How to Get the Right Vector Embeddings
This article was originally published in The New Stack and is reposted here with permission.
A comprehensive introduction to vector embeddings and how to generate them with popular open source models.
 Image by Денис Марчук from Pixabay
Image by Денис Марчук from Pixabay
Vector embeddings are critical when working with semantic similarity. However, a vector is simply a series of numbers; a vector embedding is a series of numbers representing input data. Using vector embeddings, we can structure unstructured data or work with any type of data by converting it into a series of numbers. This approach allows us to perform mathematical operations on the input data, rather than relying on qualitative comparisons.
Vector embeddings are influential for many tasks, particularly for semantic search. However, it is crucial to obtain the appropriate vector embeddings before using them. For instance, if you use an image model to vectorize text, or vice versa, you will probably get poor results.
In this post, we will learn what vector embeddings mean, how to generate the right vector embeddings for your applications using different models and how to make the best use of vector embeddings with vector databases like Milvus and Zilliz Cloud.
How are vector embeddings created?
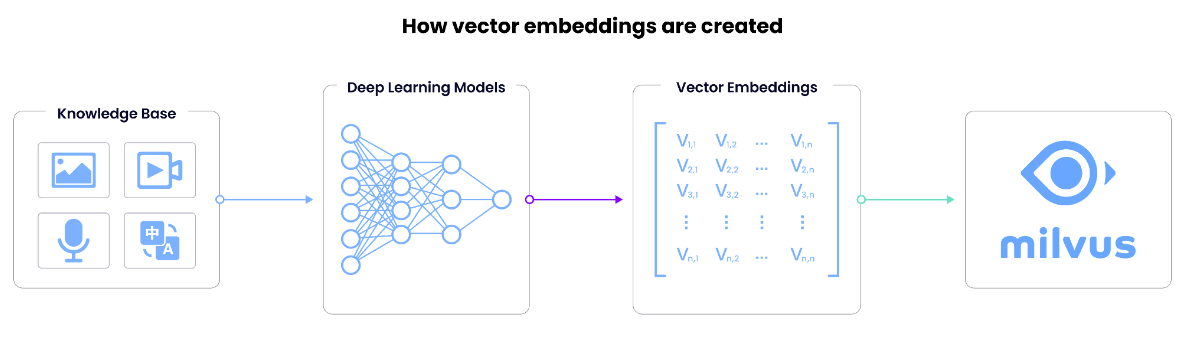
Now that we understand the importance of vector embeddings, let’s learn how they work. A vector embedding is the internal representation of input data in a deep learning model, also known as embedding models or a deep neural network. So, how do we extract this information?
We obtain vectors by removing the last layer and taking the output from the second-to-last layer. The last layer of a neural network usually outputs the model’s prediction, so we take the output of the second-to-last layer. The vector embedding is the data fed to a neural network’s predictive layer.
The dimensionality of a vector embedding is equivalent to the size of the second-to-last layer in the model and, thus, interchangeable with the vector’s size or length. Common vector dimensionalities include 384 (generated by Sentence Transformers Mini-LM), 768 (by Sentence Transformers MPNet), 1,536 (by OpenAI) and 2,048 (by ResNet-50).
What does a vector embedding mean?
Someone once asked me about the meaning of each dimension in a vector embedding. The short answer is nothing. A single dimension in a vector embedding does not mean anything, as it is too abstract to determine its meaning. However, when we take all dimensions together, they provide the semantic meaning of the input data.
The dimensions of the vector are high-level, abstract representations of different attributes. The represented attributes depend on the training data and the model itself. Text and image models generate different embeddings because they’re trained for fundamentally different data types. Even different text models generate different embeddings. Sometimes they differ in size; other times, they differ in the attributes they represent. For instance, a model trained on legal data will learn different things than one trained on health-care data. I explored this topic in my post comparing vector embeddings.
Generate the right vector embeddings
How do you obtain the proper vector embeddings? It all starts with identifying the type of data you wish to embed. This section covers embedding five different types of data: images, text, audio, videos and multimodal data. All models we introduce here are open source and come from Hugging Face or PyTorch.
Image embeddings
Image recognition took off in 2012 after AlexNet hit the scene. Since then, the field of computer vision has witnessed numerous advancements. The latest notable image recognition model is ResNet-50, a 50-layer deep residual network based on the former ResNet-34 architecture.
Residual neural networks (ResNet) solve the vanishing gradient problem in deep convolutional neural networks using shortcut connections. These connections allow the output from earlier layers to go to later layers directly without passing through all the intermediate layers, thus avoiding the vanishing gradient problem. This design makes ResNet less complex than VGGNet (Visual Geometry Group), a previously top-performing convolutional neural network.
I recommend two ResNet-50 implementations as examples: ResNet 50 on Hugging Face and ResNet 50 on PyTorch Hub. While the networks are the same, the process of obtaining embeddings differs.
The code sample below demonstrates how to use PyTorch to obtain vector embeddings. First, we load the model from PyTorch Hub. Next, we remove the last layer and call .eval() to instruct the model to behave like it’s running for inference. Then, the embed function generates the vector embedding.
# Load the embedding model with the last layer removed
model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50', pretrained=True) model = torch.nn.Sequential(*(list(model.children())[:-1]))
model.eval()
def embed(data):
with torch.no_grad():
output = model(torch.stack(data[0])).squeeze()
return output
HuggingFace uses a slightly different setup. The code below demonstrates how to obtain a vector embedding from Hugging Face. First, we need a feature extractor and model from the transformers library. We will use the feature extractor to get inputs for the model and use the model to obtain outputs and extract the last hidden state.
# Load model directly
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")
from PIL import Image
image = Image.open("<image path>")
# image = Resize(size=(256, 256))(image)
inputs = extractor(images=image, return_tensors="pt")
# print(inputs)
outputs = model(**inputs)
vector_embeddings = outputs[1][-1].squeeze()
Text embeddings
Engineers and researchers have been experimenting with natural language and AI since the invention of AI. Some of the earliest experiments include:
- ELIZA, the first AI therapist chatbot.
- John Searle’s Chinese Room, a thought experiment that examines whether the ability to translate between Chinese and English requires an understanding of the language.
- Rule-based translations between English and Russian.
AI’s operation on natural language has evolved significantly from its rule-based embeddings. Starting with primary neural networks, we added recurrence relations through RNNs to keep track of steps in time. From there, we used transformers to solve the sequence transduction problem.
Transformers consist of an encoder, which encodes an input into a matrix representing the state, an attention matrix and a decoder. The decoder decodes the state and attention matrix to predict the correct next token to finish the output sequence. GPT-3, the most popular language model to date, comprises strict decoders. They encode the input and predict the right next token(s).
Here are two models from the sentence-transformers library by Hugging Face that you can use in addition to OpenAI’s embeddings:
- MiniLM-L6-v2: a 384-dimensional model
- MPNet-Base-V2: a 768-dimensional model
You can access embeddings from both models in the same way.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("<model-name>")
vector_embeddings = model.encode(“<input>”)
Multimodal embeddings
Multimodal models are less well-developed than image or text models. They often relate images to text.
The most useful open source example is CLIP VIT, an image-to-text model. You can access CLIP VIT’s embeddings in the same way as you would an image model, as shown in the code below.
# Load model directly
from transformers import AutoProcessor, AutoModelForZeroShotImageClassification
processor = AutoProcessor.from_pretrained("openai/clip-vit-large-patch14")
model = AutoModelForZeroShotImageClassification.from_pretrained("openai/clip-vit-large-patch14")
from PIL import Image
image = Image.open("<image path>")
# image = Resize(size=(256, 256))(image)
inputs = extractor(images=image, return_tensors="pt")
# print(inputs)
outputs = model(**inputs)
vector_embeddings = outputs[1][-1].squeeze()
Audio embeddings
AI for audio has received less attention than AI for text or images. The most common use case for audio is speech-to-text for industries such as call centers, medical technology and accessibility. One popular open source model for speech-to-text is Whisper from OpenAI. The code below shows how to obtain vector embeddings from the speech-to-text model.
import torch
from transformers import AutoFeatureExtractor, WhisperModel
from datasets import load_dataset
model = WhisperModel.from_pretrained("openai/whisper-base")
feature_extractor = AutoFeatureExtractor.from_pretrained("openai/whisper-base")
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
inputs = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt")
input_features = inputs.input_features
decoder_input_ids = torch.tensor([[1, 1]]) * model.config.decoder_start_token_id
vector_embedding = model(input_features, decoder_input_ids=decoder_input_ids).last_hidden_state
Video embeddings
Video embeddings are more complex than audio or image embeddings. A multimodal approach is necessary when working with videos, as they include synchronized audio and images. One popular video model is the multimodal perceiver from DeepMind. This notebook tutorial shows how to use the model to classify a video.
To get the embeddings of the input, use outputs[1][-1].squeeze() from the code shown in the notebook instead of deleting the outputs. I highlight this code snippet in the autoencode function.
def autoencode_video(images, audio):
# only create entire video once as inputs
inputs = {'image': torch.from_numpy(np.moveaxis(images, -1, 2)).float().to(device),
'audio': torch.from_numpy(audio).to(device),
'label': torch.zeros((images.shape[0], 700)).to(device)}
nchunks = 128
reconstruction = {}
for chunk_idx in tqdm(range(nchunks)):
image_chunk_size = np.prod(images.shape[1:-1]) // nchunks
audio_chunk_size = audio.shape[1] // SAMPLES_PER_PATCH // nchunks
subsampling = {
'image': torch.arange(
image_chunk_size * chunk_idx, image_chunk_size * (chunk_idx + 1)),
'audio': torch.arange(
audio_chunk_size * chunk_idx, audio_chunk_size * (chunk_idx + 1)),
'label': None,
}
# forward pass
with torch.no_grad():
outputs = model(inputs=inputs, subsampled_output_points=subsampling)
output = {k:v.cpu() for k,v in outputs.logits.items()}
reconstruction['label'] = output['label']
if 'image' not in reconstruction:
reconstruction['image'] = output['image']
reconstruction['audio'] = output['audio']
else:
reconstruction['image'] = torch.cat(
[reconstruction['image'], output['image']], dim=1)
reconstruction['audio'] = torch.cat(
[reconstruction['audio'], output['audio']], dim=1)
vector_embeddings = outputs[1][-1].squeeze()
# finally, reshape image and audio modalities back to original shape
reconstruction['image'] = torch.reshape(reconstruction['image'], images.shape)
reconstruction['audio'] = torch.reshape(reconstruction['audio'], audio.shape)
return reconstruction
return None
Storing, indexing, and searching vector embeddings with vector databases
Now that we understand what vector embeddings are and how to generate them using various powerful embedding models, the next question is how to store and take advantage of them. Vector databases are the answer.
Vector databases like Milvus and Zilliz Cloud are purposely built for storing, indexing, and searching across massive datasets of unstructured data through vector embeddings. They are also one of the most critical infrastructures for various AI stacks.
Vector databases usually use the Approximate Nearest Neighbor (ANN) algorithm to calculate the spatial distance between the query vector and vectors stored in the database. The closer the two vectors are located, the more relevant they are. Then the algorithm finds the top k nearest neighbors and delivers them to the user.
Vector databases are popular in use cases such as LLM retrieval augmented generation (RAG), question and answer systems, recommender systems, semantic searches, and image, video and audio similarity searches.
To learn more about vector embeddings, unstructured data, and vector databases, consider starting with the Vector Database 101 series.
Summary
Vectors are a powerful tool for working with unstructured data. Using vectors, we can mathematically compare different pieces of unstructured data based on semantic similarity. Choosing the right vector-embedding model is critical for building a vector search engine for any application.
In this post, we learned that vector embeddings are the internal representation of input data in a neural network. As a result, they depend highly on the network architecture and the data used to train the model. Different data types (such as images, text, and audio) require specific models. Fortunately, many pretrained open source models are available for use. In this post, we covered models for the five most common types of data: images, text, multimodal, audio, and video. In addition, if you want to make the best use of vector embeddings, vector databases are the most popular tool.
- How are vector embeddings created?
- What does a vector embedding mean?
- Generate the right vector embeddings
- Image embeddings
- Text embeddings
- Multimodal embeddings
- Audio embeddings
- Video embeddings
- Storing, indexing, and searching vector embeddings with vector databases
- Summary
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



