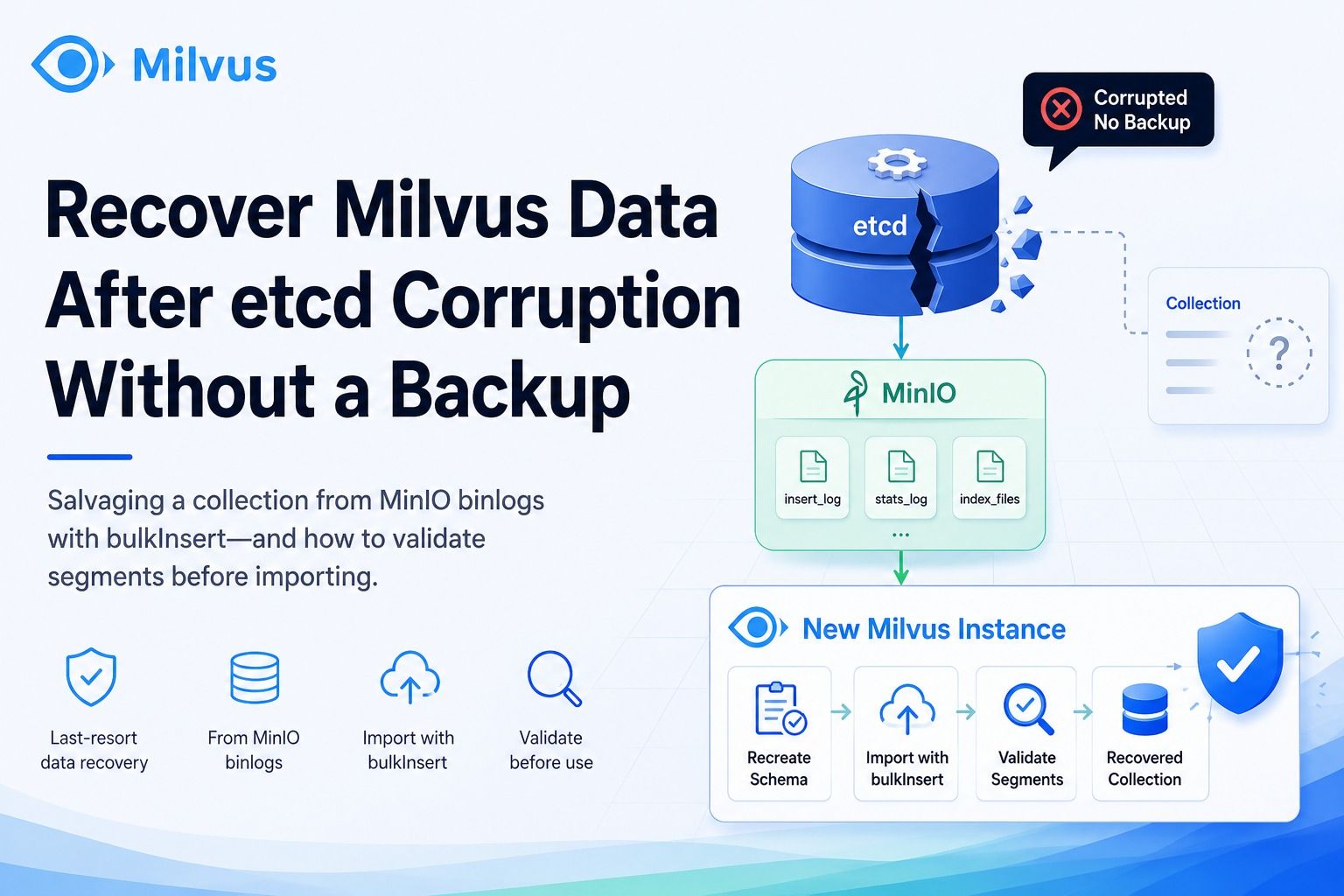
This article deals with how Milvus implements the delete function. As a much-anticipated feature for many users, the delete function was introduced to Milvus v0.7.0. We did not call remove_ids in FAISS directly, instead, we came up with a brand new design to make deletion more efficient and support more index types.
In How Milvus Realizes Dynamic Data Update and Query, we introduced the entire process from inserting data to flushing data. Let’s recap on some of the basics. MemManager manages all insert buffers, with each MemTable corresponding to a collection (we renamed “table” to “collection” in Milvus v0.7.0). Milvus automatically divides the data inserted to the memory into multiple MemTableFiles. When data is flushed to the disk, each MemTableFile is serialized into a raw file. We kept this architecture when designing the delete function.
We define the function of the delete method as deleting all data corresponding to the specified entity IDs in a specific collection. When developing this function, we designed two scenarios. The first is to delete the data that is still in the insert buffer, and the second is to delete the data that has been flushed to the disk. The first scenario is more intuitive. We can find the MemTableFile corresponding to the specified ID, and delete the data in the memory directly (Figure 1). Because deletion and insertion of data cannot be performed at the same time, and because of the mechanism that changes the MemTableFile from mutable to immutable when flushing data, deletion is only performed in the mutable buffer. In this way, the deletion operation does not clash with data flushing, hence ensuring the consistency of data.
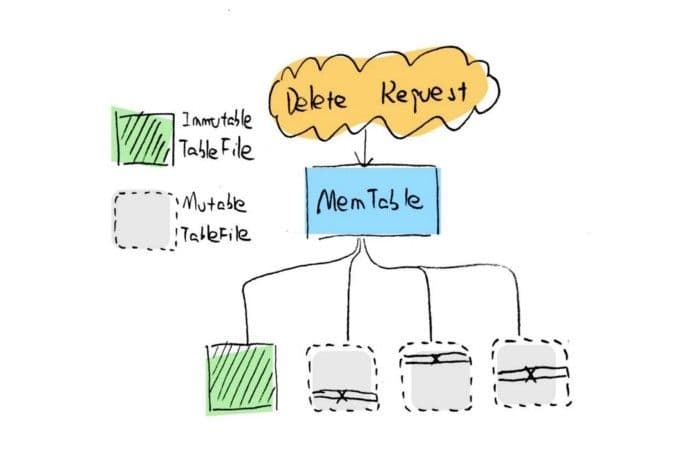 1-delete-request-milvus.jpg
1-delete-request-milvus.jpg
The second scenario is more complex but more commonplace, as in most cases the data stays in the insert buffer briefly before being flushed to the disk. Given that it is so inefficient to load flushed data to the memory for a hard deletion, we decided to go for soft deletion, a more efficient approach. Instead of actually deleting the flushed data, soft deletion saves deleted IDs in a separate file. In this way, we can filter out those deleted IDs during read operations, such as search.
When it comes to implementation, we have several issues to consider. In Milvus, data is visible or, in other words, recoverable, only when it is flushed to the disk. Therefore, flushed data is not deleted during the delete method call, but in the next flush operation. The reason is that the data files that have been flushed to the disk will no longer include new data, thus soft deletion does not impact the data that has been flushed. When calling delete, you can directly delete the data that is still in the insert buffer, while for the flushed data, you need to record the ID of the deleted data in the memory. When flushing data to the disk, Milvus writes the deleted ID to the DEL file to record which entity in the corresponding segment is deleted. These updates will be visible only after the data flushing completes. This process is illustrated in Figure 2. Before v0.7.0, we only had an auto-flush mechanism in place; that is, Milvus serializes the data in the insert buffer every second. In our new design, we added a flush method allowing developers to call after the delete method, ensuring that the newly inserted data is visible and the deleted data is no longer recoverable.
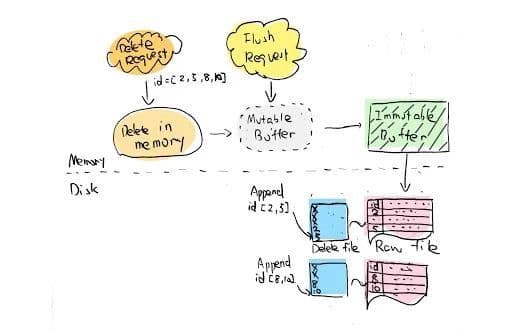 2-delete-request-milvus.jpg
2-delete-request-milvus.jpg
The second issue is that the raw data file and the index file are two separate files in Milvus, and two independent records in the metadata. When deleting a specified ID, we need to find the raw file and index file corresponding to the ID and record them together. Accordingly, we introduced the concept of segment. A segment contains the raw file (which includes the raw vector files and ID files), the index file, and the DEL file. Segment is the most basic unit for reading, writing, and searching vectors in Milvus. A collection (Figure 3) is composed of multiple segments. Thus, there are multiple segment folders under a collection folder in the disk. Since our metadata is based on relational databases (SQLite or MySQL), it is very simple to record the relationship within a segment, and the delete operation no longer requires separate processing of the raw file and the index file.
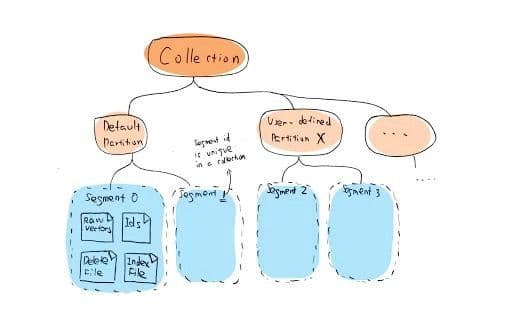 3-delete-request-milvus.jpg
3-delete-request-milvus.jpg
The third issue is how to filter out deleted data during a search. In practice, the ID recorded by DEL is the offset of the corresponding data stored in the segment. Since the flushed segment does not include new data, the offset will not change. The data structure of DEL is a bitmap in the memory, where an active bit represents a deleted offset. We also updated FAISS accordingly: when you search in FAISS, the vector corresponding to the active bit will no longer be included in the distance calculation (Figure 4). The changes to FAISS will not be addressed in detail here.
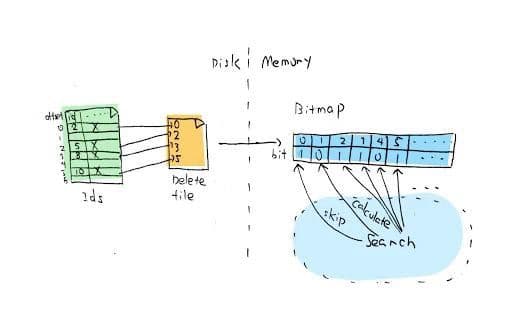 4-delete-request-milvus.jpg
4-delete-request-milvus.jpg
The last issue is about performance improvement. When deleting flushed data, you first need to find out which segment of the collection the deleted ID is in and then record its offset. The most straightforward approach is to search all IDs in each segment. The optimization we are thinking about is adding a bloom filter to each segment. Bloom filter is a random data structure used to check whether an element is a member of a set. Therefore, we can load only the bloom filter of each segment. Only when the bloom filter determines that the deleted ID is in the current segment can we find the corresponding offset in the segment; otherwise, we can ignore this segment (Figure 5). We choose bloom filter because it uses less space and is more efficient in searching than many of its peers, such as hash tables. Although the bloom filter has a certain rate of false positive, we can reduce the segments that need to be searched to the ideal number to adjust the probability. Meanwhile, the bloom filter also needs to support deletion. Otherwise, the deleted entity ID can still be found in the bloom filter, resulting in an increased false-positive rate. For this reason, we use the counting bloom filter as it supports deletion. In this article, we will not elaborate on how the bloom filter works. You may refer to Wikipedia if you are interested.
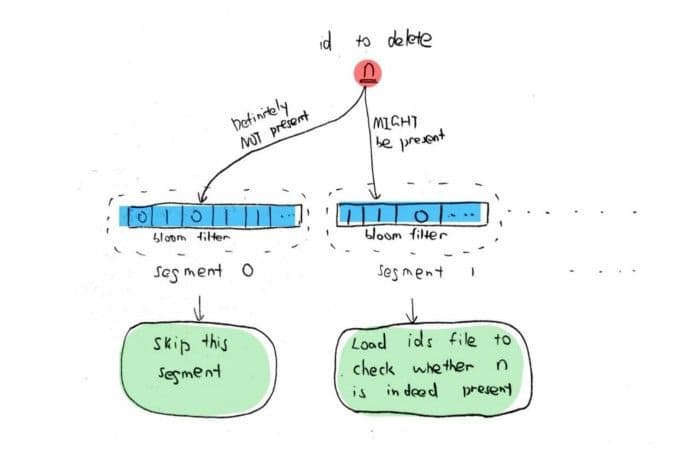 5-delete-request-milvus.jpg
5-delete-request-milvus.jpg
Wrapping up
So far, we have given you a brief introduction about how Milvus deletes vectors by ID. As you know, we use soft deletion to delete the flushed data. As the deleted data increases, we need to compact the segments in the collection to release the space occupied by the deleted data. Besides, if a segment has already been indexed, compact also deletes the previous index file and creates new indexes. For now, developers need to call the compact method to compact data. Going forward, we hope to introduce an inspection mechanism. For example, when the amount of deleted data reaches a certain threshold or the data distribution has changed after a deletion, Milvus automatically compacts the segment.
Now we have introduced the design philosophy behind the delete function and its implementation. There is definitely room for improvement, and any of your comments or suggestions are welcome.
Get to know about Milvus: https://github.com/milvus-io/milvus. You can also join our community Slack for technical discussions!
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word