Milvus 마이그레이션 개요
사용자 기반의 다양한 요구를 인식한 Milvus는 이전 Milvus 1.x 버전으로부터의 업그레이드를 용이하게 할 뿐만 아니라 Elasticsearch 및 Faiss와 같은 다른 시스템의 데이터도 원활하게 통합할 수 있도록 마이그레이션 도구를 확장했습니다. Milvus 마이그레이션 프로젝트는 이러한 다양한 데이터 환경과 Milvus 기술의 최신 발전 사이의 격차를 해소하여 향상된 기능과 성능을 원활하게 활용할 수 있도록 설계되었습니다.
지원되는 마이그레이션
Milvus 마이그레이션 도구는 다양한 사용자 요구 사항을 수용하기 위해 다양한 마이그레이션 경로를 지원합니다:
- Elasticsearch에서 Milvus 2.x로: 사용자가 Milvus의 최적화된 벡터 검색 기능을 활용하기 위해 Elasticsearch 환경에서 데이터를 마이그레이션할 수 있습니다.
- Faiss에서 Milvus 2.x로: 효율적인 유사도 검색을 위해 널리 사용되는 라이브러리인 Faiss에서 데이터 전송을 위한 실험적 지원을 제공합니다.
- Milvus 1.x에서 Milvus 2.x로: 이전 버전의 데이터가 최신 프레임워크로 원활하게 전환되도록 보장합니다.
- Milvus 2.3.x에서 Milvus 2.3.x 이상으로: 이미 2.3.x로 마이그레이션한 사용자를 위한 일회성 마이그레이션 경로를 제공합니다.
특징
Milvus 마이그레이션은 다양한 마이그레이션 시나리오를 처리할 수 있는 강력한 기능으로 설계되었습니다:
- 다양한 상호 작용 방법: 명령줄 인터페이스 또는 Restful API를 통해 마이그레이션을 수행할 수 있으며, 마이그레이션 실행 방식도 유연하게 선택할 수 있습니다.
- 다양한 파일 형식 및 클라우드 스토리지 지원: Milvus 마이그레이션 도구는 로컬 파일은 물론 S3, OSS, GCP와 같은 클라우드 스토리지 솔루션에 저장된 데이터도 처리할 수 있어 폭넓은 호환성을 보장합니다.
- 데이터 유형 처리: Milvus-migration은 벡터 데이터와 스칼라 필드를 모두 처리할 수 있어 다양한 데이터 마이그레이션 요구사항에 따라 다용도로 사용할 수 있습니다.
아키텍처
Milvus-migration의 아키텍처는 효율적인 데이터 스트리밍, 구문 분석 및 쓰기 프로세스를 촉진하도록 전략적으로 설계되어 다양한 데이터 소스에서 강력한 마이그레이션 기능을 지원합니다.
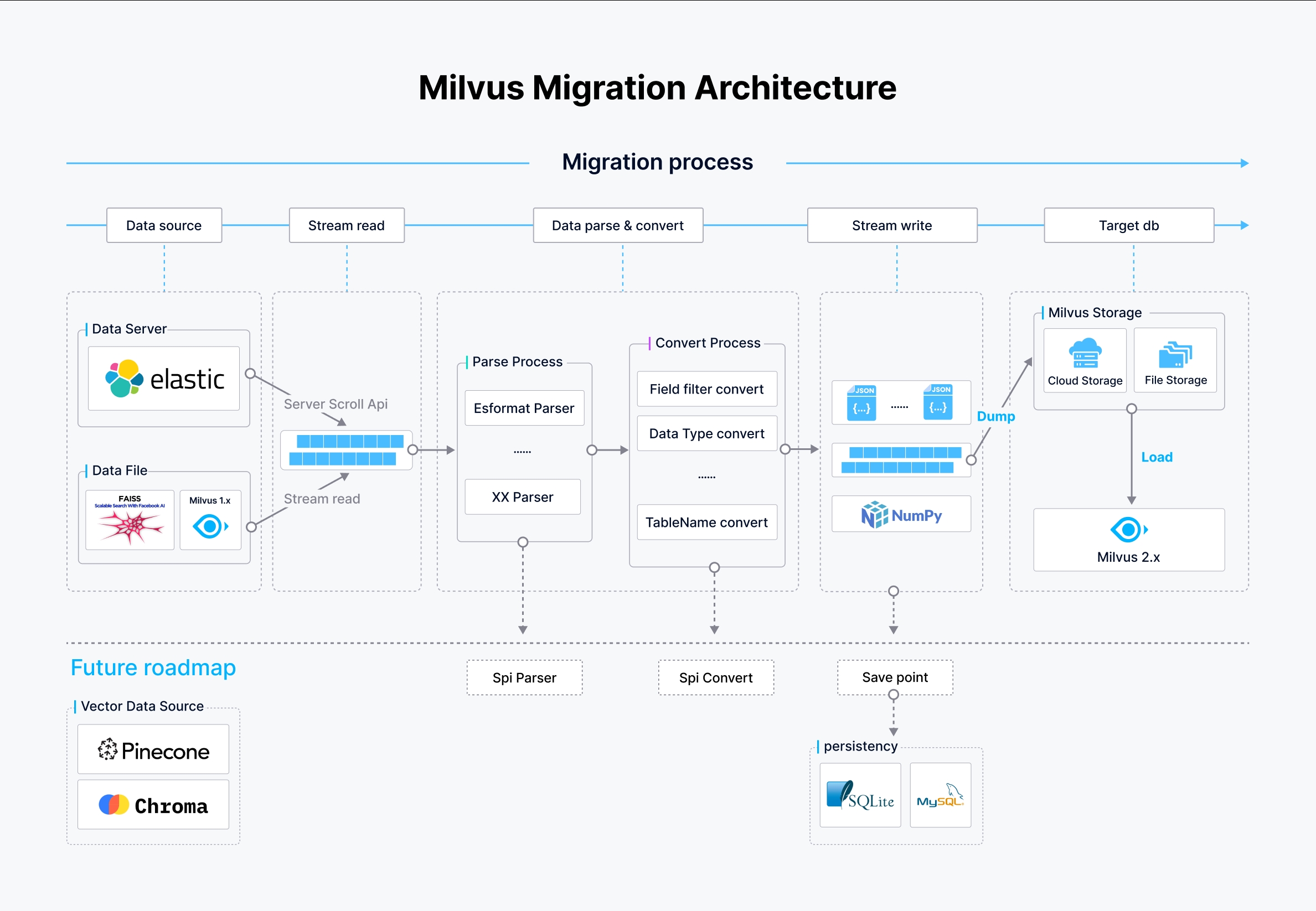 Milvus 마이그레이션 아키텍처
Milvus 마이그레이션 아키텍처
앞의 그림에서:
- 데이터 소스: Milvus-migration은 스크롤 API, 로컬 또는 클라우드 스토리지 데이터 파일, Milvus 1.x 데이터베이스를 통해 Elasticsearch를 비롯한 여러 데이터 소스를 지원합니다. 이러한 데이터 소스는 간소화된 방식으로 액세스하고 읽어서 마이그레이션 프로세스를 시작합니다.
- 스트림 파이프라인:
- 구문 분석 프로세스: 소스의 데이터가 형식에 따라 구문 분석됩니다. 예를 들어, Elasticsearch의 데이터 소스의 경우 Elasticsearch 형식 파서가 사용되고 다른 형식은 각각의 파서를 사용합니다. 이 단계는 원시 데이터를 추가 처리가 가능한 구조화된 형식으로 변환하는 데 매우 중요합니다.
- 변환 프로세스: 구문 분석 후 데이터는 대상 Milvus 2.x 스키마에 따라 필드를 필터링하고, 데이터 유형을 변환하고, 테이블 이름을 조정하는 변환 과정을 거칩니다. 이를 통해 데이터가 Milvus에서 예상되는 구조와 유형을 준수하도록 보장합니다.
- 데이터 쓰기 및 로드:
- 데이터 쓰기: 처리된 데이터는 중간 JSON 또는 NumPy 파일에 기록되어 Milvus 2.x에 로드할 준비가 됩니다.
- 데이터 로드: 클라우드 기반 또는 파일 저장소 중 하나를 선택해 대용량의 데이터를 Milvus 스토리지 시스템에 효율적으로 쓰는 BulkInsert 작업을 통해 데이터가 최종적으로 Milvus 2.x에 로드됩니다.
향후 계획
개발팀은 다음과 같은 기능을 통해 Milvus 마이그레이션을 개선하기 위해 최선을 다하고 있습니다:
- 더 많은 데이터 소스 지원: Pinecone, Chroma, Qdrant와 같은 추가 데이터베이스 및 파일 시스템으로 지원을 확장할 계획입니다. 특정 데이터 소스에 대한 지원이 필요한 경우, 이 GitHub 이슈 링크를 통해 요청을 제출하세요.
- 명령 간소화: 더 쉬운 실행을 위해 명령 프로세스를 간소화하기 위한 노력입니다.
- SPI 파서/변환: 이 아키텍처에는 구문 분석과 변환을 위한 서비스 공급자 인터페이스(SPI) 도구가 포함될 예정입니다. 이러한 도구를 사용하면 사용자가 마이그레이션 프로세스에 연결하여 특정 데이터 형식이나 변환 규칙을 처리할 수 있는 사용자 정의 구현이 가능합니다.
- 체크포인트 재개: 마지막 체크포인트에서 마이그레이션을 재개할 수 있도록 설정하면 중단 시 안정성과 효율성을 높일 수 있습니다. 데이터 무결성을 보장하기 위해 저장 지점이 생성되며 마이그레이션 프로세스의 진행 상황을 추적하기 위해 SQLite 또는 MySQL과 같은 데이터베이스에 저장됩니다.