Visão geral da migração Milvus
Reconhecendo as diversas necessidades da base de utilizadores, Milvus expandiu as suas ferramentas de migração não só para facilitar as actualizações das versões anteriores de Milvus 1.x, mas também para permitir a integração perfeita de dados de outros sistemas como Elasticsearch e Faiss. O projeto Milvus-migration foi concebido para colmatar a lacuna entre estes ambientes de dados variados e os últimos avanços da tecnologia Milvus, garantindo que pode aproveitar as funcionalidades e o desempenho melhorados sem problemas.
Migrações suportadas
A ferramenta Milvus-migration suporta uma variedade de caminhos de migração para acomodar diferentes necessidades dos utilizadores:
- Elasticsearch para Milvus 2.x: Permite aos utilizadores migrar dados de ambientes Elasticsearch para tirar partido das capacidades de pesquisa vetorial optimizada do Milvus.
- Faiss para Milvus 2.x: Fornecendo suporte experimental para a transferência de dados do Faiss, uma biblioteca popular para pesquisa eficiente de similaridade.
- Milvus 1.x para Milvus 2.x: Garantir que os dados das versões anteriores sejam transferidos sem problemas para a estrutura mais recente.
- Milvus 2.3.x para Milvus 2.3.x ou superior: Proporcionar um caminho de migração único para os utilizadores que já migraram para a versão 2.3.x.
Caraterísticas
O Milvus-migration foi concebido com caraterísticas robustas para lidar com diversos cenários de migração:
- Múltiplos métodos de interação: Pode efetuar migrações através de uma interface de linha de comandos ou através de uma API Restful, com flexibilidade na forma como as migrações são executadas.
- Suporte para vários formatos de ficheiros e armazenamento em nuvem: A ferramenta Milvus-migration pode lidar com dados armazenados em ficheiros locais, bem como em soluções de armazenamento em nuvem, como S3, OSS e GCP, garantindo uma ampla compatibilidade.
- Tratamento de tipos de dados: A Milvus-migration é capaz de lidar com dados vectoriais e campos escalares, tornando-a uma escolha versátil para diferentes necessidades de migração de dados.
Arquitetura
A arquitetura do Milvus-migration foi estrategicamente concebida para facilitar processos eficientes de transmissão, análise e escrita de dados, permitindo capacidades de migração robustas em várias fontes de dados.
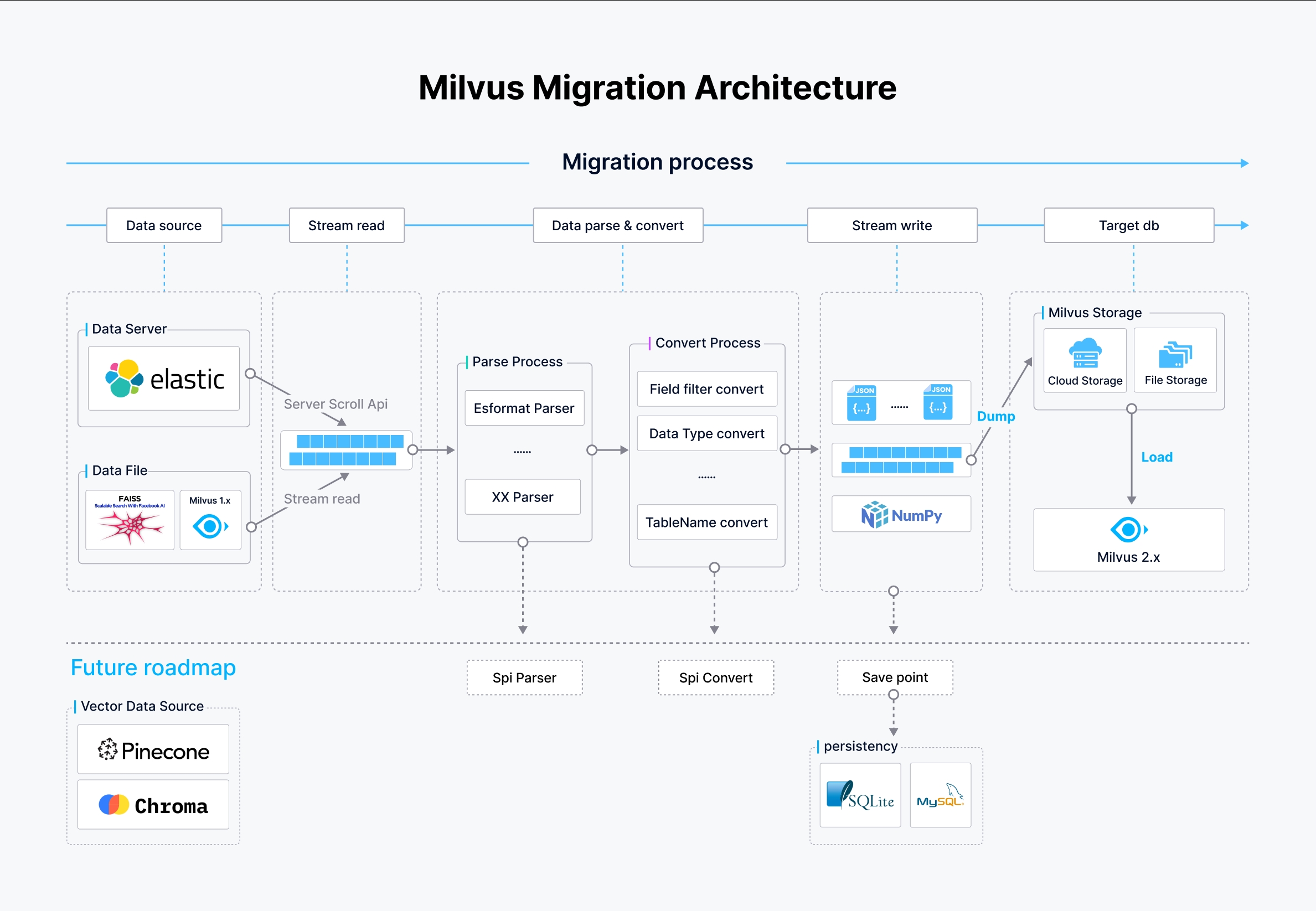 Arquitetura de Milvus-migration
Arquitetura de Milvus-migration
Na figura anterior:
- Fonte de dados: O Milvus-migration suporta várias fontes de dados, incluindo o Elasticsearch através da API scroll, ficheiros de dados de armazenamento local ou na nuvem e bases de dados Milvus 1.x. Estas são acedidas e lidas de uma forma simplificada para iniciar o processo de migração.
- Pipeline de fluxo:
- Processo de análise: Os dados das fontes são analisados de acordo com o seu formato. Por exemplo, para uma fonte de dados do Elasticsearch, é utilizado um analisador de formato do Elasticsearch, enquanto outros formatos utilizam os respectivos analisadores. Este passo é crucial para transformar os dados em bruto num formato estruturado que pode ser processado posteriormente.
- Processo de conversão: Após a análise, os dados são submetidos a um processo de conversão em que os campos são filtrados, os tipos de dados são convertidos e os nomes das tabelas são ajustados de acordo com o esquema Milvus 2.x pretendido. Isto garante que os dados estão em conformidade com a estrutura e os tipos esperados no Milvus.
- Escrita e carregamento de dados:
- Escrever dados: Os dados processados são escritos em ficheiros JSON ou NumPy intermédios, prontos a serem carregados no Milvus 2.x.
- Carregar dados: Os dados são finalmente carregados no Milvus 2.x utilizando a operação BulkInsert, que grava de forma eficiente grandes volumes de dados nos sistemas de armazenamento do Milvus, quer sejam baseados na nuvem ou em armazenamento de ficheiros.
Planos para o futuro
A equipa de desenvolvimento está empenhada em melhorar o Milvus-migration com funcionalidades como:
- Suporte para mais fontes de dados: Planos para alargar o suporte a bases de dados e sistemas de ficheiros adicionais, tais como Pinecone, Chroma, Qdrant. Se precisar de suporte para uma fonte de dados específica, envie sua solicitação por meio deste link de problema do GitHub.
- Simplificação de comandos: Esforços para simplificar o processo de comando para facilitar a execução.
- Analisador / conversãode SPI: A arquitetura espera incluir ferramentas de Interface de Fornecedor de Serviços (SPI) para análise e conversão. Estas ferramentas permitem implementações personalizadas que os utilizadores podem ligar ao processo de migração para tratar formatos de dados específicos ou regras de conversão.
- Retomada do ponto de verificação: Permite que as migrações sejam retomadas a partir do último ponto de controlo para aumentar a fiabilidade e a eficiência em caso de interrupções. Serão criados pontos de salvaguarda para garantir a integridade dos dados e são armazenados em bases de dados como o SQLite ou o MySQL para acompanhar o progresso do processo de migração.