Verwenden Sie Apache Spark™ mit Milvus/Zilliz Cloud für KI-Pipelines
Der Spark-Milvus Connector ermöglicht die Integration von Apache Spark und Databricks mit Milvus und Zilliz Cloud. Er verbindet die leistungsstarken Funktionen von Apache Spark für Big Data-Verarbeitung und maschinelles Lernen (ML) mit den modernen Vektorsuchfunktionen von Milvus. Diese Integration ermöglicht optimierte Arbeitsabläufe für die KI-gestützte Suche, erweiterte Analysen, ML-Training und die effiziente Verwaltung großer Vektordaten.
Apache Spark ist eine verteilte Datenverarbeitungsplattform, die für die Verarbeitung großer Datensätze mit Hochgeschwindigkeitsberechnungen entwickelt wurde. In Verbindung mit Milvus oder Zilliz Cloud eröffnet sie neue Möglichkeiten für Anwendungsfälle wie semantische Suche, Empfehlungssysteme und KI-gesteuerte Datenanalyse.
Spark kann zum Beispiel große Datensätze im Stapel verarbeiten, um Einbettungen über ML-Modelle zu generieren, und dann den Spark-Milvus-Konnektor verwenden, um diese Einbettungen direkt in Milvus oder Zilliz Cloud zu speichern. Nach der Indizierung können diese Daten schnell durchsucht oder analysiert werden, wodurch eine leistungsstarke Pipeline für KI- und Big-Data-Workflows entsteht.
Der Spark-Milvus-Konnektor unterstützt Aufgaben wie die iterative und massenhafte Dateneingabe in Milvus, die Synchronisierung von Daten zwischen Systemen und erweiterte Analysen von in Milvus gespeicherten Vektordaten. Dieser Leitfaden führt Sie durch die Schritte zur Konfiguration und effektiven Nutzung des Konnektors für Anwendungsfälle wie:
- Effizientes Laden von Vektordaten in Milvus in großen Stapeln,
- Verschieben von Daten zwischen Milvus und anderen Speichersystemen oder Datenbanken,
- Analysieren der Daten in Milvus durch Nutzung von Spark MLlib und anderen KI-Tools.
Schnellstart
Vorbereitung
Der Spark-Milvus Connector unterstützt die Programmiersprachen Scala und Python. Benutzer können ihn mit Pyspark oder Spark-shell verwenden. Um diese Demo auszuführen, richten Sie eine Spark-Umgebung ein, die die Spark-Milvus Connector-Abhängigkeit in den folgenden Schritten enthält:
Installieren Sie Apache Spark (Version >= 3.3.0)
Sie können Apache Spark installieren, indem Sie die offizielle Dokumentation zu Rate ziehen.
Laden Sie die spark-milvus jar-Datei herunter.
wget https://github.com/zilliztech/spark-milvus/raw/1.0.0-SNAPSHOT/output/spark-milvus-1.0.0-SNAPSHOT.jarStarten Sie die Spark-Laufzeitumgebung mit spark-milvus jar als eine der Abhängigkeiten.
Um die Spark-Laufzeit mit dem Spark-Milvus-Konnektor zu starten, fügen Sie das heruntergeladene spark-milvus als Abhängigkeit zum Befehl hinzu.
pyspark
./bin/pyspark --jars spark-milvus-1.0.0-SNAPSHOT.jarspark-shell
./bin/spark-shell --jars spark-milvus-1.0.0-SNAPSHOT.jar
Demo
In dieser Demo wird ein Spark DataFrame mit Vektordaten erstellt und über den Spark-Milvus-Connector nach Milvus geschrieben. Eine Sammlung wird in Milvus automatisch auf der Grundlage des Schemas und der angegebenen Optionen erstellt.
from pyspark.sql import SparkSession
columns = ["id", "text", "vec"]
data = [(1, "a", [1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0]),
(2, "b", [1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0]),
(3, "c", [1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0]),
(4, "d", [1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0])]
sample_df = spark.sparkContext.parallelize(data).toDF(columns)
sample_df.write \
.mode("append") \
.option("milvus.host", "localhost") \
.option("milvus.port", "19530") \
.option("milvus.collection.name", "hello_spark_milvus") \
.option("milvus.collection.vectorField", "vec") \
.option("milvus.collection.vectorDim", "8") \
.option("milvus.collection.primaryKeyField", "id") \
.format("milvus") \
.save()
import org.apache.spark.sql.{SaveMode, SparkSession}
object Hello extends App {
val spark = SparkSession.builder().master("local[*]")
.appName("HelloSparkMilvus")
.getOrCreate()
import spark.implicits._
// Create DataFrame
val sampleDF = Seq(
(1, "a", Seq(1.0,2.0,3.0,4.0,5.0)),
(2, "b", Seq(1.0,2.0,3.0,4.0,5.0)),
(3, "c", Seq(1.0,2.0,3.0,4.0,5.0)),
(4, "d", Seq(1.0,2.0,3.0,4.0,5.0))
).toDF("id", "text", "vec")
// set milvus options
val milvusOptions = Map(
"milvus.host" -> "localhost" -> uri,
"milvus.port" -> "19530",
"milvus.collection.name" -> "hello_spark_milvus",
"milvus.collection.vectorField" -> "vec",
"milvus.collection.vectorDim" -> "5",
"milvus.collection.primaryKeyField", "id"
)
sampleDF.write.format("milvus")
.options(milvusOptions)
.mode(SaveMode.Append)
.save()
}
Nach der Ausführung des obigen Codes können Sie die eingefügten Daten in Milvus mithilfe von SDK oder Attu (einem Milvus-Dashboard) anzeigen. Sie können eine Sammlung mit dem Namen hello_spark_milvus finden, in der bereits 4 Entitäten eingefügt wurden.
Merkmale und Konzepte
Milvus-Optionen
Im Abschnitt Schnellstart haben wir gezeigt, wie man Optionen während der Arbeit mit Milvus einstellen kann. Diese Optionen werden als Milvus Optionen abstrahiert. Sie werden verwendet, um Verbindungen zu Milvus herzustellen und andere Verhaltensweisen von Milvus zu steuern. Nicht alle der Optionen sind obligatorisch.
| Option Schlüssel | Standardwert | Beschreibung |
|---|---|---|
milvus.host | localhost | Milvus-Server-Host. Siehe Verwalten von Milvus-Verbindungen für Details. |
milvus.port | 19530 | Anschluss des Milvus-Servers. Siehe Milvus-Verbindungen verwalten für weitere Details. |
milvus.username | root | Benutzername für Milvus Server. Siehe Milvus-Verbindungen verwalten für weitere Details. |
milvus.password | Milvus | Passwort für den Milvus-Server. Siehe Milvus-Verbindungen verwalten für weitere Details. |
milvus.uri | -- | Milvus-Server-URI. Siehe Milvus-Verbindungen verwalten für weitere Details. |
milvus.token | -- | Milvus-Server-Token. Siehe Manage Milvus Connections für weitere Details. |
milvus.database.name | default | Name der Milvus-Datenbank, die gelesen oder geschrieben werden soll. |
milvus.collection.name | hello_milvus | Name der zu lesenden oder zu schreibenden Milvus-Sammlung. |
milvus.collection.primaryKeyField | None | Name des Primärschlüsselfeldes in der Sammlung. Erforderlich, wenn die Sammlung nicht vorhanden ist. |
milvus.collection.vectorField | None | Name des Vektorfelds in der Sammlung. Erforderlich, wenn die Sammlung nicht vorhanden ist. |
milvus.collection.vectorDim | None | Dimension des Vektorfelds in der Auflistung. Erforderlich, wenn die Sammlung nicht vorhanden ist. |
milvus.collection.autoID | false | Wenn die Sammlung nicht existiert, gibt diese Option an, ob automatisch IDs für die Entitäten generiert werden sollen. Für weitere Informationen, siehe create_collection |
milvus.bucket | a-bucket | Bucket-Name im Milvus-Speicher. Dieser sollte derselbe sein wie minio.bucketName in milvus.yaml. |
milvus.rootpath | files | Root-Pfad des Milvus-Speichers. Dies sollte derselbe sein wie minio.rootpath in milvus.yaml. |
milvus.fs | s3a:// | Dateisystem des Milvus-Speichers. Der Wert s3a:// gilt für Open-Source-Spark. Verwenden Sie s3:// für Databricks. |
milvus.storage.endpoint | localhost:9000 | Endpunkt des Milvus-Speichers. Dies sollte derselbe sein wie minio.address:minio.port in milvus.yaml. |
milvus.storage.user | minioadmin | Benutzer des Milvus-Speichers. Dies sollte dasselbe sein wie minio.accessKeyID in milvus.yaml. |
milvus.storage.password | minioadmin | Passwort für den Milvus-Speicher. Dies sollte dasselbe sein wie minio.secretAccessKey in milvus.yaml. |
milvus.storage.useSSL | false | Ob SSL für den Milvus-Speicher verwendet werden soll. Dies sollte dasselbe sein wie minio.useSSL in milvus.yaml. |
Milvus-Datenformat
Der Spark-Milvus Connector unterstützt das Lesen und Schreiben von Daten in den folgenden Milvus-Datenformaten:
milvus: Milvus-Datenformat für die nahtlose Konvertierung von Spark DataFrame in Milvus-Entitäten.milvusbinlog: Milvus-Datenformat für das Lesen der in Milvus eingebauten Binlog-Daten.mjson: Milvus JSON-Format für das Einfügen von Daten in Milvus.
milvus
Im Schnellstart verwenden wir das Milvus-Format, um Beispieldaten in einen Milvus-Cluster zu schreiben. Das milvus-Format ist ein neues Datenformat, das das nahtlose Schreiben von Spark DataFrame-Daten in Milvus-Sammlungen unterstützt. Dies wird durch Batch-Aufrufe an die Insert-API des Milvus SDK erreicht. Wenn eine Sammlung in Milvus nicht vorhanden ist, wird eine neue Sammlung auf der Grundlage des Schemas des DataFrames erstellt. Allerdings unterstützt die automatisch erstellte Sammlung möglicherweise nicht alle Funktionen des Sammlungsschemas. Es wird daher empfohlen, zunächst eine Sammlung über das SDK zu erstellen und dann spark-milvus zum Schreiben zu verwenden. Weitere Informationen entnehmen Sie bitte der Demo.
milvusbinlog
Das neue Datenformat milvusbinlog dient zum Lesen der in Milvus integrierten binlog-Daten. Binlog ist das interne Datenspeicherformat von Milvus, das auf Parquet basiert. Leider kann es nicht von einer normalen Parquet-Bibliothek gelesen werden, daher haben wir dieses neue Datenformat implementiert, um Spark-Jobs beim Lesen zu helfen. Es wird nicht empfohlen, milvusbinlog direkt zu verwenden, es sei denn, Sie sind mit den Details der internen Speicherung von Milvus vertraut. Wir empfehlen die Verwendung der MilvusUtils-Funktion, die im nächsten Abschnitt vorgestellt wird.
val df = spark.read
.format("milvusbinlog")
.load(path)
.withColumnRenamed("val", "embedding")
mjson
Milvus bietet die Bulkinsert-Funktionalität für eine bessere Schreibleistung bei der Arbeit mit großen Datensätzen. Das von Milvus verwendete JSON-Format unterscheidet sich jedoch geringfügig vom Standard-JSON-Ausgabeformat von Spark. Um dieses Problem zu lösen, führen wir das mjson-Datenformat ein, um Daten zu erzeugen, die den Anforderungen von Milvus entsprechen. Hier ist ein Beispiel, das den Unterschied zwischen JSON-lines und mjson zeigt:
JSON-lines:
{"book_id": 101, "word_count": 13, "book_intro": [1.1, 1.2]} {"book_id": 102, "word_count": 25, "book_intro": [2.1, 2.2]} {"book_id": 103, "word_count": 7, "book_intro": [3.1, 3.2]} {"book_id": 104, "word_count": 12, "book_intro": [4.1, 4.2]} {"book_id": 105, "word_count": 34, "book_intro": [5.1, 5.2]}mjson (erforderlich für Milvus Bulkinsert):
{ "rows":[ {"book_id": 101, "word_count": 13, "book_intro": [1.1, 1.2]}, {"book_id": 102, "word_count": 25, "book_intro": [2.1, 2.2]}, {"book_id": 103, "word_count": 7, "book_intro": [3.1, 3.2]}, {"book_id": 104, "word_count": 12, "book_intro": [4.1, 4.2]}, {"book_id": 105, "word_count": 34, "book_intro": [5.1, 5.2]} ] }
Dies wird in Zukunft verbessert werden. Wir empfehlen die Verwendung des Parquet-Formats in der spark-milvus-Integration, wenn Ihre Milvus-Version v2.3.7+ ist, die Bulkinsert mit Parquet-Format unterstützt. Siehe Demo auf Github.
MilvusUtils
MilvusUtils enthält mehrere nützliche util-Funktionen. Derzeit wird es nur in Scala unterstützt. Weitere Anwendungsbeispiele finden Sie im Abschnitt Erweiterte Verwendung.
MilvusUtils.readMilvusCollection
MilvusUtils.readMilvusCollection ist eine einfache Schnittstelle zum Laden einer ganzen Milvus-Sammlung in einen Spark-Datenframe. Sie verpackt verschiedene Operationen, einschließlich des Aufrufs von Milvus SDK, des Lesens von Milvusbinlog und allgemeiner Union/Join-Operationen.
val collectionDF = MilvusUtils.readMilvusCollection(spark, milvusOptions)
MilvusUtils.bulkInsertFromSpark
MilvusUtils.bulkInsertFromSpark bietet eine bequeme Möglichkeit, Spark-Ausgabedateien in einem großen Stapel in Milvus zu importieren. Es umhüllt die Bullkinsert-API des Milvus-SDK.
df.write.format("parquet").save(outputPath)
MilvusUtils.bulkInsertFromSpark(spark, milvusOptions, outputPath, "parquet")
Erweiterte Verwendung
In diesem Abschnitt finden Sie Beispiele für die erweiterte Nutzung des Spark-Milvus-Connectors für die Datenanalyse und -migration. Für weitere Demos siehe Beispiele.
MySQL -> Einbettung -> Milvus
In dieser Demo werden wir
- Lesen von Daten aus MySQL über den Spark-MySQL-Connector,
- Einbettung generieren (mit Word2Vec als Beispiel) und
- eingebettete Daten in Milvus schreiben.
Um den Spark-MySQL-Connector zu aktivieren, müssen Sie die folgende Abhängigkeit zu Ihrer Spark-Umgebung hinzufügen:
spark-shell --jars spark-milvus-1.0.0-SNAPSHOT.jar,mysql-connector-j-x.x.x.jar
import org.apache.spark.ml.feature.{Tokenizer, Word2Vec}
import org.apache.spark.sql.functions.udf
import org.apache.spark.sql.{SaveMode, SparkSession}
import zilliztech.spark.milvus.MilvusOptions._
import org.apache.spark.ml.linalg.Vector
object Mysql2MilvusDemo extends App {
val spark = SparkSession.builder().master("local[*]")
.appName("Mysql2MilvusDemo")
.getOrCreate()
import spark.implicits._
// Create DataFrame
val sampleDF = Seq(
(1, "Milvus was created in 2019 with a singular goal: store, index, and manage massive embedding vectors generated by deep neural networks and other machine learning (ML) models."),
(2, "As a database specifically designed to handle queries over input vectors, it is capable of indexing vectors on a trillion scale. "),
(3, "Unlike existing relational databases which mainly deal with structured data following a pre-defined pattern, Milvus is designed from the bottom-up to handle embedding vectors converted from unstructured data."),
(4, "As the Internet grew and evolved, unstructured data became more and more common, including emails, papers, IoT sensor data, Facebook photos, protein structures, and much more.")
).toDF("id", "text")
// Write to MySQL Table
sampleDF.write
.mode(SaveMode.Append)
.format("jdbc")
.option("driver","com.mysql.cj.jdbc.Driver")
.option("url", "jdbc:mysql://localhost:3306/test")
.option("dbtable", "demo")
.option("user", "root")
.option("password", "123456")
.save()
// Read from MySQL Table
val dfMysql = spark.read
.format("jdbc")
.option("driver","com.mysql.cj.jdbc.Driver")
.option("url", "jdbc:mysql://localhost:3306/test")
.option("dbtable", "demo")
.option("user", "root")
.option("password", "123456")
.load()
val tokenizer = new Tokenizer().setInputCol("text").setOutputCol("tokens")
val tokenizedDf = tokenizer.transform(dfMysql)
// Learn a mapping from words to Vectors.
val word2Vec = new Word2Vec()
.setInputCol("tokens")
.setOutputCol("vectors")
.setVectorSize(128)
.setMinCount(0)
val model = word2Vec.fit(tokenizedDf)
val result = model.transform(tokenizedDf)
val vectorToArrayUDF = udf((v: Vector) => v.toArray)
// Apply the UDF to the DataFrame
val resultDF = result.withColumn("embedding", vectorToArrayUDF($"vectors"))
val milvusDf = resultDF.drop("tokens").drop("vectors")
milvusDf.write.format("milvus")
.option(MILVUS_HOST, "localhost")
.option(MILVUS_PORT, "19530")
.option(MILVUS_COLLECTION_NAME, "text_embedding")
.option(MILVUS_COLLECTION_VECTOR_FIELD, "embedding")
.option(MILVUS_COLLECTION_VECTOR_DIM, "128")
.option(MILVUS_COLLECTION_PRIMARY_KEY, "id")
.mode(SaveMode.Append)
.save()
}
Milvus -> Transformieren -> Milvus
In dieser Demo werden wir
- Daten aus einer Milvus-Sammlung lesen,
- eine Transformation anwenden (mit PCA als Beispiel) und
- die transformierten Daten über die Bulkinsert-API in ein anderes Milvus schreiben.
Das PCA-Modell ist ein Transformationsmodell, das die Dimensionalität von Einbettungsvektoren reduziert, was eine übliche Operation beim maschinellen Lernen ist. Sie können dem Transformationsschritt beliebige andere Verarbeitungsoperationen hinzufügen, wie z. B. Filtern, Verbinden oder Normalisieren.
import org.apache.spark.ml.feature.PCA
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.udf
import org.apache.spark.sql.util.CaseInsensitiveStringMap
import zilliztech.spark.milvus.{MilvusOptions, MilvusUtils}
import scala.collection.JavaConverters._
object TransformDemo extends App {
val sparkConf = new SparkConf().setMaster("local")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
val host = "localhost"
val port = 19530
val user = "root"
val password = "Milvus"
val fs = "s3a://"
val bucketName = "a-bucket"
val rootPath = "files"
val minioAK = "minioadmin"
val minioSK = "minioadmin"
val minioEndpoint = "localhost:9000"
val collectionName = "hello_spark_milvus1"
val targetCollectionName = "hello_spark_milvus2"
val properties = Map(
MilvusOptions.MILVUS_HOST -> host,
MilvusOptions.MILVUS_PORT -> port.toString,
MilvusOptions.MILVUS_COLLECTION_NAME -> collectionName,
MilvusOptions.MILVUS_BUCKET -> bucketName,
MilvusOptions.MILVUS_ROOTPATH -> rootPath,
MilvusOptions.MILVUS_FS -> fs,
MilvusOptions.MILVUS_STORAGE_ENDPOINT -> minioEndpoint,
MilvusOptions.MILVUS_STORAGE_USER -> minioAK,
MilvusOptions.MILVUS_STORAGE_PASSWORD -> minioSK,
)
// 1, configurations
val milvusOptions = new MilvusOptions(new CaseInsensitiveStringMap(properties.asJava))
// 2, batch read milvus collection data to dataframe
// Schema: dim of `embeddings` is 8
// +-+------------+------------+------------------+
// | | field name | field type | other attributes |
// +-+------------+------------+------------------+
// |1| "pk" | Int64 | is_primary=True |
// | | | | auto_id=False |
// +-+------------+------------+------------------+
// |2| "random" | Double | |
// +-+------------+------------+------------------+
// |3|"embeddings"| FloatVector| dim=8 |
// +-+------------+------------+------------------+
val arrayToVectorUDF = udf((arr: Seq[Double]) => Vectors.dense(arr.toArray[Double]))
val collectionDF = MilvusUtils.readMilvusCollection(spark, milvusOptions)
.withColumn("embeddings_vec", arrayToVectorUDF($"embeddings"))
.drop("embeddings")
// 3. Use PCA to reduce dim of vector
val dim = 4
val pca = new PCA()
.setInputCol("embeddings_vec")
.setOutputCol("pca_vec")
.setK(dim)
.fit(collectionDF)
val vectorToArrayUDF = udf((v: Vector) => v.toArray)
// embeddings dim number reduce to 4
// +-+------------+------------+------------------+
// | | field name | field type | other attributes |
// +-+------------+------------+------------------+
// |1| "pk" | Int64 | is_primary=True |
// | | | | auto_id=False |
// +-+------------+------------+------------------+
// |2| "random" | Double | |
// +-+------------+------------+------------------+
// |3|"embeddings"| FloatVector| dim=4 |
// +-+------------+------------+------------------+
val pcaDf = pca.transform(collectionDF)
.withColumn("embeddings", vectorToArrayUDF($"pca_vec"))
.select("pk", "random", "embeddings")
// 4. Write PCAed data to S3
val outputPath = "s3a://a-bucket/result"
pcaDf.write
.mode("overwrite")
.format("parquet")
.save(outputPath)
// 5. Config MilvusOptions of target table
val targetProperties = Map(
MilvusOptions.MILVUS_HOST -> host,
MilvusOptions.MILVUS_PORT -> port.toString,
MilvusOptions.MILVUS_COLLECTION_NAME -> targetCollectionName,
MilvusOptions.MILVUS_BUCKET -> bucketName,
MilvusOptions.MILVUS_ROOTPATH -> rootPath,
MilvusOptions.MILVUS_FS -> fs,
MilvusOptions.MILVUS_STORAGE_ENDPOINT -> minioEndpoint,
MilvusOptions.MILVUS_STORAGE_USER -> minioAK,
MilvusOptions.MILVUS_STORAGE_PASSWORD -> minioSK,
)
val targetMilvusOptions = new MilvusOptions(new CaseInsensitiveStringMap(targetProperties.asJava))
// 6. Bulkinsert Spark output files into milvus
MilvusUtils.bulkInsertFromSpark(spark, targetMilvusOptions, outputPath, "parquet")
}
Databricks -> Zilliz Cloud
Wenn Sie Zilliz Cloud (den verwalteten Milvus-Dienst) verwenden, können Sie dessen praktische Datenimport-API nutzen. Zilliz Cloud bietet umfassende Tools und Dokumentation, die Ihnen helfen, Ihre Daten aus verschiedenen Datenquellen, einschließlich Spark und Databricks, effizient zu übertragen. Richten Sie einfach einen S3-Bucket als Vermittler ein und öffnen Sie dessen Zugang zu Ihrem Zilliz Cloud-Konto. Die Datenimport-API der Zilliz Cloud lädt automatisch den kompletten Datenstapel aus dem S3-Bucket in Ihren Zilliz Cloud-Cluster.
Vorbereitungen
Laden Sie die Spark-Laufzeitumgebung, indem Sie eine jar-Datei zu Ihrem Databricks-Cluster hinzufügen.
Sie können eine Bibliothek auf verschiedene Arten installieren. Dieser Screenshot zeigt das Hochladen einer jar-Datei von lokal auf den Cluster. Weitere Informationen finden Sie unter Cluster-Bibliotheken in der Databricks-Dokumentation.
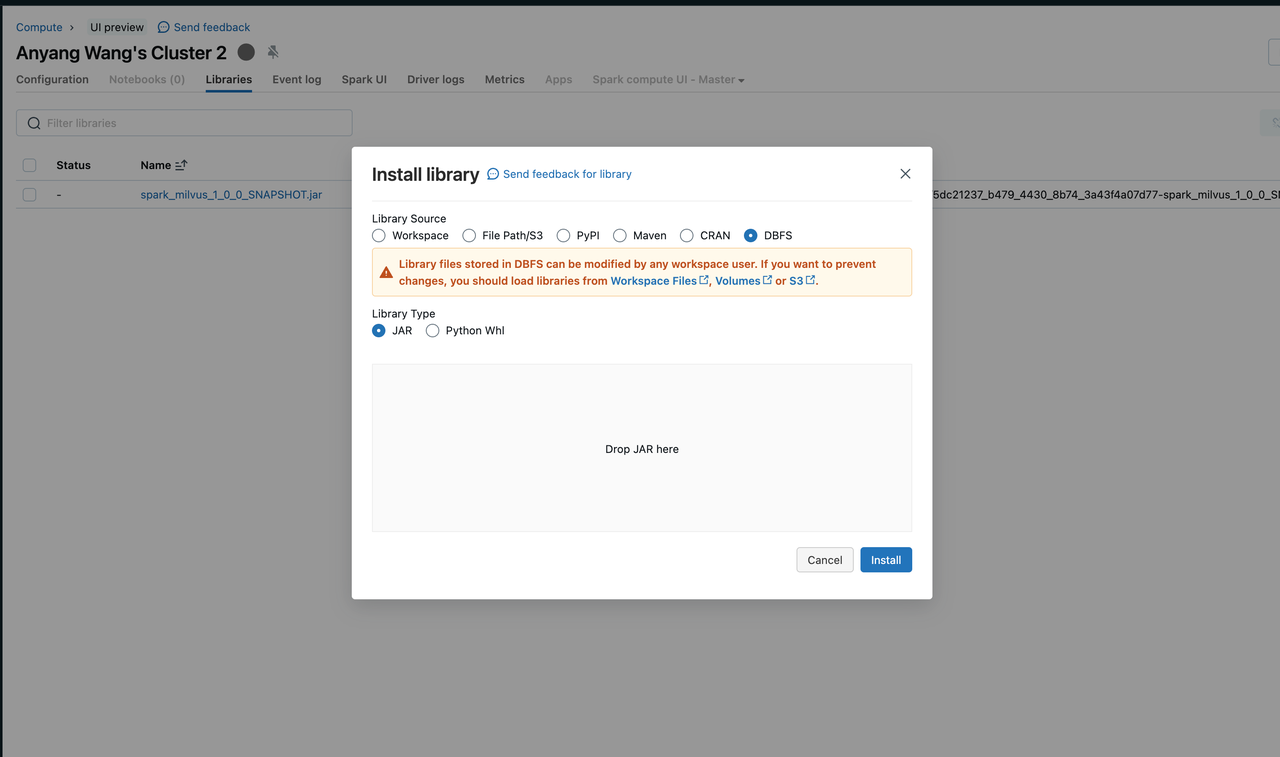 Databricks-Bibliothek installieren
Databricks-Bibliothek installieren Erstellen Sie ein S3-Bucket und konfigurieren Sie es als externen Speicherort für Ihren Databricks-Cluster.
Bulkinsert benötigt Daten, die in einem temporären Bucket gespeichert werden, damit Zilliz Cloud die Daten in einem Batch importieren kann. Sie können einen S3-Bucket erstellen und ihn als externen Speicherort von Databricks konfigurieren. Weitere Informationen finden Sie unter Externe Speicherorte.
Sichern Sie Ihre Databricks-Anmeldeinformationen.
Weitere Einzelheiten finden Sie in der Anleitung im Blog Sichere Verwaltung von Anmeldeinformationen in Databricks.
Demo
Hier ist ein Codeschnipsel, der den Batch-Datenmigrationsprozess veranschaulicht. Ähnlich wie im obigen Milvus-Beispiel müssen Sie nur die Anmeldeinformationen und die Adresse des S3-Buckets ersetzen.
// Write the data in batch into the Milvus bucket storage.
val outputPath = "s3://my-temp-bucket/result"
df.write
.mode("overwrite")
.format("mjson")
.save(outputPath)
// Specify Milvus options.
val targetProperties = Map(
MilvusOptions.MILVUS_URI -> zilliz_uri,
MilvusOptions.MILVUS_TOKEN -> zilliz_token,
MilvusOptions.MILVUS_COLLECTION_NAME -> targetCollectionName,
MilvusOptions.MILVUS_BUCKET -> bucketName,
MilvusOptions.MILVUS_ROOTPATH -> rootPath,
MilvusOptions.MILVUS_FS -> fs,
MilvusOptions.MILVUS_STORAGE_ENDPOINT -> minioEndpoint,
MilvusOptions.MILVUS_STORAGE_USER -> minioAK,
MilvusOptions.MILVUS_STORAGE_PASSWORD -> minioSK,
)
val targetMilvusOptions = new MilvusOptions(new CaseInsensitiveStringMap(targetProperties.asJava))
// Bulk insert Spark output files into Milvus
MilvusUtils.bulkInsertFromSpark(spark, targetMilvusOptions, outputPath, "mjson")
Praktisches Notizbuch
Um Ihnen einen schnellen Einstieg in den Spark-Milvus-Connector zu ermöglichen, können Sie das Notebook ausleihen, das Sie durch die Streaming- und Batch-Dateningestion-Beispiele für Spark zu Milvus und Zilliz Cloud führt.