Milvus Migration Übersicht
In Anbetracht der vielfältigen Bedürfnisse der Benutzer hat Milvus seine Migrationswerkzeuge erweitert, um nicht nur Upgrades von früheren Milvus 1.x-Versionen zu erleichtern, sondern auch die nahtlose Integration von Daten aus anderen Systemen wie Elasticsearch und Faiss zu ermöglichen. Das Milvus-Migrationsprojekt wurde entwickelt, um die Lücke zwischen diesen unterschiedlichen Datenumgebungen und den neuesten Fortschritten in der Milvus-Technologie zu schließen und sicherzustellen, dass Sie die verbesserten Funktionen und Leistungen nahtlos nutzen können.
Unterstützte Migrationen
Das Milvus-Migrations-Tool unterstützt eine Vielzahl von Migrationspfaden, um unterschiedlichen Benutzeranforderungen gerecht zu werden:
- Elasticsearch zu Milvus 2.x: Ermöglicht Benutzern die Migration von Daten aus Elasticsearch-Umgebungen, um die Vorteile der optimierten Vektorsuchfunktionen von Milvus zu nutzen.
- Faiss zu Milvus 2.x: Experimentelle Unterstützung für die Übertragung von Daten aus Faiss, einer beliebten Bibliothek für effiziente Ähnlichkeitssuche.
- Milvus 1.x zu Milvus 2.x: Sicherstellung des reibungslosen Übergangs von Daten aus früheren Versionen in das neueste Framework.
- Milvus 2.3.x zu Milvus 2.3.x oder höher: Bereitstellung eines einmaligen Migrationspfads für Benutzer, die bereits auf 2.3.x migriert sind.
Merkmale
Milvus-Migration wurde mit robusten Funktionen entwickelt, um verschiedene Migrationsszenarien zu bewältigen:
- Mehrere Interaktionsmethoden: Sie können Migrationen über eine Befehlszeilenschnittstelle oder über eine Restful-API durchführen, wobei Sie flexibel entscheiden können, wie die Migrationen ausgeführt werden.
- Unterstützung für verschiedene Dateiformate und Cloud-Speicher: Das Milvus-Migrationswerkzeug kann Daten verarbeiten, die sowohl in lokalen Dateien als auch in Cloud-Speicherlösungen wie S3, OSS und GCP gespeichert sind, was eine breite Kompatibilität gewährleistet.
- Behandlung von Datentypen: Milvus-migration kann sowohl mit Vektordaten als auch mit skalaren Feldern umgehen und ist damit eine vielseitige Wahl für unterschiedliche Datenmigrationsanforderungen.
Architektur
Die Architektur von Milvus-migration wurde strategisch entwickelt, um effizientes Daten-Streaming, Parsing und Schreibprozesse zu erleichtern und robuste Migrationsfähigkeiten über verschiedene Datenquellen hinweg zu ermöglichen.
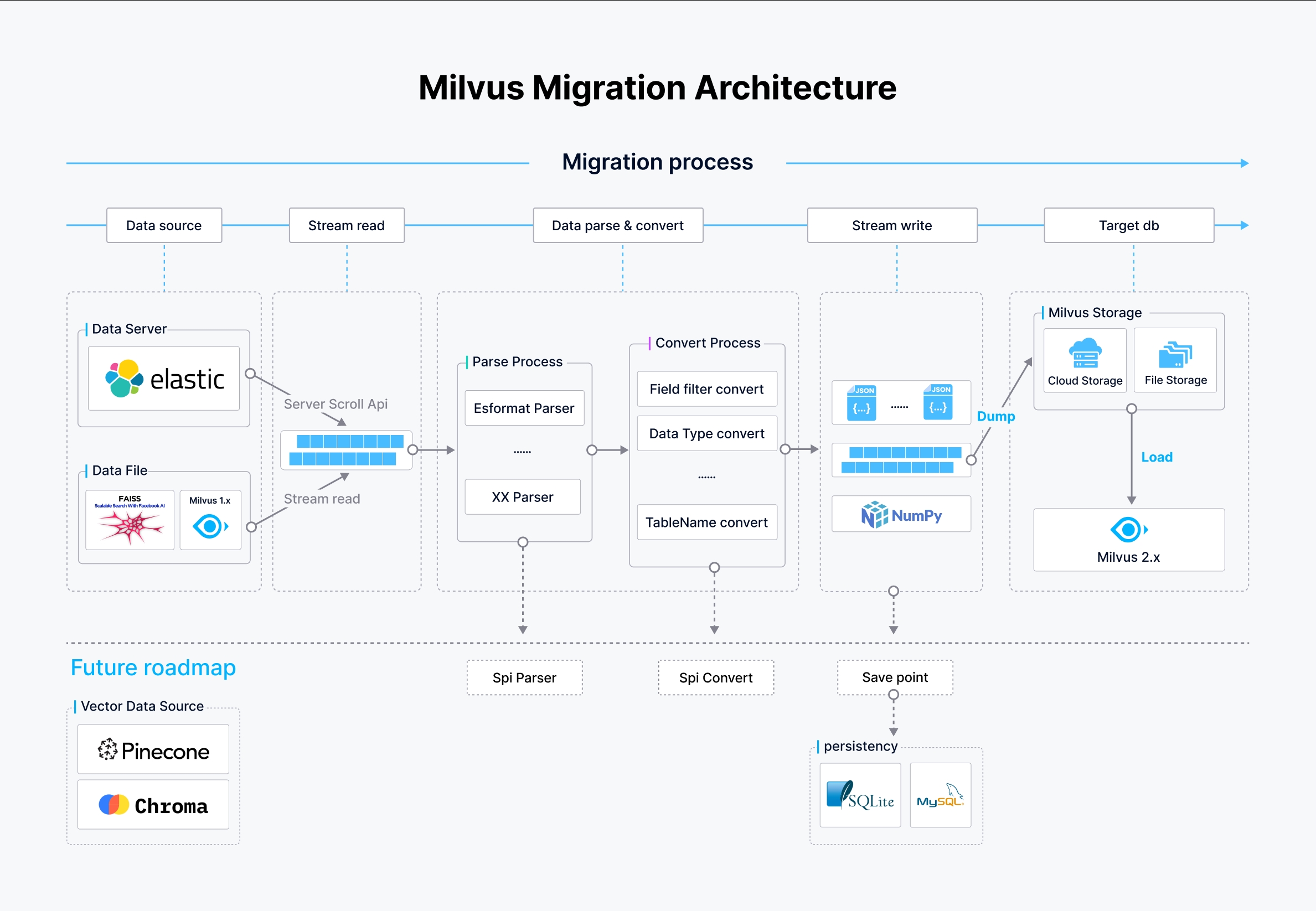 Milvus-Migrationsarchitektur
Milvus-Migrationsarchitektur
In der vorangehenden Abbildung:
- Datenquelle: Milvus-migration unterstützt mehrere Datenquellen, darunter Elasticsearch über die Scroll-API, lokale oder Cloud-Speicherdateien und Milvus 1.x-Datenbanken. Auf diese wird zugegriffen und sie werden auf eine rationalisierte Weise gelesen, um den Migrationsprozess zu initiieren.
- Stream-Pipeline:
- Parsing-Prozess: Die Daten aus den Quellen werden entsprechend ihrem Format geparst. So wird beispielsweise für eine Datenquelle aus Elasticsearch ein Parser für das Elasticsearch-Format verwendet, während für andere Formate entsprechende Parser eingesetzt werden. Dieser Schritt ist entscheidend für die Umwandlung von Rohdaten in ein strukturiertes Format, das weiterverarbeitet werden kann.
- Konvertierungsprozess: Nach dem Parsen werden die Daten einer Konvertierung unterzogen, bei der Felder gefiltert, Datentypen konvertiert und Tabellennamen an das Zielschema von Milvus 2.x angepasst werden. Dadurch wird sichergestellt, dass die Daten mit der erwarteten Struktur und den erwarteten Typen in Milvus übereinstimmen.
- Schreiben und Laden von Daten:
- Daten schreiben: Die verarbeiteten Daten werden in JSON- oder NumPy-Zwischendateien geschrieben, die dann in Milvus 2.x geladen werden können.
- Daten laden: Die Daten werden schließlich mit der BulkInsert-Operation in Milvus 2.x geladen, die große Datenmengen effizient in Milvus-Speichersysteme schreibt, entweder in die Cloud oder in einen Dateispeicher.
Pläne für die Zukunft
Das Entwicklungsteam ist bestrebt, die Milvus-Migration um folgende Funktionen zu erweitern:
- Unterstützung für weitere Datenquellen: Es ist geplant, die Unterstützung auf weitere Datenbanken und Dateisysteme wie Pinecone, Chroma, Qdrant zu erweitern. Wenn Sie Unterstützung für eine bestimmte Datenquelle benötigen, reichen Sie Ihre Anfrage bitte über diesen GitHub Issue-Link ein.
- Vereinfachung der Befehle: Bemühungen zur Vereinfachung des Befehlsprozesses für eine einfachere Ausführung.
- SPI-Parser / Konvertierung: Die Architektur wird voraussichtlich SPI-Tools (Service Provider Interface) zum Parsen und Konvertieren enthalten. Diese Tools ermöglichen benutzerdefinierte Implementierungen, die Benutzer in den Migrationsprozess einfügen können, um bestimmte Datenformate oder Konvertierungsregeln zu handhaben.
- Wiederaufnahme von Kontrollpunkten: Ermöglicht die Wiederaufnahme von Migrationen ab dem letzten Kontrollpunkt, um die Zuverlässigkeit und Effizienz im Falle von Unterbrechungen zu erhöhen. Um die Datenintegrität zu gewährleisten, werden Speicherpunkte erstellt und in Datenbanken wie SQLite oder MySQL gespeichert, um den Fortschritt des Migrationsprozesses zu verfolgen.