Milvusマイグレーション概要
Milvusはユーザーベースの多様なニーズを認識し、Milvus 1.x以前のバージョンからのアップグレードを容易にするだけでなく、Elasticsearchや Faissのような他のシステムからのシームレスなデータ統合を可能にするためにマイグレーションツールを拡張しました。Milvus-migrationプロジェクトは、これらの多様なデータ環境とMilvusテクノロジーの最新の進歩とのギャップを埋めるように設計されており、お客様が改善された機能とパフォーマンスをシームレスに利用できることを保証します。
対応マイグレーション
Milvus-migrationツールは、様々なユーザのニーズに対応するため、様々な移行経路をサポートしています:
- ElasticsearchからMilvus 2.xへの移行:ElasticsearchからMilvus 2.xへの移行:Elasticsearch環境からデータを移行し、Milvusの最適化されたベクトル検索機能を利用することができます。
- FaissからMilvus 2.xへ:効率的な類似検索のための一般的なライブラリであるFaissからのデータ移行を実験的にサポート。
- Milvus 1.xからMilvus 2.xへ:旧バージョンのデータを最新フレームワークへスムーズに移行。
- Milvus 2.3.xからMilvus 2.3.x以上へ:既に2.3.xに移行したユーザーに対して、1回限りの移行パスを提供。
特徴
Milvus-migrationは、多様な移行シナリオに対応できるよう、堅牢な機能を備えています:
- 複数のインタラクションメソッド:コマンドラインインターフェイスまたはRestful APIを使用してマイグレーションを実行することができ、マイグレーションの実行方法を柔軟に変更することができます。
- 様々なファイル形式とクラウドストレージのサポートMilvusマイグレーションツールは、ローカルファイルだけでなく、S3、OSS、GCPなどのクラウドストレージに保存されたデータを扱うことができ、幅広い互換性を確保します。
- データタイプの取り扱い:Milvus-migrationはベクトルデータとスカラーフィールドの両方を扱うことができるため、様々なデータ移行のニーズに対応することができます。
アーキテクチャ
Milvus-migrationのアーキテクチャは、効率的なデータストリーミング、解析、書き込み処理を促進するように戦略的に設計されており、様々なデータソース間で堅牢なマイグレーション機能を実現します。
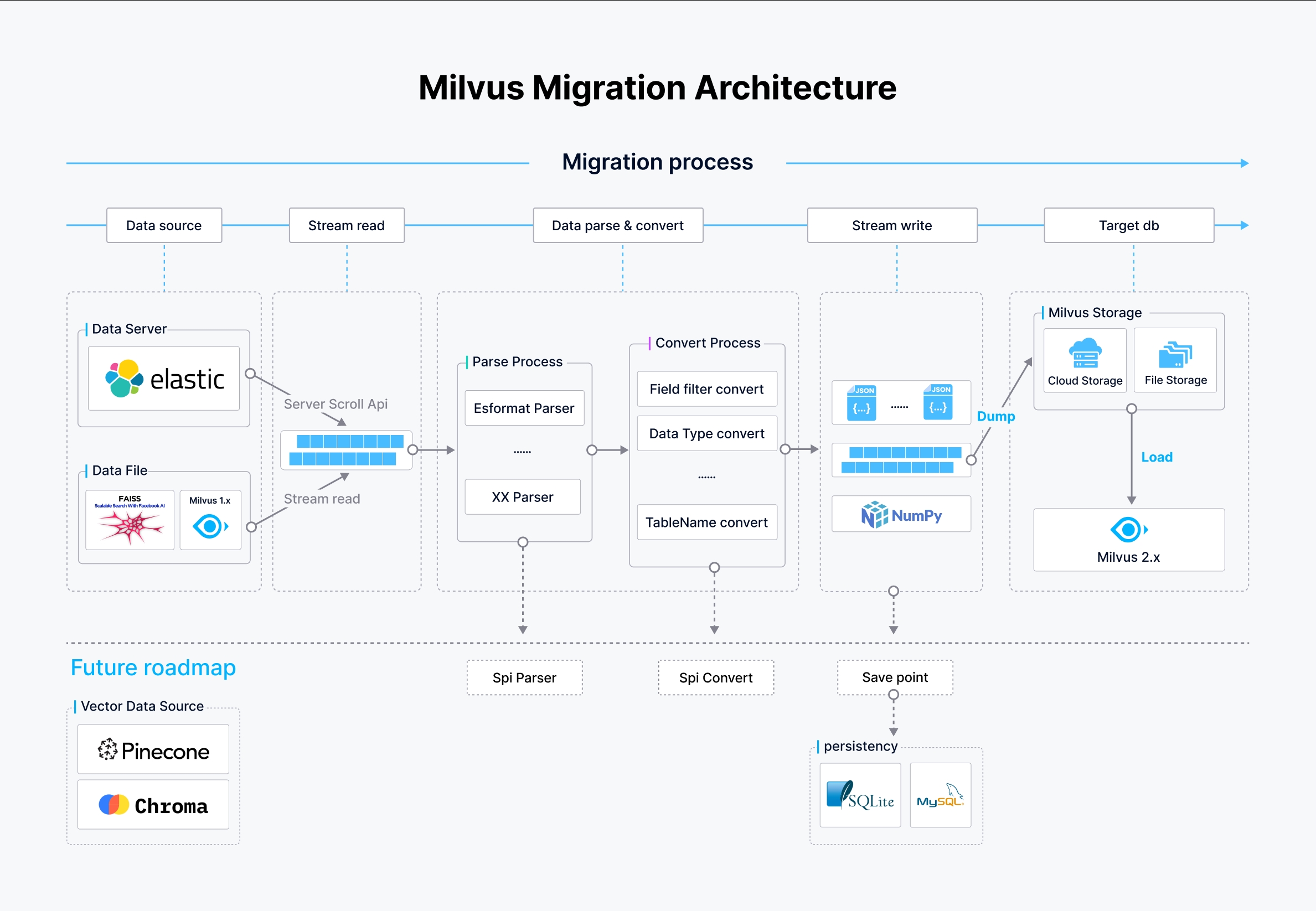 Milvusマイグレーションアーキテクチャ
Milvusマイグレーションアーキテクチャ
先の図では
- データソース Milvus-migrationは、scroll API経由のElasticsearch、ローカルまたはクラウドストレージのデータファイル、Milvus 1.xデータベースを含む複数のデータソースをサポートしています。これらは移行プロセスを開始するために合理化された方法でアクセスされ、読み込まれます。
- ストリームパイプライン
- 解析プロセス:ソースからのデータはそのフォーマットに従って解析されます。例えば、ElasticsearchからのデータソースにはElasticsearchフォーマットのパーサーが採用され、その他のフォーマットにはそれぞれのパーサーが使用される。このステップは、生データをさらに処理可能な構造化フォーマットに変換するために重要である。
- 変換プロセス:パーシングの後、データは変換され、フィールドはフィルタリングされ、データタイプは変換され、テーブル名はターゲットMilvus 2.xスキーマに従って調整されます。これにより、データがMilvusで期待される構造と型に適合することが保証されます。
- データの書き込みと読み込み
- データを書き込む:処理されたデータは中間的なJSONまたはNumPyファイルに書き込まれ、Milvus 2.xにロードされます。
- データのロードデータは最終的にBulkInsertオペレーションを使ってMilvus 2.xにロードされ、大量のデータをクラウドベースまたはファイルストアのMilvusストレージシステムに効率的に書き込む。
今後の計画
開発チームはMilvus-migrationに以下のような機能を追加していく予定です:
- より多くのデータソースのサポートPinecone、Chroma、Qdrantのようなデータベースやファイルシステムのサポートを拡張する予定です。特定のデータソースのサポートが必要な場合は、このGitHub issue linkからリクエストを送信してください。
- コマンドの簡素化:コマンドプロセスを簡素化し、より簡単に実行できるようにしました。
- SPIパーサー/変換:このアーキテクチャには、解析と変換の両方のためのサービス・プロバイダー・インターフェース(SPI)ツールが含まれる予定です。これらのツールは、特定のデータ形式や変換ルールを扱うために、ユーザーが移行プロセスにプラグインできるカスタム実装を可能にする。
- チェックポイントの再開:移行を最後のチェックポイントから再開できるようにし、中断時の信頼性と効率を高める。セーブポイントはデータの整合性を確保するために作成され、SQLiteやMySQLなどのデータベースに保存され、移行プロセスの進捗を追跡します。