스칼라 인덱스
Milvus는 스칼라 필드와 벡터 필드를 결합한 필터링된 검색을 지원합니다. 스칼라 필드와 관련된 검색의 효율성을 높이기 위해 Milvus는 버전 2.1.0부터 스칼라 필드 인덱싱을 도입했습니다. 이 문서에서는 Milvus의 스칼라 필드 인덱싱에 대한 개요를 제공하여 그 중요성과 구현에 대한 이해를 돕습니다.
개요
Milvus에서 벡터 유사도 검색을 수행한 후에는 논리 연산자를 사용하여 스칼라 필드를 부울 표현식으로 구성할 수 있습니다.
이러한 부울 식이 포함된 검색 요청을 받으면 Milvus는 부울 식을 추상 구문 트리(AST)로 구문 분석하여 속성 필터링을 위한 물리적 계획을 생성합니다. 그런 다음 Milvus는 각 세그먼트에 물리적 계획을 적용하여 필터링 결과인 비트셋을 생성하고 그 결과를 벡터 검색 매개변수로 포함시켜 검색 범위를 좁힙니다. 이 경우 벡터 검색의 속도는 속성 필터링의 속도에 크게 좌우됩니다.
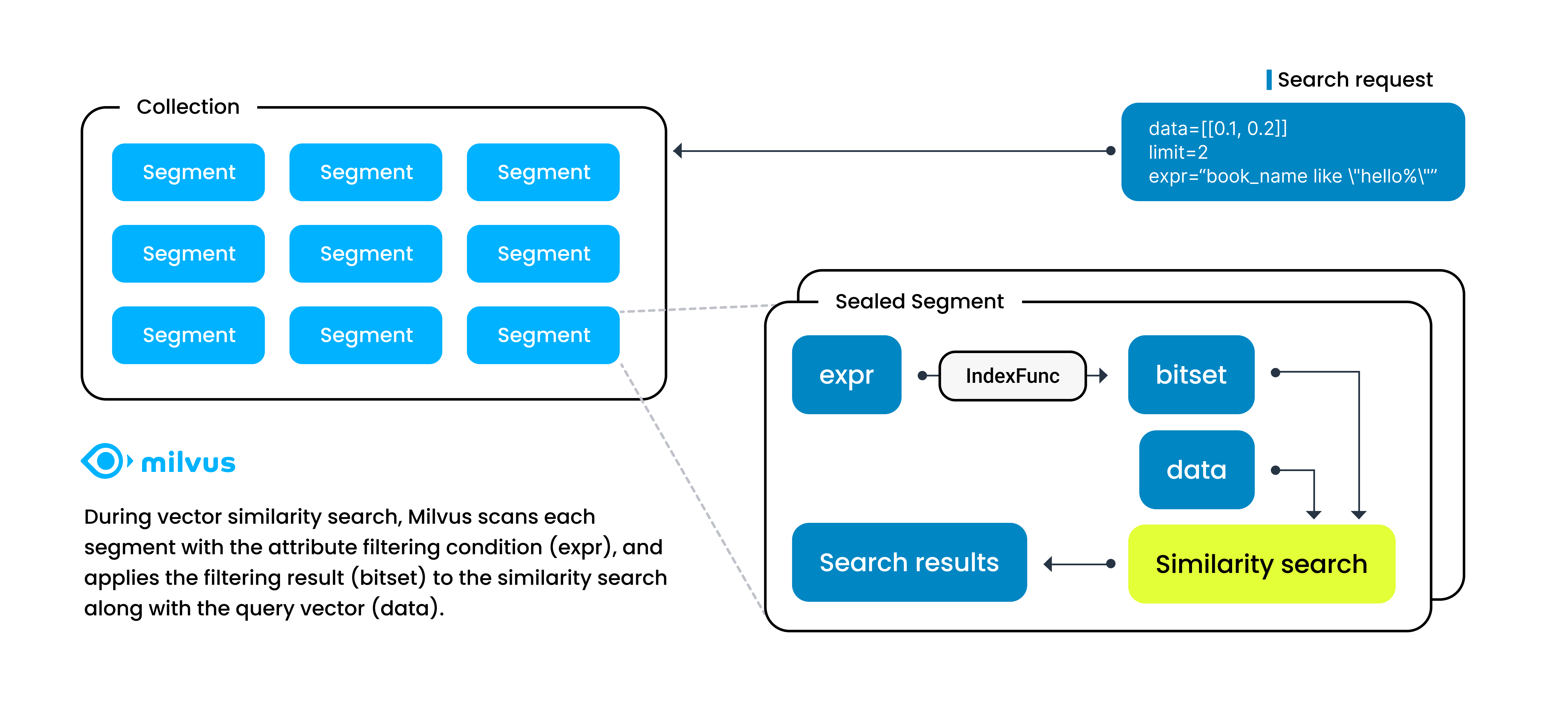 세그먼트의 속성 필터링
세그먼트의 속성 필터링
스칼라 필드 인덱싱은 정보 검색을 가속화하기 위해 스칼라 필드 값을 특정 방식으로 정렬하여 속성 필터링의 속도를 보장하는 방법입니다.
스칼라 필드 인덱싱 알고리즘
Milvus는 스칼라 필드 인덱싱 알고리즘을 통해 낮은 메모리 사용량, 높은 필터링 효율성, 짧은 로딩 시간을 달성하는 것을 목표로 합니다. 이러한 알고리즘은 자동 인덱싱과 역 인덱싱의 두 가지 주요 유형으로 분류됩니다.
자동 인덱싱
Milvus는 인덱스 유형을 수동으로 선택할 필요가 없도록 AUTOINDEX 옵션을 제공합니다. create_index 메서드를 호출할 때 index_type 을 지정하지 않으면 Milvus는 데이터 유형에 따라 가장 적합한 인덱스 유형을 자동으로 선택합니다.
다음 표에는 Milvus가 지원하는 데이터 유형과 해당 자동 인덱싱 알고리즘이 나와 있습니다.
| 데이터 유형 | 자동 인덱싱 알고리즘 |
|---|---|
| VARCHAR | 역 인덱스 |
| INT8 | 반전 인덱스 |
| INT16 | 반전된 인덱스 |
| INT32 | 반전 인덱스 |
| INT64 | 반전 인덱스 |
| FLOAT | 반전 인덱스 |
| DOUBLE | 반전 인덱스 |
반전 인덱싱
반전 인덱싱은 인덱스 매개변수를 수동으로 지정하여 스칼라 필드에 대한 인덱스를 생성하는 유연한 방법을 제공합니다. 이 방법은 포인트 쿼리, 패턴 일치 쿼리, 전체 텍스트 검색, JSON 검색, 부울 검색, 접두사 일치 쿼리 등 다양한 시나리오에서 잘 작동합니다.
Milvus에서 구현된 반전 인덱스는 전체 텍스트 검색 엔진 라이브러리인 Tantivy에 의해 구동됩니다. Tantivy는 Milvus의 반전 인덱싱이 효율적이고 빠르도록 보장합니다.
반전 색인에는 용어 사전과 반전 목록이라는 두 가지 주요 구성 요소가 있습니다. 용어 사전에는 토큰화된 모든 단어가 알파벳순으로 정렬되어 있고, 반전 목록에는 각 단어가 나타나는 문서 목록이 포함되어 있습니다. 이 설정은 무차별 대입 검색보다 포인트 쿼리와 범위 쿼리를 훨씬 더 빠르고 효율적으로 만듭니다.
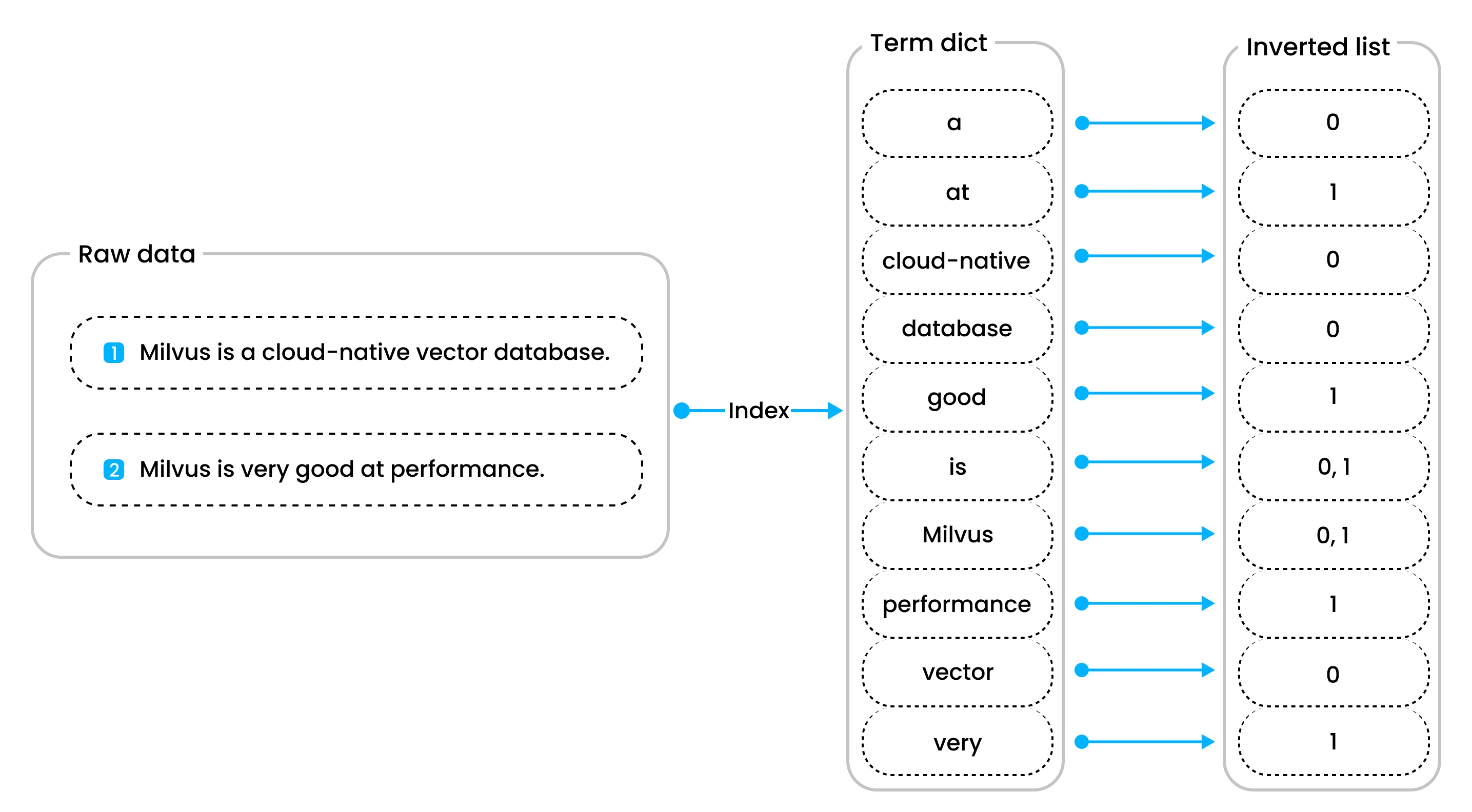 반전 색인 다이어그램
반전 색인 다이어그램
반전 인덱스 사용의 장점은 다음 작업에서 특히 두드러집니다:
- 포인트 쿼리: 예를 들어, Milvus라는 단어가 포함된 문서를 검색할 때, 용어 사전에 Milvus가 있는지 확인하는 것으로 프로세스가 시작됩니다. 찾을 수 없으면 해당 단어가 포함된 문서가 없는 것입니다. 그러나 발견되면 Milvus와 관련된 반전된 목록이 검색되어 해당 단어가 포함된 문서가 표시됩니다. 이 방법은 정렬된 용어 사전이 Milvus라는 단어를 찾는 데 걸리는 시간을 크게 줄여주기 때문에 백만 개의 문서를 무차별적으로 검색하는 것보다 훨씬 더 효율적입니다.
- 범위 쿼리: 매우보다 알파벳순으로 큰 단어가 포함된 문서를 찾는 것과 같은 범위 쿼리의 효율성도 정렬된 용어 사전을 통해 향상됩니다. 이 접근 방식은 무차별 검색보다 더 효율적이므로 더 빠르고 정확한 결과를 제공합니다.
테스트 결과
Milvus의 스칼라 인덱스가 제공하는 성능 향상을 입증하기 위해, 원시 데이터에서 역 인덱싱과 무차별 대입 검색을 사용하는 여러 표현식의 성능을 비교하는 실험이 수행되었습니다.
이 실험에서는 반전 인덱스와 무차별 대입 검색의 두 가지 조건에서 다양한 표현식을 테스트했습니다. 공정성을 보장하기 위해 매번 동일한 컬렉션을 사용하여 테스트 전반에 걸쳐 동일한 데이터 분포를 유지했습니다. 각 테스트 전에 컬렉션을 해제하고 인덱스를 삭제한 후 다시 구축했습니다. 또한 각 테스트 전에 콜드 데이터와 핫 데이터의 영향을 최소화하기 위해 웜 쿼리를 수행했으며, 정확성을 보장하기 위해 각 쿼리를 여러 번 실행했습니다.
100만 개의 레코드로 구성된 데이터 세트의 경우, 반전 인덱스를 사용하면 포인트 쿼리의 성능이 최대 30배까지 향상될 수 있습니다. 더 큰 데이터 세트의 경우 성능 향상은 훨씬 더 커질 수 있습니다.
성능 권장 사항
스칼라 필드 인덱싱에서 Milvus의 기능을 최대한 활용하고 벡터 유사도 검색에서 그 힘을 발휘하려면, 보유한 데이터를 기반으로 필요한 메모리 크기를 추정하는 모델이 필요할 수 있습니다.
다음 표에는 Milvus가 지원하는 모든 데이터 유형에 대한 추정 함수가 나와 있습니다.
숫자 필드
데이터 유형 메모리 추정 함수(MB) INT8 numOfRows * 12 / 1024 / 1024 INT16 numOfRows * 12 / 1024 / 1024 INT32 numOfRows * 12 / 1024 / 1024 INT64 numOfRows * 24 / 1024 / 1024 FLOAT32 numOfRows * 12 / 1024 / 1024 DOUBLE numOfRows * 24 / 1024 / 1024 문자열 필드
문자열 길이 메모리 추정 함수(MB) (0, 8] numOfRows * 128 / 1024 / 1024 (8, 16] numOfRows * 144 / 1024 / 1024 (16, 32] numOfRows * 160 / 1024 / 1024 (32, 64] numOfRows * 192 / 1024 / 1024 (64, 128] numOfRows * 256 / 1024 / 1024 (128, 65535] numOfRows * strLen * 1.5 / 1024 / 1024
다음 작업
스칼라 필드를 색인하려면 스칼라에 색인 만들기를 참조하세요.
위에서 언급한 관련 용어와 규칙에 대해 자세히 알아보려면 다음을 읽어보세요.