Relatório de testes de referência do Milvus 2.2
Este relatório mostra os principais resultados dos testes do Milvus 2.2.0. O seu objetivo é fornecer uma imagem do desempenho de pesquisa do Milvus 2.2.0, especialmente no que diz respeito à capacidade de aumentar e diminuir a escala.

Recentemente, efectuámos um teste de referência em relação ao Milvus 2.2.3 e obtivemos os seguintes resultados principais:
- Uma redução de 2,5x na latência de pesquisa
- Um aumento de 4,5x no QPS
- Pesquisa de similaridade em escala de bilhões com pouca degradação de desempenho
- Escalabilidade linear ao usar várias réplicas
Para obter detalhes, consulte este whitepaper e o código de teste de benchmark relacionado.
Resumo
- Em comparação com o Milvus 2.1, o QPS do Milvus 2.2.0 aumenta mais de 48% no modo de cluster e mais de 75% no modo autónomo.
- O Milvus 2.2.0 tem uma capacidade impressionante de escalar para cima e para fora:
- O QPS aumenta linearmente ao expandir os núcleos da CPU de 8 para 32.
- O QPS aumenta linearmente quando se expandem as réplicas Querynode de 1 para 8.
Terminologia
Clique para ver os detalhes dos termos usados no teste
Termo
Descrição
nq
Número de vectores a pesquisar num pedido de pesquisa
topk
Número de vectores mais próximos a obter para cada vetor (em nq) num pedido de pesquisa
ef
Um parâmetro de pesquisa específico do índice HNSW
RT
Tempo de resposta desde o envio do pedido até à receção da resposta
QPS
Número de pedidos de pesquisa que são processados com êxito por segundo
Ambiente de teste
Todos os testes são efectuados nos seguintes ambientes.
Ambiente de hardware
| Hardware | Especificação |
|---|---|
| CPU | CPU Intel® Xeon® Gold 6226R a 2,90GHz |
| Memória | 16*\32 GB RDIMM, 3200 MT/s |
| SSD | SATA 6 Gbps |
Ambiente de software
| Software | Versão do software |
|---|---|
| Milvus | v2.2.0 |
| Milvus GO SDK | v2.2.0 |
Esquema de implantação
- As instâncias do Milvus (autónomas ou em cluster) são implementadas através do Helm num cluster Kubernetes baseado em máquinas físicas ou virtuais.
- Os diferentes testes variam apenas no número de núcleos de CPU, no tamanho da memória e no número de réplicas (nós de trabalho), o que só se aplica aos clusters Milvus.
- As configurações não especificadas são idênticas às configurações padrão.
- As dependências do Milvus (MinIO, Pulsar e Etcd) armazenam dados no SSD local em cada nó.
- Os pedidos de pesquisa são enviados para as instâncias do Milvus através do Milvus GO SDK.
Conjuntos de dados
O teste usa o conjunto de dados de código aberto SIFT (128 dimensões) do ANN-Benchmarks.
Pipeline de teste
- Inicie uma instância do Milvus pelo Helm com as respectivas configurações de servidor, conforme listado em cada teste.
- Ligue-se à instância do Milvus através do Milvus GO SDK e obtenha os resultados dos testes correspondentes.
- Criar uma coleção.
- Inserir 1 milhão de vectores SIFT. Crie um índice HNSW e configure os parâmetros do índice, definindo
Mpara8eefConstructionpara200. - Carregue a coleção.
- Pesquise com diferentes números concorrentes com os parâmetros de pesquisa
nq=1, topk=1, ef=64, a duração de cada concorrência é de, pelo menos, 1 hora.
Resultados do teste
Milvus 2.2.0 v.s. Milvus 2.1.0
Cluster
Configurações do servidor (cluster)
yaml queryNode: replicas: 1 resources: limits: cpu: "12.0" memory: 8Gi requests: cpu: "12.0" memory: 8Gi
Desempenho da pesquisa
| Milvus | QPS | RT(TP99) / ms | RT(TP50) / ms | falha/s |
|---|---|---|---|---|
| 2.1.0 | 6904 | 59 | 28 | 0 |
| 2.2.0 | 10248 | 63 | 24 | 0 |
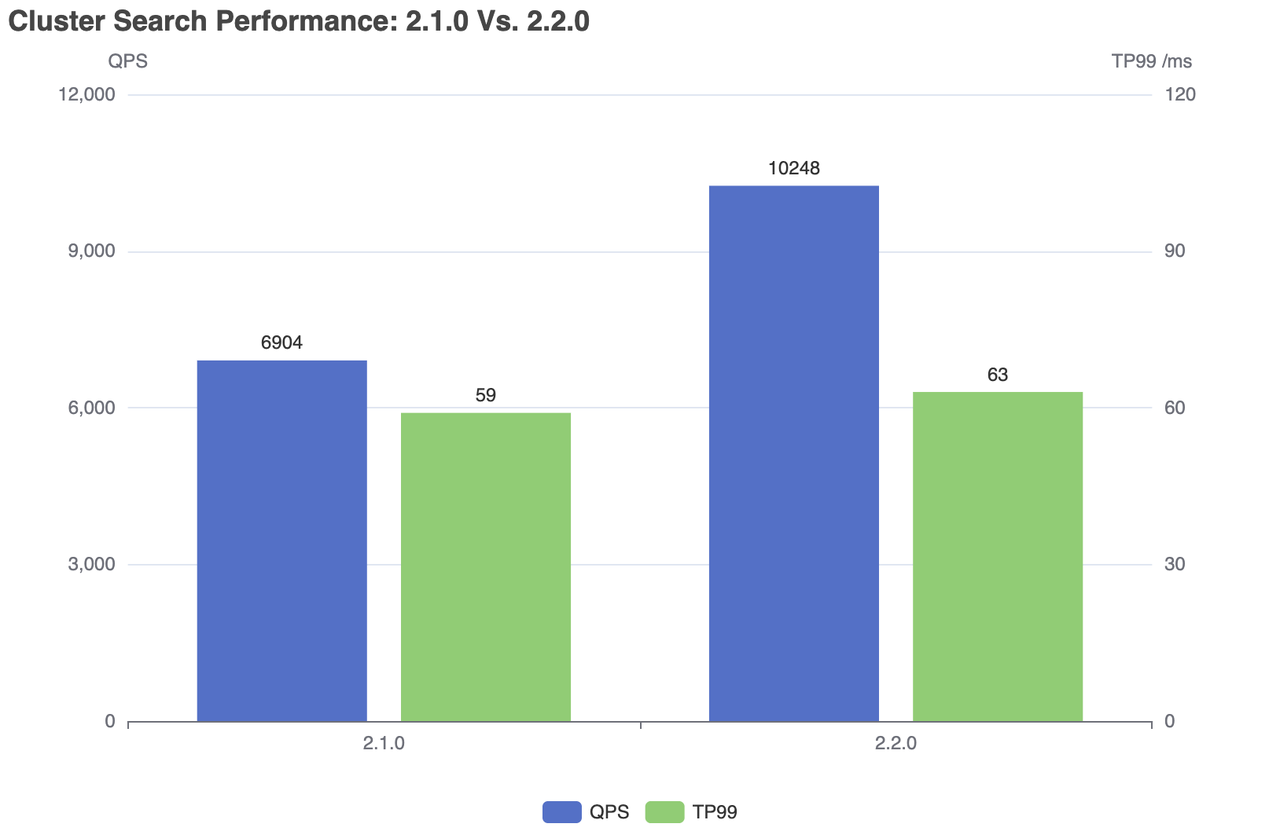 Desempenho da pesquisa em cluster
Desempenho da pesquisa em cluster
Autónomo
Configurações de servidor (autónomo)
yaml standalone: replicas: 1 resources: limits: cpu: "12.0" memory: 16Gi requests: cpu: "12.0" memory: 16Gi
Desempenho da pesquisa
| Milvus | QPS | RT(TP99) / ms | RT(TP50) / ms | falha/s |
|---|---|---|---|---|
| 2.1.0 | 4287 | 104 | 76 | 0 |
| 2.2.0 | 7522 | 127 | 79 | 0 |
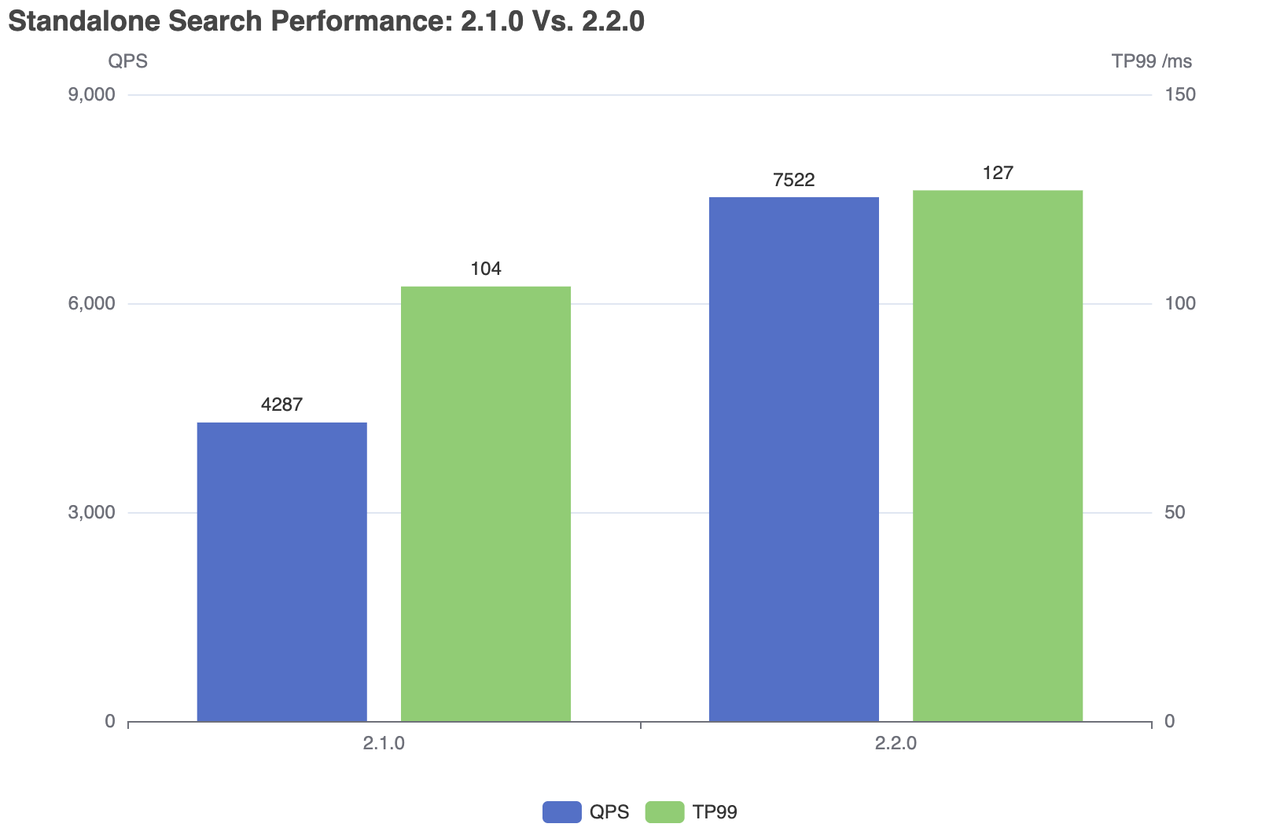 Desempenho da pesquisa autónoma
Desempenho da pesquisa autónoma
Milvus 2.2.0 Aumento de escala
Expanda os núcleos de CPU num Querynode para verificar a capacidade de aumento de escala.
Configurações de servidor (cluster)
yaml queryNode: replicas: 1 resources: limits: cpu: "8.0" /"12.0" /"16.0" /"32.0" memory: 8Gi requests: cpu: "8.0" /"12.0" /"16.0" /"32.0" memory: 8Gi
Desempenho da pesquisa
| Núcleos de CPU | Número simultâneo | QPS | RT(TP99) / ms | RT(TP50) / ms | falha/s |
|---|---|---|---|---|---|
| 8 | 500 | 7153 | 127 | 83 | 0 |
| 12 | 300 | 10248 | 63 | 24 | 0 |
| 16 | 600 | 14135 | 85 | 42 | 0 |
| 32 | 600 | 20281 | 63 | 28 | 0 |
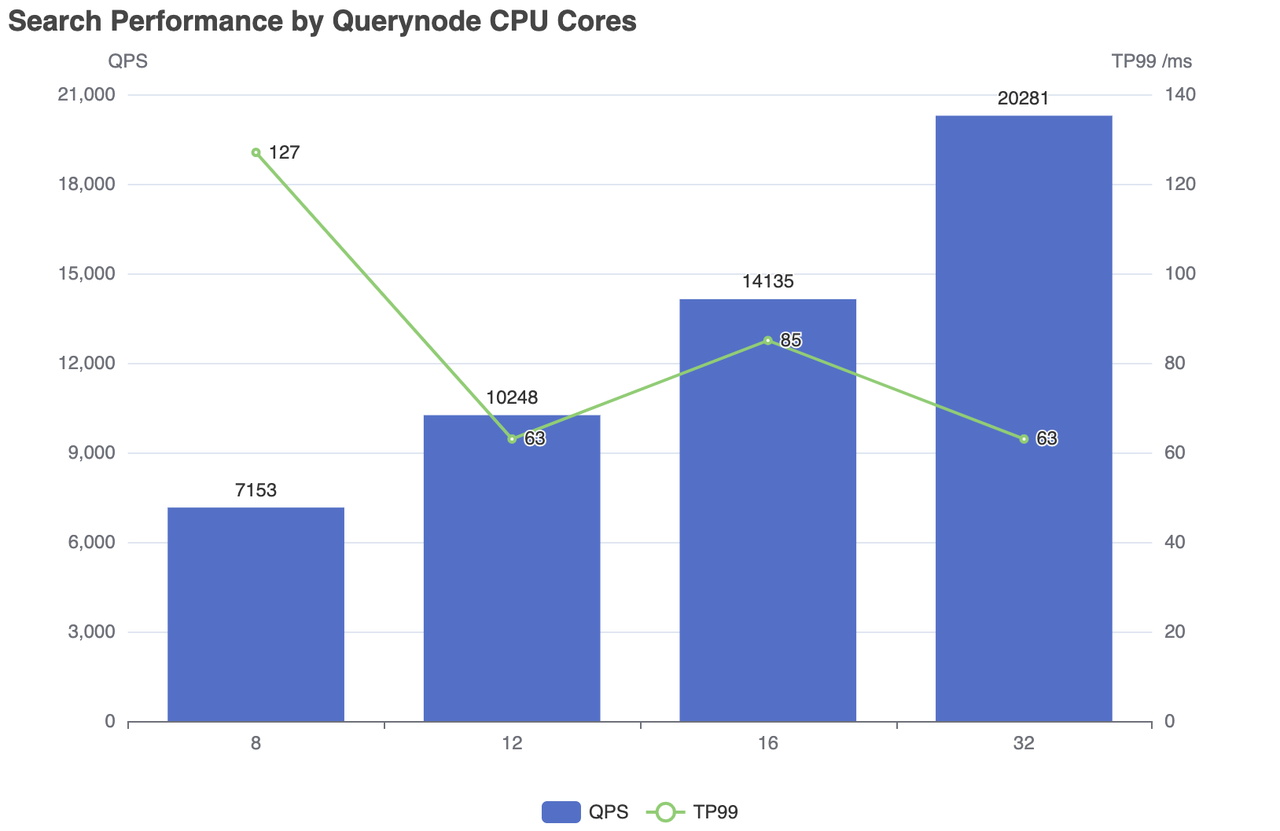 Desempenho de pesquisa por núcleos de CPU Querynode
Desempenho de pesquisa por núcleos de CPU Querynode
Milvus 2.2.0 Expansão
Expanda mais réplicas com mais Querynodes para verificar a capacidade de expansão.
Nota: o número de Querynodes é igual a replica_number ao carregar a coleção.
Configurações do servidor (cluster)
yaml queryNode: replicas: 1 / 2 / 4 / 8 resources: limits: cpu: "8.0" memory: 8Gi requests: cpu: "8.0" memory: 8Gi
| Réplicas | Número simultâneo | QPS | RT(TP99) / ms | RT(TP50) / ms | falha/s |
|---|---|---|---|---|---|
| 1 | 500 | 7153 | 127 | 83 | 0 |
| 2 | 500 | 15903 | 105 | 27 | 0 |
| 4 | 800 | 19281 | 109 | 40 | 0 |
| 8 | 1200 | 30655 | 93 | 38 | 0 |
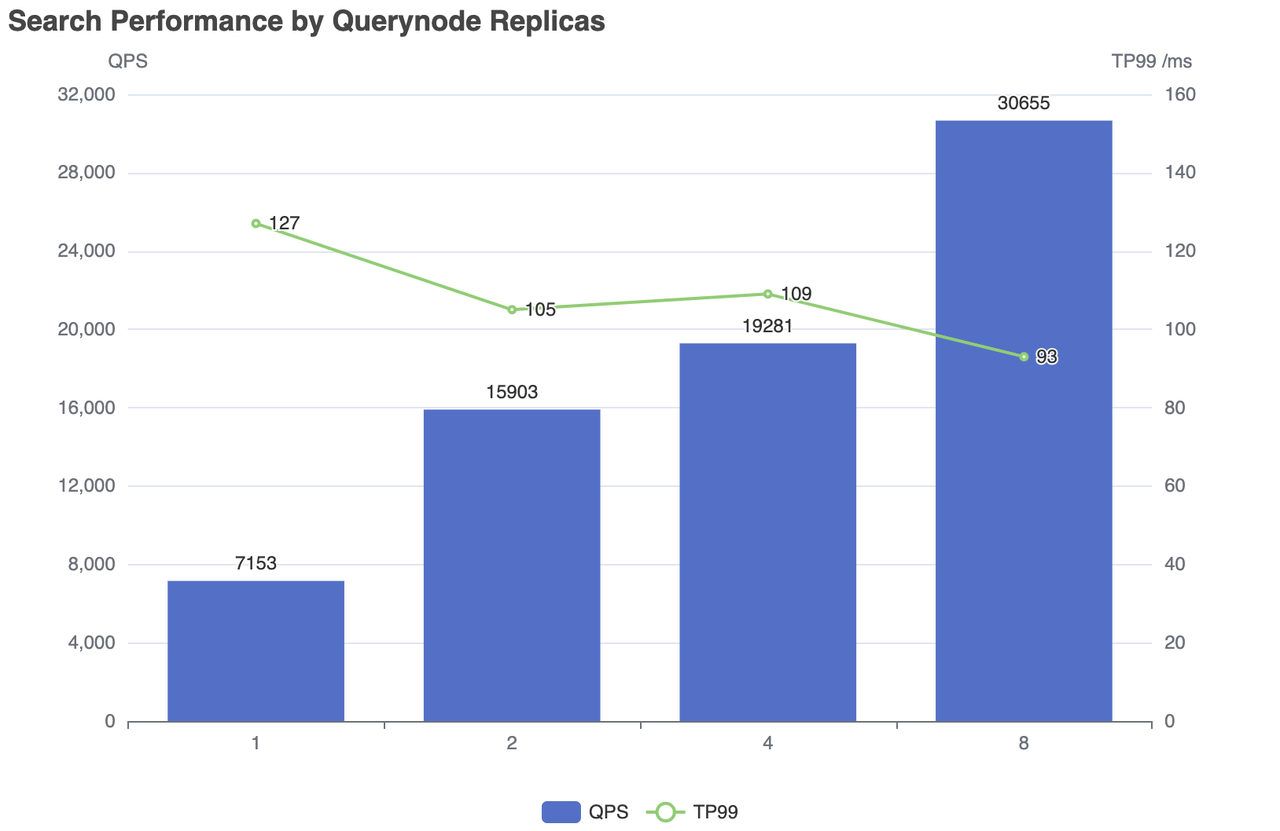 Desempenho da pesquisa por réplicas Querynode
Desempenho da pesquisa por réplicas Querynode
O que vem a seguir
- Tente realizar os testes de benchmark do Milvus 2.2.0 por conta própria, consultando este guia, exceto que você deve usar o Milvus 2.2 e o Pymilvus 2.2 neste guia.