Data Model Design for Search
Information Retrieval systems, also known as search engines, are essential for various AI applications such as Retrieval-augmented generation (RAG), visual search, and product recommendation. At the core of these systems is a carefully-designed data model to organize, index and retrieve the information.
Milvus allows you to specify the search data model through a collection schema, organizing unstructured data, their dense or sparse vector representations, and structured metadata. Whether you’re working with text, images, or other data types, this hands-on guide will help you understand and apply key schema concepts to design a search data model in practice.
 Data Model Anatomy
Data Model Anatomy
Data Model
The data model design of a search system involves analyzing business needs and abstracting information into a schema-expressed data model. A well-defined schema is important for aligning the data model with business objectives, ensuring data consistency and quality of service. In addition, choosing proper data types and index is important in achieving the business goal economically.
Analyzing Business Needs
Effectively addressing business needs begins with analyzing the types of queries users will perform and determining the most suitable search methods.
User Queries: Identify the types of queries users are expected to perform. This helps ensure your schema supports real-world use cases and optimizes search performance. These may include:
Retrieving documents that match a natural language query
Finding images similar to a reference image or matching a text description
Searching for products by attributes like name, category, or brand
Filtering items based on structured metadata (e.g., publication date, tags, ratings)
Combining multiple criteria in hybrid queries (e.g., in visual search, considering semantic similarity of both images and their captions)
Search Methods: Choose the appropriate search techniques that align with the types of queries your users will perform. Different methods serve different purposes and can often be combined for more powerful results:
Semantic search: Uses dense vector similarity to find items with similar meaning, ideal for unstructured data like text or images.
Full-text search: Complementing semantic search with keyword matching. Full-text search can utilize lexical analysis to avoid breaking long words into fragmented tokens, grasping the special terms during retrieval.
Metadata filtering: On top of vector search, applying constraints like date ranges, categories, or tags.
Translates Business Requirements into a Search Data Model
The next step is to translate your business requirements into a concrete data model, by identifying the core components of your information and their search methods:
Define the data you need to store, such as raw content (text, images, audio), associated metadata (titles, tags, authorship), and contextual attributes (timestamps, user behavior, etc.)
Determine the appropriate data types and formats for each element. For example:
Text descriptions → string
Image or document embeddings → dense or sparse vectors
Categories, tags, or flags → string, array, and bool
Numeric attributes like price or rating → integer or float
Structured information such as author details -> json
A clear definition of these elements ensures data consistency, accurate search results, and ease of integration with downstream application logics.
Schema Design
In Milvus, the data model is expressed through a collection schema. Designing the right fields within a collection schema is key to enabling effective retrieval. Each field defines a particular type of data stored in the collection and plays a distinct role in the search process. On the high level, Milvus supports two main types of fields: vector fields and scalar fields.
Now, you can map your data model into a schema of fields, including vectors and any auxiliary scalar fields. Ensure that each field correlates with the attributes from your data model, especially pay attention to your vector type (dense or spase) and its dimension.
Vector Field
Vector fields store embeddings for unstructured data types such as text, images, and audio. These embeddings may be dense, sparse, or binary, depending on the data type and the retrieval method utilized. Typically, dense vectors are used for semantic search, while sparse vectors are better suited for full-text or lexical matching. Binary vectors are useful when storage and computational resources are limited. A collection may contain several vector fields to enable multi-modal or hybrid retrieval strategies. For a detailed guide on this topic, please refer to the Multi-Vector Hybrid Search.
Milvus supports the vector data types: FLOAT_VECTOR for Dense Vector, SPARSE_FLOAT_VECTOR for Sparse Vector, and BINARY_VECTOR for Binary Vector
Scalar Field
Scalar fields store primitive, structured values—commonly referred to as metadata—such as numbers, strings, or dates. These values can be returned alongside vector search results and are essential for filtering and sorting. They allow you to narrow search results based on specific attributes, like limiting documents to a particular category or a defined time range.
Milvus supports scalar types such as BOOL, INT8/16/32/64, FLOAT, DOUBLE, VARCHAR, JSON, and ARRAY for storing and filtering non-vector data. These types enhance the precision and customization of search operations.
Leverage Advanced Features in Schema Design
When designing a schema, simply mapping your data to fields using the supported data types is not enough. It is essential to have a thorough understanding of the relationships between fields and the strategies available for configuration. Keeping key features in mind during the design phase ensures that the schema not only meets immediate data handling requirements, but is also scalable and adaptable for future needs. By carefully integrating these features, you can build a strong data architecture that maximizes the capabilities of Milvus and supports your broader data strategy and objectives. Here is an overview of the key features creating a collection schema:
Primary Key
A primary key field is a fundamental component of a schema, as it uniquely identifies each entity within a collection. Defining a primary key is mandatory. It shall be scalar field of integer or string type and marked as is_primary=True. Optionally, you can enable auto_id for the primary key, which is automatically assigned integer numbers that monolithically grow as more data is ingested into the collection.
For further details, refer to Primary Field & AutoID.
Partitioning
To speed up the search, you can optionally turn on partitioning. By designating a specific scalar field for partitioning and specifying filtering criteria based on this field during searches, the search scope can be effectively limited to only the relevant partitions. This method significantly enhances the efficiency of retrieval operations by reducing the search domain.
For further details, refer to Use Partition Key.
Analyzer
An analyzer is an essential tool for processing and transforming text data. Its main function is to convert raw text into tokens and to structure them for indexing and retrieval. It does that by tokenizing the string, dropping the stop words, and stemming the individual words into tokens.
For further details, refer to Analyzer Overview.
Function
Milvus allows you to define built-in functions as part of the schema to automatically derive certain fields. For instance, you can add a built-in BM25 function that generates a sparse vector from a VARCHAR field to support full-text search. These function-derived fields streamline preprocessing and ensure that the collection remains self-contained and query-ready.
For further details, refer to Full Text Search.
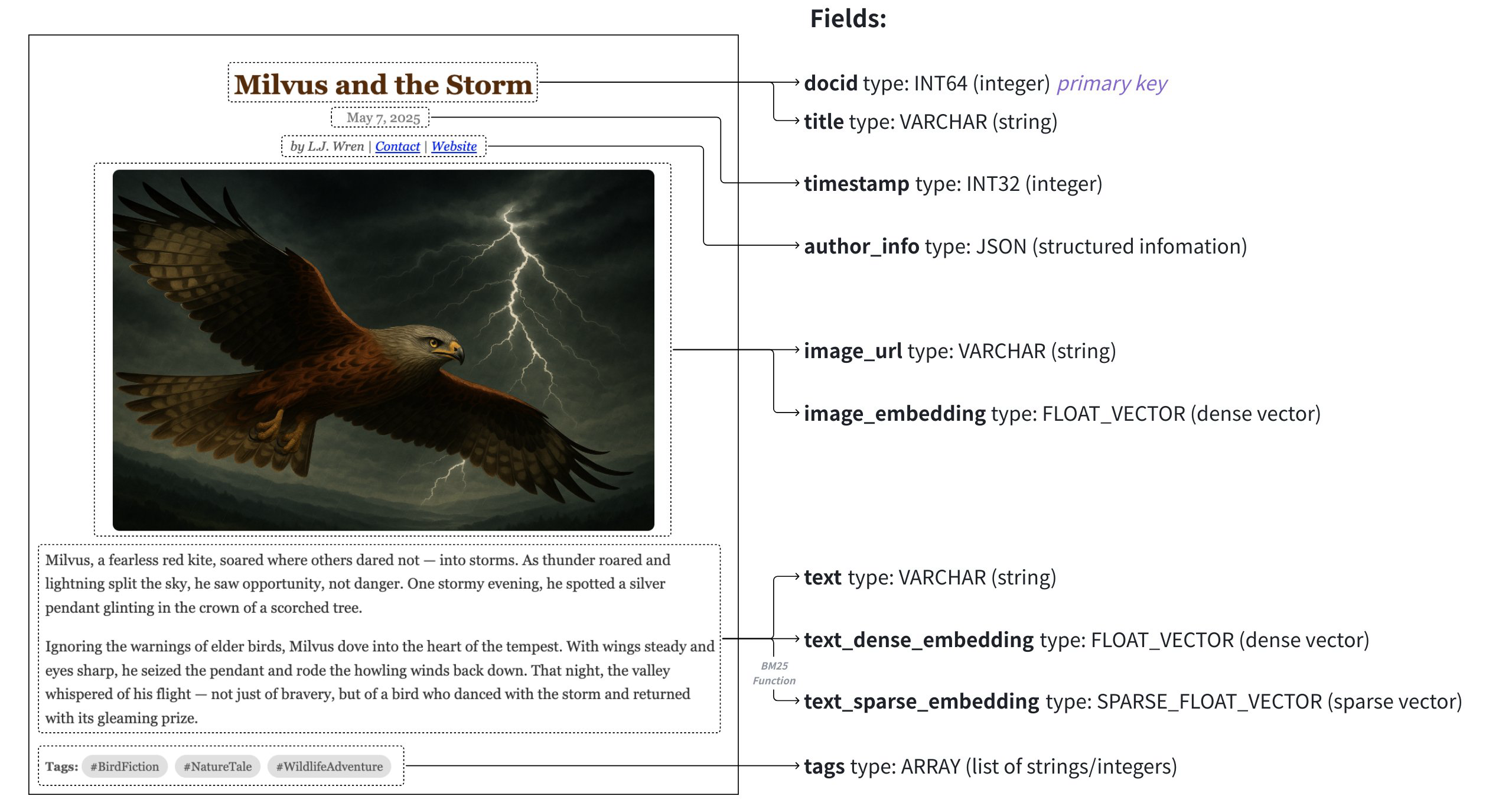
A Real World Example
In this section, we will outline the schema design and code example for a multimedia document search application shown in above diagram. This schema is designed to manage a dataset containing articles with data mapping to the following fields:
Field |
Data Source |
Used By Search Methods |
Primary Key |
Partition Key |
Analyzer |
Function Input/Output |
|---|---|---|---|---|---|---|
article_id ( |
auto-generated with enabled |
Y |
N |
N |
N |
|
title ( |
article title |
N |
N |
Y |
N |
|
timestamp ( |
publish date |
N |
Y |
N |
N |
|
text ( |
raw text of the article |
N |
N |
Y |
input |
|
text_dense_vector ( |
dense vector generated by a text embedding model |
N |
N |
N |
N |
|
text_sparse_vector ( |
sparse vector auto-generated by a built-in BM25 function |
N |
N |
N |
output |
For more information on schemas and detailed guidance on adding various types of fields, please refer to Schema Explained.
Initialize schema
To begin, we need to create an empty schema. This step establishes a foundational structure for defining the data model.
from pymilvus import MilvusClient
schema = MilvusClient.create_schema()
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
// 1. Connect to Milvus server
ConnectConfig connectConfig = ConnectConfig.builder()
.uri("http://localhost:19530")
.build();
MilvusClientV2 client = new MilvusClientV2(connectConfig);
// 2. Create an empty schema
CreateCollectionReq.CollectionSchema schema = client.createSchema();
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
//Skip this step using JavaScript
import "github.com/milvus-io/milvus/client/v2/entity"
schema := entity.NewSchema()
# Skip this step using cURL
Add fields
Once the schema is created, the next step is to specify the fields that will comprise your data. Each field is associated with their respective data types and attributes.
from pymilvus import DataType
schema.add_field(field_name="article_id", datatype=DataType.INT64, is_primary=True, auto_id=True, description="article id")
schema.add_field(field_name="title", datatype=DataType.VARCHAR, enable_analyzer=True, enable_match=True, max_length=200, description="article title")
schema.add_field(field_name="timestamp", datatype=DataType.INT32, description="publish date")
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=2000, enable_analyzer=True, description="article text content")
schema.add_field(field_name="text_dense_vector", datatype=DataType.FLOAT_VECTOR, dim=768, description="text dense vector")
schema.add_field(field_name="text_sparse_vector", datatype=DataType.SPARSE_FLOAT_VECTOR, description="text sparse vector")
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
schema.addField(AddFieldReq.builder()
.fieldName("article_id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("title")
.dataType(DataType.VarChar)
.maxLength(200)
.enableAnalyzer(true)
.enableMatch(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("timestamp")
.dataType(DataType.Int32)
.build())
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(2000)
.enableAnalyzer(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text_dense_vector")
.dataType(DataType.FloatVector)
.dimension(768)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text_sparse_vector")
.dataType(DataType.SparseFloatVector)
.build());
const fields = [
{
name: "article_id",
data_type: DataType.Int64,
is_primary_key: true,
auto_id: true
},
{
name: "title",
data_type: DataType.VarChar,
max_length: 200,
enable_analyzer: true,
enable_match: true
},
{
name: "timestamp",
data_type: DataType.Int32
},
{
name: "text",
data_type: DataType.VarChar,
max_length: 2000,
enable_analyzer: true
},
{
name: "text_dense_vector",
data_type: DataType.FloatVector,
dim: 768
},
{
name: "text_sparse_vector",
data_type: DataType.SparseFloatVector
}
]
schema.WithField(entity.NewField().
WithName("article_id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(true).
WithDescription("article id"),
).WithField(entity.NewField().
WithName("title").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(200).
WithEnableAnalyzer(true).
WithEnableMatch(true).
WithDescription("article title"),
).WithField(entity.NewField().
WithName("timestamp").
WithDataType(entity.FieldTypeInt32).
WithDescription("publish date"),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(2000).
WithEnableAnalyzer(true).
WithDescription("article text content"),
).WithField(entity.NewField().
WithName("text_dense_vector").
WithDataType(entity.FieldTypeFloatVector).
WithDim(768).
WithDescription("text dense vector"),
).WithField(entity.NewField().
WithName("text_sparse_vector").
WithDataType(entity.FieldTypeSparseVector).
WithDescription("text sparse vector"),
)
export fields='[
{
"fieldName": "article_id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "title",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 200,
"enable_analyzer": true,
"enable_match": true
}
},
{
"fieldName": "timestamp",
"dataType": "Int32"
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 2000,
"enable_analyzer": true
}
},
{
"fieldName": "text_dense_vector",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": 768
}
},
{
"fieldName": "text_sparse_vector",
"dataType": "SparseFloatVector",
}
]'
export schema="{
\"autoID\": true,
\"fields\": $fields
}"
In this example, the following attributes are specified for fields:
Primary key: the
article_idis used as the primary key enabling automatically allocation of primary keys for incoming entities.Partition key: the
timestampis assigned as a partition key allowing filtering by partitions. This might beText analyzer: text analyzer is applied to 2 string fields
titleandtextto support text match and full-text search respectively.
(Optional) Add functions
To enhance data querying capabilities, functions can be incorporated into the schema. For instance, a function can be created to process related to specific fields.
from pymilvus import Function, FunctionType
bm25_function = Function(
name="text_bm25",
input_field_names=["text"],
output_field_names=["text_sparse_vector"],
function_type=FunctionType.BM25,
)
schema.add_function(bm25_function)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
import java.util.*;
schema.addFunction(Function.builder()
.functionType(FunctionType.BM25)
.name("text_bm25")
.inputFieldNames(Collections.singletonList("text"))
.outputFieldNames(Collections.singletonList("text_sparse_vector"))
.build());
import FunctionType from "@zilliz/milvus2-sdk-node";
const functions = [
{
name: 'text_bm25',
description: 'bm25 function',
type: FunctionType.BM25,
input_field_names: ['text'],
output_field_names: ['text_sparse_vector'],
params: {},
},
];
function := entity.NewFunction().
WithName("text_bm25").
WithInputFields("text").
WithOutputFields("text_sparse_vector").
WithType(entity.FunctionTypeBM25)
schema.WithFunction(function)
export myFunctions='[
{
"name": "text_bm25",
"type": "BM25",
"inputFieldNames": ["text"],
"outputFieldNames": ["text_sparse_vector"],
"params": {}
}
]'
export schema="{
\"autoID\": true,
\"fields\": $fields
\"functions\": $myFunctions
}"
This example adds a built-in BM25 function in schema, utilizing the text field as input and storing the resulting sparse vectors in the text_sparse_vector field.