Panoramica sulla migrazione di Milvus
Riconoscendo le diverse esigenze della base di utenti, Milvus ha ampliato i suoi strumenti di migrazione non solo per facilitare gli aggiornamenti dalle versioni precedenti di Milvus 1.x, ma anche per consentire una perfetta integrazione dei dati da altri sistemi come Elasticsearch e Faiss. Il progetto di migrazione di Milvus è stato concepito per colmare il divario tra questi diversi ambienti di dati e gli ultimi progressi della tecnologia Milvus, assicurando che possiate sfruttare le funzionalità e le prestazioni migliorate senza soluzione di continuità.
Migrazioni supportate
Lo strumento Milvus-migration supporta una serie di percorsi di migrazione per soddisfare le diverse esigenze degli utenti:
- Da Elasticsearch a Milvus 2.x: Consente agli utenti di migrare i dati da ambienti Elasticsearch per sfruttare le capacità di ricerca vettoriale ottimizzata di Milvus.
- Faiss a Milvus 2.x: Fornisce un supporto sperimentale per il trasferimento di dati da Faiss, una popolare libreria per la ricerca efficiente di similarità.
- Da Milvus 1.x a Milvus 2.x: Garantire la transizione dei dati dalle versioni precedenti all'ultima versione del framework.
- Da Milvus 2.3.x a Milvus 2.3.x o superiore: Fornisce un percorso di migrazione una tantum per gli utenti che sono già passati alla versione 2.3.x.
Caratteristiche
Milvus-migration è stato progettato con caratteristiche robuste per gestire diversi scenari di migrazione:
- Metodi di interazione multipli: È possibile eseguire le migrazioni tramite un'interfaccia a riga di comando o tramite un'API Restful, con una certa flessibilità nelle modalità di esecuzione delle migrazioni.
- Supporto per vari formati di file e cloud storage: Lo strumento Milvus-migration è in grado di gestire i dati memorizzati in file locali e in soluzioni di archiviazione cloud come S3, OSS e GCP, garantendo un'ampia compatibilità.
- Gestione dei tipi di dati: Milvus-migration è in grado di gestire sia dati vettoriali che campi scalari, il che lo rende una scelta versatile per le diverse esigenze di migrazione dei dati.
Architettura
L'architettura di Milvus-migration è stata progettata strategicamente per facilitare lo streaming dei dati, il parsing e i processi di scrittura, consentendo solide capacità di migrazione tra diverse fonti di dati.
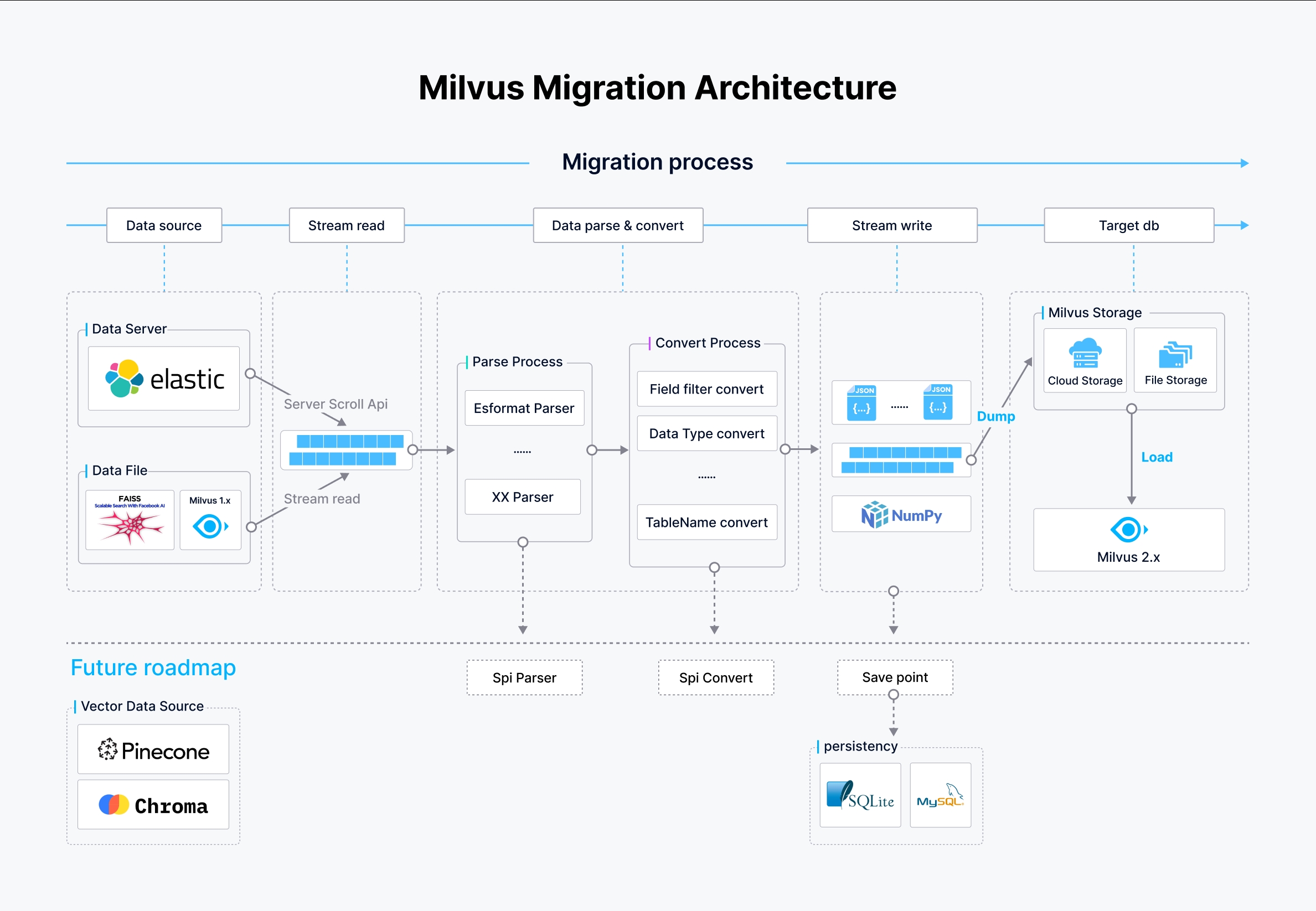 Architettura di Milvus-migration
Architettura di Milvus-migration
Nella figura precedente:
- Sorgente di dati: Milvus-migration supporta diverse fonti di dati, tra cui Elasticsearch tramite l'API di scorrimento, file di dati locali o di cloud storage e database Milvus 1.x. L'accesso e la lettura di queste fonti avvengono in modo semplificato per avviare il processo di migrazione.
- Pipeline di flusso:
- Processo di analisi: I dati provenienti dalle fonti vengono analizzati in base al loro formato. Ad esempio, per una fonte di dati proveniente da Elasticsearch, viene utilizzato un parser per il formato Elasticsearch, mentre gli altri formati utilizzano i rispettivi parser. Questa fase è fondamentale per trasformare i dati grezzi in un formato strutturato che possa essere ulteriormente elaborato.
- Processo di conversione: Dopo il parsing, i dati sono sottoposti a una conversione in cui i campi sono filtrati, i tipi di dati sono convertiti e i nomi delle tabelle sono adattati allo schema Milvus 2.x di destinazione. Questo assicura che i dati siano conformi alla struttura e ai tipi previsti in Milvus.
- Scrittura e caricamento dei dati:
- Scrivere i dati: I dati elaborati vengono scritti in file JSON o NumPy intermedi, pronti per essere caricati in Milvus 2.x.
- Caricamento dei dati: I dati vengono infine caricati in Milvus 2.x utilizzando l'operazione BulkInsert, che scrive in modo efficiente grandi volumi di dati nei sistemi di archiviazione di Milvus, sia basati su cloud che su filestore.
Piani futuri
Il team di sviluppo è impegnato a migliorare Milvus-migration con funzionalità quali:
- Supporto per un maggior numero di fonti di dati: Piani per estendere il supporto ad altri database e file system, come Pinecone, Chroma, Qdrant. Se avete bisogno del supporto per una fonte di dati specifica, inviate la vostra richiesta attraverso questo link al problema GitHub.
- Semplificazione dei comandi: Sforzi per snellire il processo dei comandi per facilitarne l'esecuzione.
- Parser / conversioneSPI: L'architettura prevede di includere strumenti SPI (Service Provider Interface) per l'analisi e la conversione. Questi strumenti consentono implementazioni personalizzate che gli utenti possono inserire nel processo di migrazione per gestire formati di dati specifici o regole di conversione.
- Ripresa del checkpoint: Consente di riprendere le migrazioni dall'ultimo checkpoint per migliorare l'affidabilità e l'efficienza in caso di interruzioni. I punti di salvataggio vengono creati per garantire l'integrità dei dati e sono memorizzati in database come SQLite o MySQL per tracciare l'avanzamento del processo di migrazione.