Отчет о тестировании Milvus 2.2 Benchmark
В этом отчете представлены основные результаты тестирования Milvus 2.2.0. Его цель - дать представление о производительности поиска Milvus 2.2.0, особенно в части возможности расширения и масштабирования.

Недавно мы провели сравнение с Milvus 2.2.3 и получили следующие основные результаты:
- 2,5-кратное сокращение задержки при поиске
- Увеличение QPS в 4,5 раза
- Поиск сходства в миллиардных масштабах с незначительным снижением производительности
- Линейная масштабируемость при использовании нескольких реплик.
Для получения более подробной информации, пожалуйста, обратитесь к этому техническому описанию и соответствующему тестовому коду бенчмарка.
Резюме
- По сравнению с Milvus 2.1, QPS Milvus 2.2.0 увеличивается более чем на 48 % в кластерном режиме и более чем на 75 % в автономном режиме.
- Milvus 2.2.0 обладает впечатляющей способностью к увеличению и уменьшению масштаба:
- QPS линейно увеличивается при увеличении числа ядер процессора с 8 до 32.
- QPS линейно увеличивается при увеличении количества реплик Querynode с 1 до 8.
Терминология
Нажмите, чтобы узнать подробности терминов, использованных в тесте
Термин
Описание
nq
Количество векторов для поиска в одном поисковом запросе
topk
Число ближайших векторов, которые будут найдены для каждого вектора (в nq) в поисковом запросе
ef
Параметр поиска, специфичный для индекса HNSW
RT
Время от отправки запроса до получения ответа
QPS
Количество успешно обработанных поисковых запросов в секунду
Тестовая среда
Все тесты проводятся в следующих средах.
Аппаратная среда
| Аппаратное обеспечение | Спецификация |
|---|---|
| ПРОЦЕССОР | Центральный процессор Intel® Xeon® Gold 6226R @ 2,90 ГГц |
| Память | 16*\32 ГБ RDIMM, 3200 MT/s |
| ТВЕРДОТЕЛЬНЫЙ НАКОПИТЕЛЬ | SATA 6 Гбит/с |
Программная среда
| Программное обеспечение | Версия |
|---|---|
| Milvus | v2.2.0 |
| Milvus GO SDK | v2.2.0 |
Схема развертывания
- Экземпляры Milvus (автономные или кластерные) разворачиваются через Helm на кластере Kubernetes на базе физических или виртуальных машин.
- Различные тесты могут отличаться количеством ядер процессора, объемом памяти и количеством реплик (рабочих узлов), что относится только к кластерам Milvus.
- Неопределенные конфигурации идентичны конфигурациям по умолчанию.
- Зависимости Milvus (MinIO, Pulsar и Etcd) хранят данные на локальном SSD в каждом узле.
- Поисковые запросы отправляются на экземпляры Milvus через Milvus GO SDK.
Наборы данных
В тесте используется открытый набор данных SIFT (128 измерений) из ANN-Benchmarks.
Конвейер тестирования
- Запустите экземпляр Milvus с помощью Helm с соответствующими конфигурациями сервера, указанными в каждом тесте.
- Подключитесь к экземпляру Milvus с помощью Milvus GO SDK и получите соответствующие результаты тестирования.
- Создайте коллекцию.
- Вставьте 1 миллион векторов SIFT. Создайте индекс HNSW и настройте параметры индекса, установив
Mна8иefConstructionна200. - Загрузите коллекцию.
- Выполните поиск с различным числом одновременных запросов с параметрами поиска
nq=1, topk=1, ef=64, длительность каждого одновременного запроса не менее 1 часа.
Результаты тестирования
Milvus 2.2.0 против Milvus 2.1.0
Кластер
Конфигурации серверов (кластер)
yaml queryNode: replicas: 1 resources: limits: cpu: "12.0" memory: 8Gi requests: cpu: "12.0" memory: 8Gi
Производительность поиска
| Milvus | QPS | RT(TP99) / мс | RT(TP50) / мс | отказ/с |
|---|---|---|---|---|
| 2.1.0 | 6904 | 59 | 28 | 0 |
| 2.2.0 | 10248 | 63 | 24 | 0 |
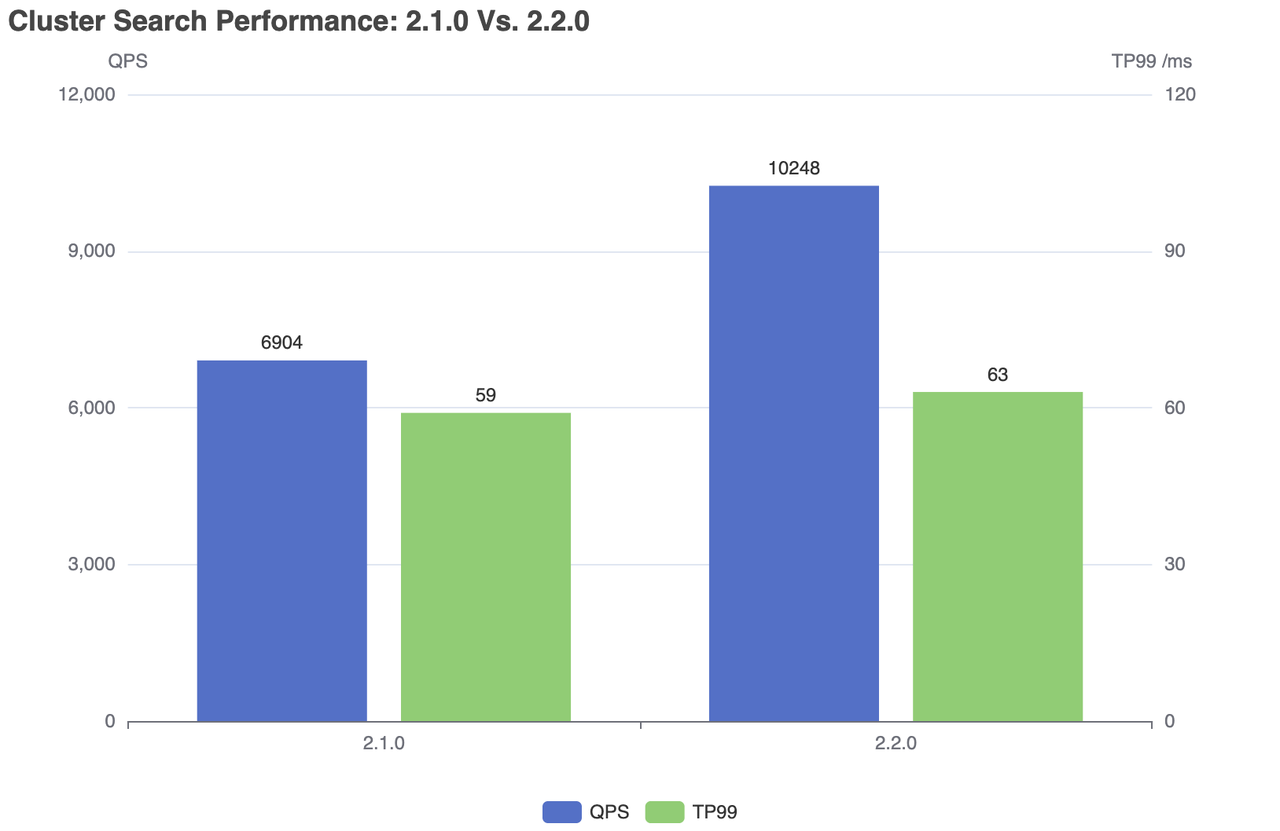 Производительность кластерного поиска
Производительность кластерного поиска
Автономный
Конфигурации серверов (автономные)
yaml standalone: replicas: 1 resources: limits: cpu: "12.0" memory: 16Gi requests: cpu: "12.0" memory: 16Gi
Производительность поиска
| Milvus | QPS | RT(TP99) / мс | RT(TP50) / мс | отказ/с |
|---|---|---|---|---|
| 2.1.0 | 4287 | 104 | 76 | 0 |
| 2.2.0 | 7522 | 127 | 79 | 0 |
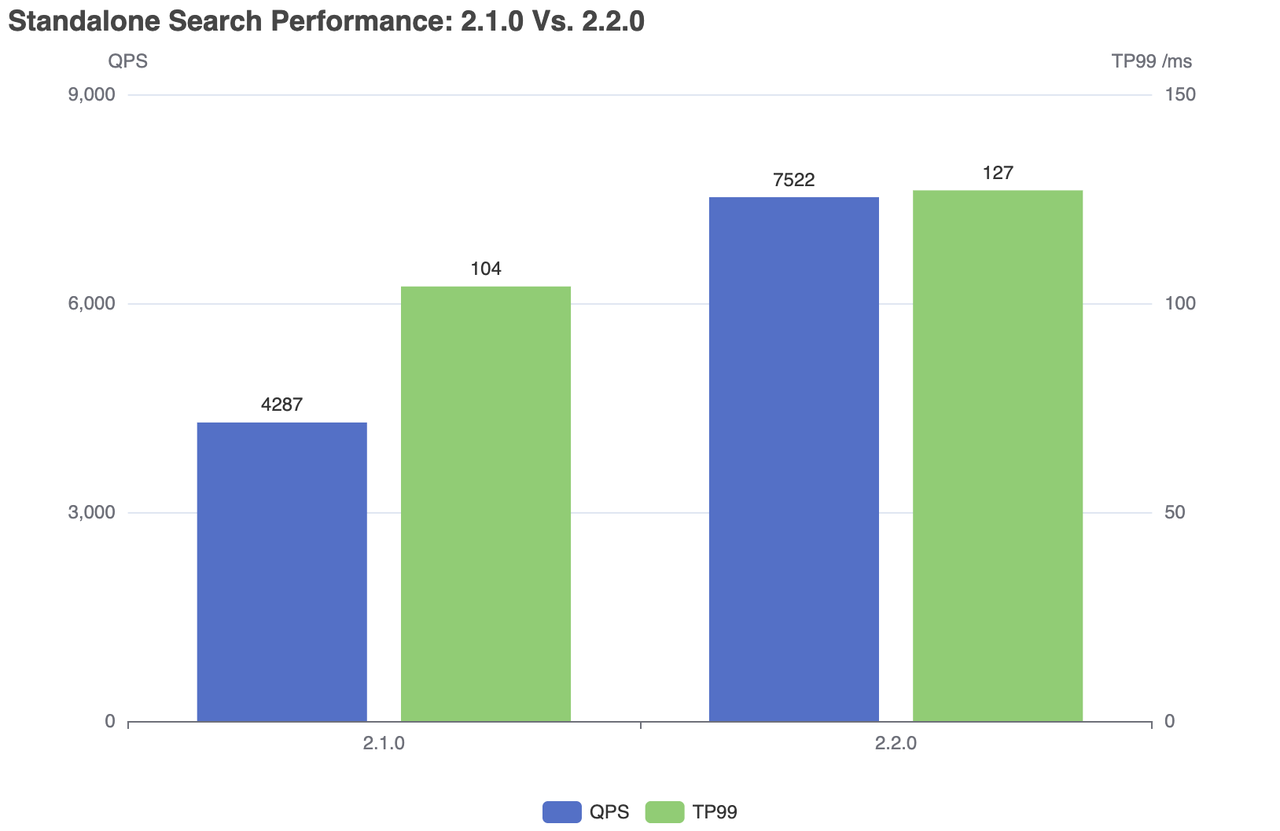 Производительность автономного поиска
Производительность автономного поиска
Milvus 2.2.0 Масштабирование
Увеличьте количество процессорных ядер в одном Querynode, чтобы проверить возможность масштабирования.
Конфигурации серверов (кластер)
yaml queryNode: replicas: 1 resources: limits: cpu: "8.0" /"12.0" /"16.0" /"32.0" memory: 8Gi requests: cpu: "8.0" /"12.0" /"16.0" /"32.0" memory: 8Gi
Производительность поиска
| Ядра процессора | Количество одновременных | QPS | RT(TP99) / мс | RT(TP50) / мс | отказ/с |
|---|---|---|---|---|---|
| 8 | 500 | 7153 | 127 | 83 | 0 |
| 12 | 300 | 10248 | 63 | 24 | 0 |
| 16 | 600 | 14135 | 85 | 42 | 0 |
| 32 | 600 | 20281 | 63 | 28 | 0 |
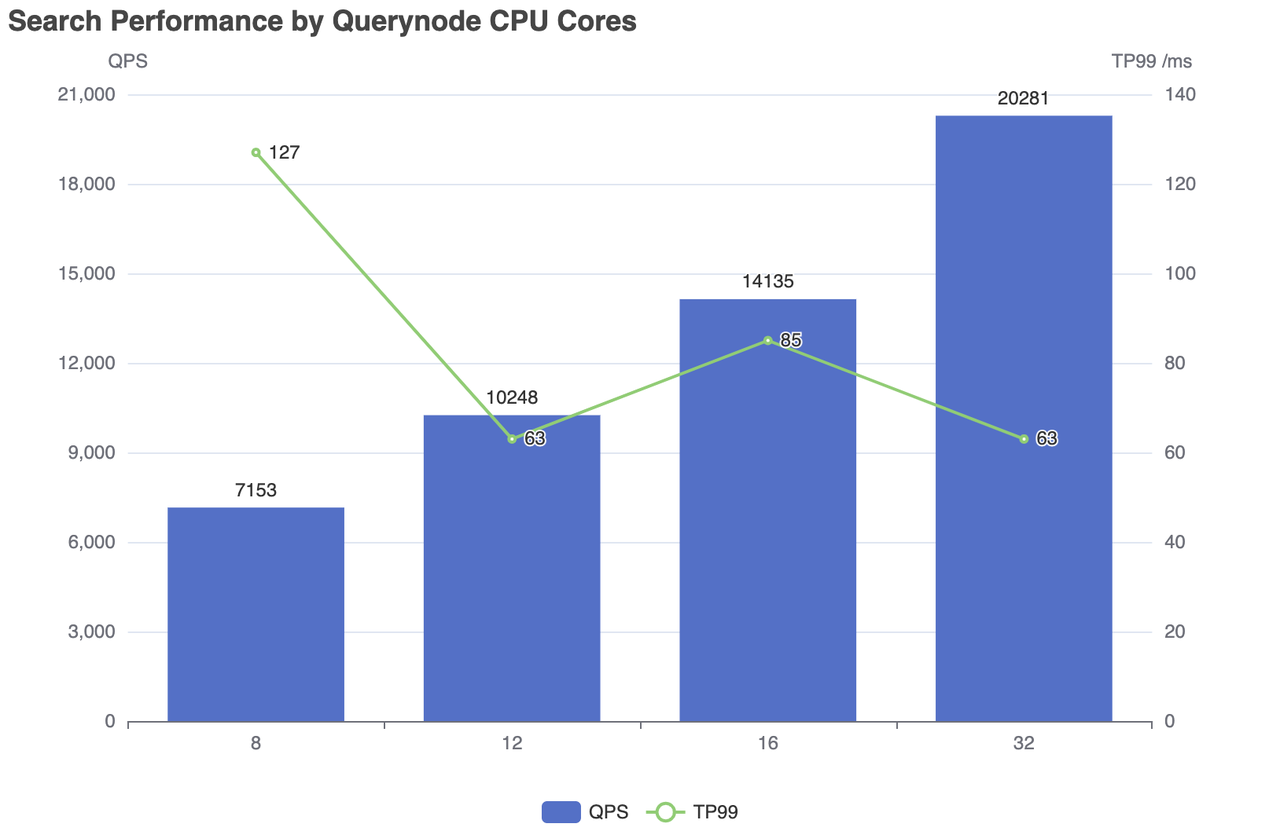 Производительность поиска по процессорным ядрам Querynode
Производительность поиска по процессорным ядрам Querynode
Milvus 2.2.0 Масштабирование
Расширьте количество реплик с помощью большего числа Querynodes, чтобы проверить возможность масштабирования.
Примечание: количество Querynodes равно replica_number при загрузке коллекции.
Конфигурации сервера (кластера)
yaml queryNode: replicas: 1 / 2 / 4 / 8 resources: limits: cpu: "8.0" memory: 8Gi requests: cpu: "8.0" memory: 8Gi
| Реплики | Количество одновременных | QPS | RT(TP99) / мс | RT(TP50) / мс | отказ/с |
|---|---|---|---|---|---|
| 1 | 500 | 7153 | 127 | 83 | 0 |
| 2 | 500 | 15903 | 105 | 27 | 0 |
| 4 | 800 | 19281 | 109 | 40 | 0 |
| 8 | 1200 | 30655 | 93 | 38 | 0 |
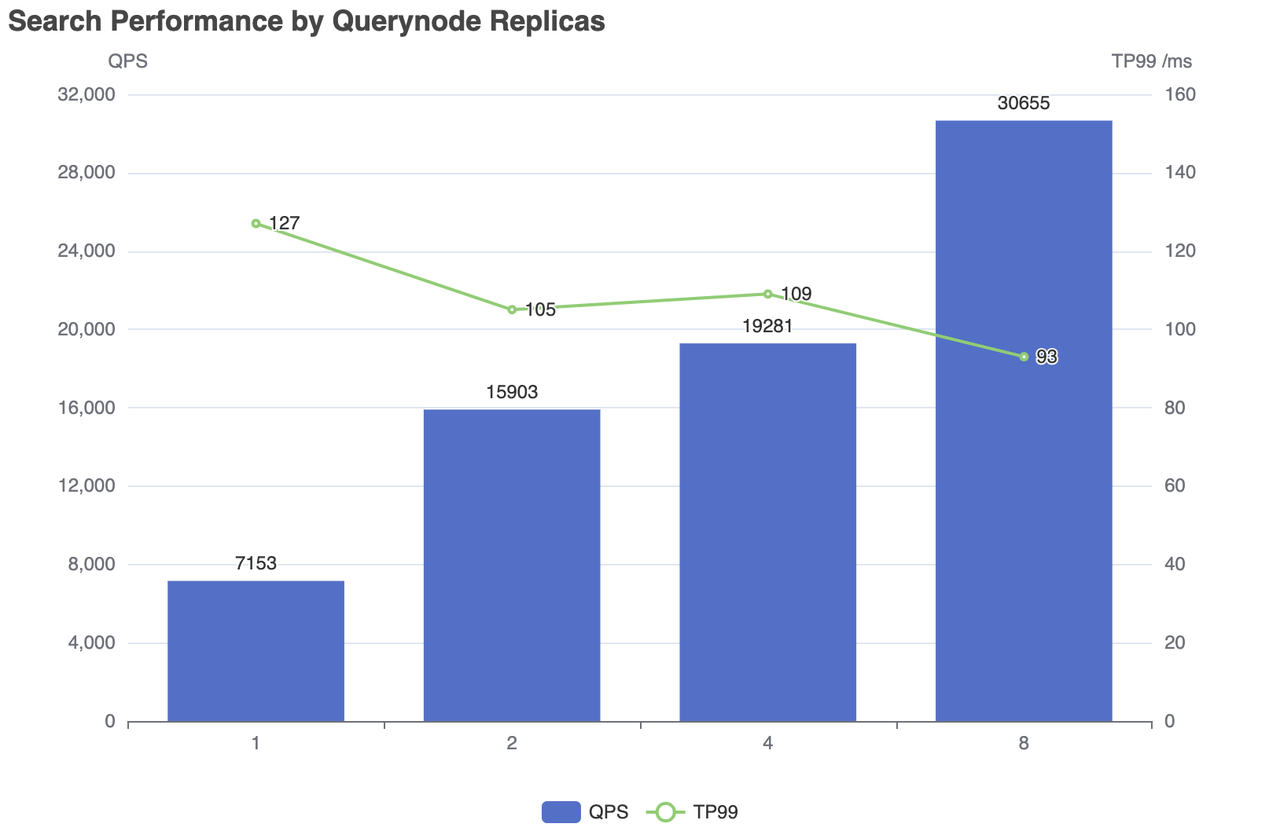 Производительность поиска по репликам Querynode
Производительность поиска по репликам Querynode
Что дальше
- Попробуйте самостоятельно выполнить эталонные тесты Milvus 2.2.0, обратившись к этому руководству, за исключением того, что в данном руководстве следует использовать Milvus 2.2 и Pymilvus 2.2.