INVERTED
When you need to perform frequent filter queries on your data, INVERTED indexes can dramatically improve query performance. Instead of scanning through all documents, Milvus uses inverted indexes to quickly locate the exact records that match your filter conditions.
When to use INVERTED indexes
Use INVERTED indexes when you need to:
Filter by specific values: Find all records where a field equals a specific value (e.g.,
category == "electronics")Filter text content: Perform efficient searches on
VARCHARfieldsQuery JSON field values: Filter on specific keys within JSON structures
Performance benefit: INVERTED indexes can reduce query time from seconds to milliseconds on large datasets by eliminating the need for full collection scans.
How INVERTED indexes work
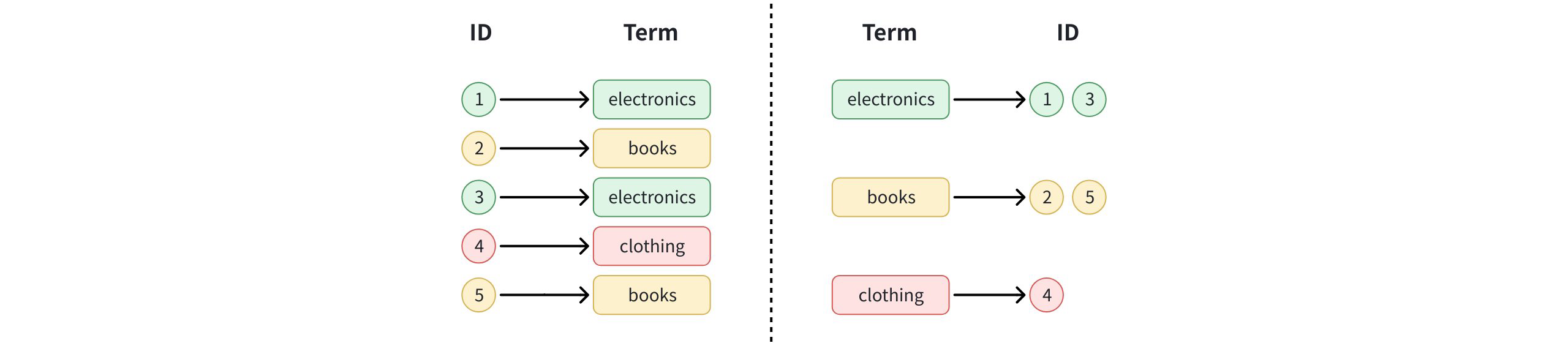
An INVERTED index in Milvus maps each unique field value (term) to the set of document IDs where that value occurs. This structure enables fast lookups for fields with repeated or categorical values.
As shown in the diagram, the process works in two steps:
Forward mapping (ID → Term): Each document ID points to the field value it contains.
Inverted mapping (Term → IDs): Milvus collects unique terms and builds a reverse mapping from each term to all IDs that contain it.
For example, the value “electronics” maps to IDs 1 and 3, while “books” maps to IDs 2 and 5.
 How Inverted Index Works
How Inverted Index Works
When you filter for a specific value (e.g., category == "electronics"), Milvus simply looks up the term in the index and retrieves the matching IDs directly. This avoids scanning the full dataset and enables fast filtering, especially for categorical or repeated values.
INVERTED indexes support all scalar field types, such as BOOL, INT8, INT16, INT32, INT64, FLOAT, DOUBLE, VARCHAR, JSON, and ARRAY. However, the index parameters for indexing a JSON field are slightly different from regular scalar fields.
Create indexes on non-JSON fields
To create an index on a non-JSON field, follow these steps:
Prepare your index parameters:
from pymilvus import MilvusClient client = MilvusClient(uri="http://localhost:19530") # Replace with your server address # Create an empty index parameter object index_params = client.prepare_index_params()Add the
INVERTEDindex:index_params.add_index( field_name="category", # Name of the field to index index_type="INVERTED", # Specify INVERTED index type index_name="category_index" # Give your index a name )Create the index:
client.create_index( collection_name="my_collection", # Replace with your collection name index_params=index_params )
Create indexes on JSON fieldsCompatible with Milvus 2.5.11+
You can also create INVERTED indexes on specific paths within JSON fields. This requires additional parameters to specify the JSON path and data type:
# Build index params
index_params.add_index(
field_name="metadata", # JSON field name
index_type="INVERTED",
index_name="metadata_category_index",
params={
"json_path": "metadata[\"category\"]", # Path to the JSON key
"json_cast_type": "varchar" # Data type to cast to during indexing
}
)
# Create index
client.create_index(
collection_name="my_collection", # Replace with your collection name
index_params=index_params
)
For detailed information about JSON field indexing, including supported paths, data types, and limitations, refer to JSON Indexing.
Drop an index
Use the drop_index() method to remove an existing index from a collection.
In v2.6.3 or earlier, you must release the collection before dropping a scalar index.
From v2.6.4 or later, you can drop a scalar index directly once it’s no longer needed—no need to release the collection first.
client.drop_index(
collection_name="my_collection", # Name of the collection
index_name="category_index" # Name of the index to drop
)
Best practices
Create indexes after loading data: Build indexes on collections that already contain data for better performance
Use descriptive index names: Choose names that clearly indicate the field and purpose
Monitor index performance: Check query performance before and after creating indexes
Consider your query patterns: Create indexes on fields you frequently filter by
Next steps
Learn about other index types
See JSON Indexing for advanced JSON indexing scenarios