![]()
Improve retrieval quality of your LLM Application with AIMon and Milvus
Overview
In this tutorial, we’ll help you build a retrieval-augmented generation (RAG) chatbot that answers questions on a meeting bank dataset.
In this tutorial you will learn to:
- Build an LLM application that answers a user’s query related to the meeting bank dataset.
- Define and measure the quality of your LLM application.
- Improve the quality of your application using 2 incremental approaches: a vector DB using hybrid search and a state-of-the-art re-ranker.
Tech Stack
Vector Database
For this application, we will use Milvus to manage and search large-scale unstructured data, such as text, images, and videos.
LLM Framework
LlamaIndex is an open-source data orchestration framework that simplifies building large language model (LLM) applications by facilitating the integration of private data with LLMs, enabling context-augmented generative AI applications through a Retrieval-Augmented Generation (RAG) pipeline. We will use LlamaIndex for this tutorial since it offers a good amount of flexibility and better lower level API abstractions.
LLM Output Quality Evaluation
AIMon offers proprietary Judge models for Hallucination, Context Quality issues, Instruction Adherence of LLMs, Retrieval Quality and other LLM reliability tasks. We will use AIMon to judge the quality of the LLM application.
$ pip3 install -U gdown requests aimon llama-index-core llama-index-vector-stores-milvus pymilvus>=2.4.2 milvus-lite llama-index-postprocessor-aimon-rerank llama-index-embeddings-openai llama-index-llms-openai datasets fuzzywuzzy --quiet
Pre-requisites
- Signup for an AIMon account here.
Add this secret to the Colab Secrets (the “key” symbol on the left panel)
If you are in another non-google colab environment, please replace the google colab-related code yourself
- AIMON_API_KEY
- Signup for an OpenAI account here and add the following key in Colab secrets:
- OPENAI_API_KEY
Required API keys
import os
# Check if the secrets are accessible
from google.colab import userdata
# Get this from the AIMon UI
aimon_key = userdata.get("AIMON_API_KEY")
openai_key = userdata.get("OPENAI_API_KEY")
# Set OpenAI key as an environment variable as well
os.environ["OPENAI_API_KEY"] = openai_key
Utility Functions
This section contains utility functions that we will use throughout the notebook.
from openai import OpenAI
oai_client = OpenAI(api_key=openai_key)
def query_openai_with_context(query, context_documents, model="gpt-4o-mini"):
"""
Sends a query along with context documents to the OpenAI API and returns the parsed response.
:param api_key: OpenAI API key
:param query: The user's query as a string
:param context_documents: A list of strings representing context documents
:param model: The OpenAI model to use (default is 'o3-mini')
:return: Response text from the OpenAI API
"""
# Combine context documents into a single string
context_text = "\n\n".join(context_documents)
# Construct the messages payload
messages = [
{
"role": "system",
"content": "You are an AI assistant that provides accurate and helpful answers.",
},
{"role": "user", "content": f"Context:\n{context_text}\n\nQuestion:\n{query}"},
]
# Call OpenAI API
completion = oai_client.chat.completions.create(model=model, messages=messages)
# Extract and return the response text
return completion.choices[0].message.content
Dataset
We will use the MeetingBank dataset which is a benchmark dataset created from the city councils of 6 major U.S. cities to supplement existing datasets. It contains 1,366 meetings with over 3,579 hours of video, as well as transcripts, PDF documents of meeting minutes, agenda, and other metadata.
For this exercise, we have created a smaller dataset. It can be found here.
# Delete the dataset folder if it already exists
import shutil
folder_path = "/content/meetingbank_train_split.hf"
if os.path.exists(folder_path):
try:
shutil.rmtree(folder_path)
print(f"Folder '{folder_path}' and its contents deleted successfully.")
except Exception as e:
print(f"Error deleting folder '{folder_path}': {e}")
else:
print(f"Folder '{folder_path}' does not exist.")
Folder '/content/meetingbank_train_split.hf' does not exist.
# Download the dataset locally
$ gdown https://drive.google.com/uc?id=1bs4kwwiD30DUeCjuqEdOeixCuI-3i9F5
$ gdown https://drive.google.com/uc?id=1fkxaS8eltjfkzws5BRXpVXnxl2Qxwy5F
Downloading...
From: https://drive.google.com/uc?id=1bs4kwwiD30DUeCjuqEdOeixCuI-3i9F5
To: /content/meetingbank_train_split.tar.gz
100% 1.87M/1.87M [00:00<00:00, 104MB/s]
Downloading...
From: https://drive.google.com/uc?id=1fkxaS8eltjfkzws5BRXpVXnxl2Qxwy5F
To: /content/score_metrics_relevant_examples_2.csv
100% 163k/163k [00:00<00:00, 69.6MB/s]
import tarfile
from datasets import load_from_disk
tar_file_path = "/content/meetingbank_train_split.tar.gz"
extract_path = "/content/"
# Extract the file
with tarfile.open(tar_file_path, "r:gz") as tar:
tar.extractall(path=extract_path)
print(f"Extracted to: {extract_path}")
train_split = load_from_disk(extract_path + "meetingbank_train_split.hf")
Extracted to: /content/
len(train_split)
258
# Total number of token across the entire set of transcripts
# This is approximately 15M tokens in size
total_tokens = sum(len(example["transcript"].split()) for example in train_split)
print(f"Total number of tokens in train split: {total_tokens}")
Total number of tokens in train split: 996944
# number of words ~= # of tokens
len(train_split[1]["transcript"].split())
3137
# Show the first 500 characters of the transcript
train_split[1]["transcript"][:500]
"An assessment has called out council bill 161 for an amendment. Madam Secretary, will you please put 161 on the screen? Councilman Lopez, will you make a motion to take 161 out of order? Want to remind everyone this motion is not debatable. Thank you, Mr. President. I move to take Council Bill 161 series of 2017. Out of order. All right. It's been moved the second it. Madam Secretary, roll call. SUSSMAN All right, Black. CLARK All right. Espinosa. Flynn. Gilmore. Herndon. Cashman can eat. LOPEZ "
# Average number of tokens per transcript
import statistics
statistics.mean(len(example["transcript"].split()) for example in train_split)
3864.124031007752
Analysis
We have 258 transcripts with a total of about 1M tokens across all these transcripts. We have an average of 3864 number of tokens per transcript.
| Metric | Value |
|---|---|
| Number of transcripts | 258 |
| Total # tokens in the transcripts | 1M |
| Avg. # tokens per transcript | 3864 |
Queries
Below are the 12 queries that we will run on the transcript above
import pandas as pd
queries_df = pd.read_csv("/content/score_metrics_relevant_examples_2.csv")
len(queries_df["Query"])
12
queries_df["Query"].to_list()
['What was the key decision in the meeting?',
'What are the next steps for the team?',
'Summarize the meeting in 10 words.',
'What were the main points of discussion?',
'What decision was made regarding the project?',
'What were the outcomes of the meeting?',
'What was discussed in the meeting?',
'What examples were discussed for project inspiration?',
'What considerations were made for the project timeline?',
'Who is responsible for completing the tasks?',
'What were the decisions made in the meeting?',
'What did the team decide about the project timeline?']
Metric Definition
This quality score metric will help us understand how good the LLM responses are for the set of queries above. To measure quality of our application, we will run a set of queries and aggregate the quality scores across all these queries.
LLM Application Quality Score is a combination of 3 individual quality metrics from AIMon:
- Hallucination Score (hall_score): checks if the generated text is grounded in the provided context. A score closer to 1.0 means that there is a strong indication of hallucination and a score closer to 0.0 means a lower indication of hallucination. Hence, we will use (1.0-hall_score) here when computing the final quality score.
- Instruction Adherence Score (ia_score): checks if all explicit instructions provided have been followed by the LLM. The higher the ia_score the better the adherence to instructions. The lower the score, the poorer the adherence to instructions.
- Retrieval Relevance Score (rr_score): checks if the retrieved documents are relevant to the query. A score closer to 100.0 means perfect relevance of document to query and a score closer to 0.0 means poor relevance of document to query.
quality_score = 0.35 * (1.0 - hall_score) + 0.35 * ia_score + 0.3 * rr_score
# We will check the LLM response against these instructions
instructions_to_evaluate = """
1. Ensure that the response answers all parts of the query completely.
2. Ensure that the length of the response is under 50 words.
3. The response must not contain any abusive language or toxic content.
4. The response must be in a friendly tone.
"""
def compute_quality_score(aimon_response):
retrieval_rel_scores = aimon_response.detect_response.retrieval_relevance[0][
"relevance_scores"
]
avg_retrieval_relevance_score = (
statistics.mean(retrieval_rel_scores) if len(retrieval_rel_scores) > 0 else 0.0
)
hall_score = aimon_response.detect_response.hallucination["score"]
ia_score = aimon_response.detect_response.instruction_adherence["score"]
return (
0.35 * (1.0 - hall_score)
+ 0.35 * ia_score
+ 0.3 * (avg_retrieval_relevance_score / 100)
) * 100.0
Setup AIMon
As mentioned previously, AIMon will be used to judge the quality of the LLM application. Documentation can be found here.
from aimon import Detect
aimon_config = {
"hallucination": {"detector_name": "default"},
"instruction_adherence": {"detector_name": "default"},
"retrieval_relevance": {"detector_name": "default"},
}
task_definition = """
Your task is to grade the relevance of context document against a specified user query.
The domain here is a meeting transcripts.
"""
values_returned = [
"context",
"user_query",
"instructions",
"generated_text",
"task_definition",
]
detect = Detect(
values_returned=values_returned,
api_key=userdata.get("AIMON_API_KEY"),
config=aimon_config,
publish=True, # This publishes results to the AIMon UI
application_name="meeting_bot_app",
model_name="OpenAI-gpt-4o-mini",
)
1. Simple, brute-force approach
In this first simple approach, we will use Levenshtein Distance to match a document with a given query. The top 3 documents with the best match will be sent to the LLM as context for answering.
NOTE: This cell will take about 3 mins to execute
Enjoy your favorite beverage while you wait :)
from fuzzywuzzy import process
import time
# List of documents
documents = [t["transcript"] for t in train_split]
@detect
def get_fuzzy_match_response(query, docs):
response = query_openai_with_context(query, docs)
return docs, query, instructions_to_evaluate, response, task_definition
st = time.time()
quality_scores_bf = []
avg_retrieval_rel_scores_bf = []
responses = {}
for user_query in queries_df["Query"].to_list():
best_match = process.extractBests(user_query, documents)
matched_docs = [b[0][:2000] for b in best_match]
_, _, _, llm_res, _, aimon_response = get_fuzzy_match_response(
user_query, matched_docs[:1]
)
# These show the average retrieval relevance scores per query.
retrieval_rel_scores = aimon_response.detect_response.retrieval_relevance[0][
"relevance_scores"
]
avg_retrieval_rel_score_per_query = (
statistics.mean(retrieval_rel_scores) if len(retrieval_rel_scores) > 0 else 0.0
)
avg_retrieval_rel_scores_bf.append(avg_retrieval_rel_score_per_query)
print(
"Avg. Retrieval relevance score across chunks: {} for query: {}".format(
avg_retrieval_rel_score_per_query, user_query
)
)
quality_scores_bf.append(compute_quality_score(aimon_response))
responses[user_query] = llm_res
print("Time taken: {} seconds".format(time.time() - st))
/usr/local/lib/python3.11/dist-packages/fuzzywuzzy/fuzz.py:11: UserWarning: Using slow pure-python SequenceMatcher. Install python-Levenshtein to remove this warning
warnings.warn('Using slow pure-python SequenceMatcher. Install python-Levenshtein to remove this warning')
Avg. Retrieval relevance score across chunks: 14.276227385821016 for query: What was the key decision in the meeting?
Avg. Retrieval relevance score across chunks: 13.863050225148754 for query: What are the next steps for the team?
Avg. Retrieval relevance score across chunks: 9.684561480011666 for query: Summarize the meeting in 10 words.
Avg. Retrieval relevance score across chunks: 15.117995085759617 for query: What were the main points of discussion?
Avg. Retrieval relevance score across chunks: 15.017772942191954 for query: What decision was made regarding the project?
Avg. Retrieval relevance score across chunks: 14.351198844659052 for query: What were the outcomes of the meeting?
Avg. Retrieval relevance score across chunks: 17.26337936069342 for query: What was discussed in the meeting?
Avg. Retrieval relevance score across chunks: 14.45748737410213 for query: What examples were discussed for project inspiration?
Avg. Retrieval relevance score across chunks: 14.69838895812785 for query: What considerations were made for the project timeline?
Avg. Retrieval relevance score across chunks: 11.528360411352168 for query: Who is responsible for completing the tasks?
Avg. Retrieval relevance score across chunks: 16.55915192723114 for query: What were the decisions made in the meeting?
Avg. Retrieval relevance score across chunks: 14.995106827925042 for query: What did the team decide about the project timeline?
Time taken: 169.34546852111816 seconds
# This is the average quality score.
avg_quality_score_bf = statistics.mean(quality_scores_bf)
print("Average Quality score for brute force approach: {}".format(avg_quality_score_bf))
Average Quality score for brute force approach: 51.750446187242254
# This is the average retrieval relevance score.
avg_retrieval_rel_score_bf = statistics.mean(avg_retrieval_rel_scores_bf)
print(
"Average retrieval relevance score for brute force approach: {}".format(
avg_retrieval_rel_score_bf
)
)
Average retrieval relevance score for brute force approach: 14.31772340191865
This is a baseline LLM app quality score. You can also see the individual metrics like hallucination scores etc. computed by AIMon on the AIMon UI
2. Use a VectorDB (Milvus) for document retrieval
Now, we will improve the quality score by adding in a vector DB. This will also help improve query latency compared to the previous approach.
There are two main components we need to be aware of: Ingestion and RAG based Q&A. The ingestion pipeline processes the transcripts from the Meeting Bank dataset and stores it in the Milvus Vector database. The RAG Q&A pipeline processes a user query by first retrieving the relevant documents from the vector store. These documents will then be used as grounding documents for the LLM to generate its response. We leverage AIMon to calculate the quality score and continuously monitor the application for hallucination, , instruction adherence, context relevance. These are the same 3 metrics we used to define the quality score above.
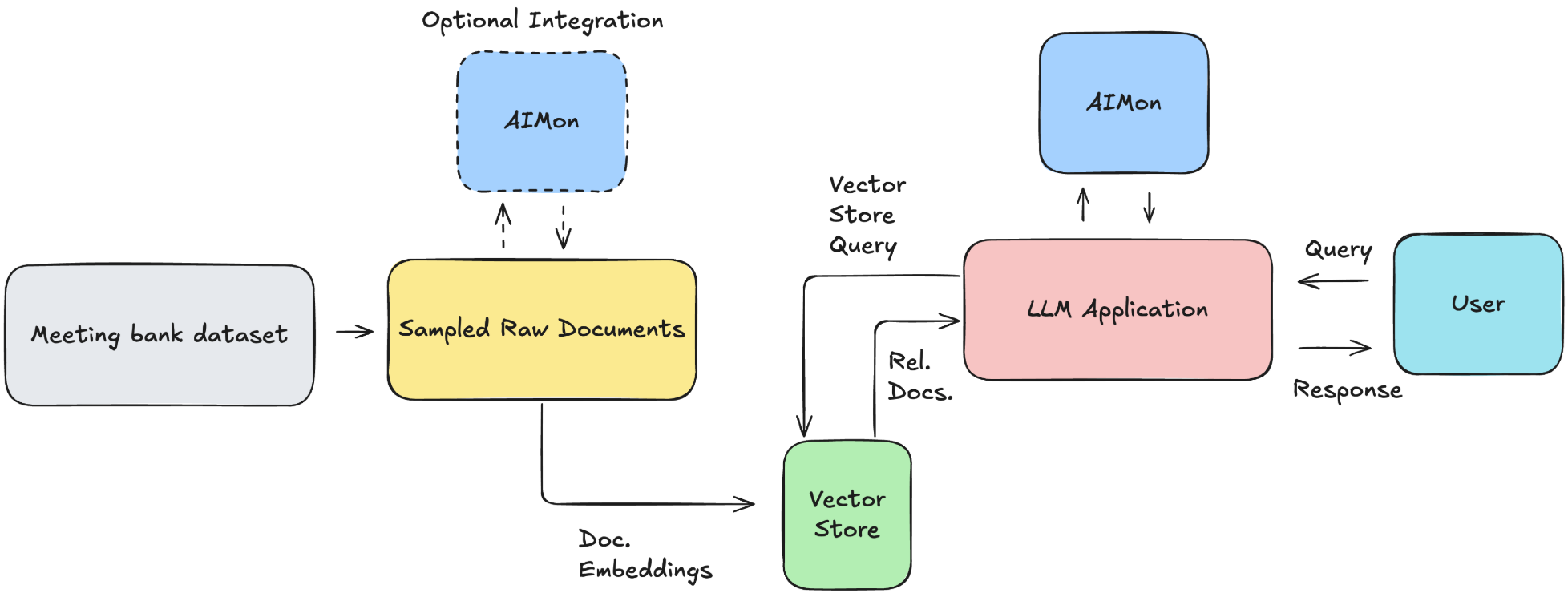 workflow
workflow
Below are some utility functions to pre-process and compute embeddings for documents.
import json
import requests
import pandas as pd
from llama_index.core import Document
## Function to preprocess text.
def preprocess_text(text):
text = " ".join(text.split())
return text
## Function to process all URLs and create LlamaIndex Documents.
def extract_and_create_documents(transcripts):
documents = []
for indx, t in enumerate(transcripts):
try:
clean_text = preprocess_text(t)
doc = Document(text=clean_text, metadata={"index": indx})
documents.append(doc)
except Exception as e:
print(f"Failed to process transcript number {indx}: {str(e)}")
return documents
documents = extract_and_create_documents(train_split["transcript"])
Setup an Open AI based embedding computation model.
from llama_index.embeddings.openai import OpenAIEmbedding
embedding_model = OpenAIEmbedding(
model="text-embedding-3-small", embed_batch_size=100, max_retries=3
)
In this cell, we compute the embeddings for the documents and index them into the MilvusVectorStore.
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.milvus import MilvusVectorStore
vector_store = MilvusVectorStore(
uri="./aimon_embeddings.db",
collection_name="meetingbanks",
dim=1536,
overwrite=True,
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents=documents, storage_context=storage_context
)
2025-04-10 20:40:51,855 [DEBUG][_create_connection]: Created new connection using: 24fee991f1f64fadb3461a7d99fcd4dd (async_milvus_client.py:600)
Execution time: 38.74 seconds
Now that the VectorDB index has been setup, we will leverage it to answer user queries. In the cells below, we will create a retriever, setup the LLM and build a LLamaIndex Query Engine that interfaces with the retriever and the LLM to answer a user’s questions.
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
retriever = VectorIndexRetriever(index=index, similarity_top_k=5)
# The system prompt that will be used for the LLM
system_prompt = """
Please be professional and polite.
Answer the user's question in a single line.
"""
## OpenAI's LLM, we will use GPT-4o-mini here since it is a fast and cheap LLM
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-4o-mini", temperature=0.1, system_prompt=system_prompt)
from llama_index.core.query_engine import RetrieverQueryEngine
query_engine = RetrieverQueryEngine.from_args(retriever, llm)
At this point, the query engine, retriever and LLM has been setup. Next, we setup AIMon to help us measure quality scores. We use the same @detect decorator that was created in the previous cells above. The only additional code in ask_and_validate here is to help AIMon interface with LLamaIndex’s retrieved document "nodes".
import logging
@detect
def ask_and_validate(user_query, user_instructions, query_engine=query_engine):
response = query_engine.query(user_query)
## Nested function to retrieve context and relevance scores from the LLM response.
def get_source_docs(chat_response):
contexts = []
relevance_scores = []
if hasattr(chat_response, "source_nodes"):
for node in chat_response.source_nodes:
if (
hasattr(node, "node")
and hasattr(node.node, "text")
and hasattr(node, "score")
and node.score is not None
):
contexts.append(node.node.text)
relevance_scores.append(node.score)
elif (
hasattr(node, "text")
and hasattr(node, "score")
and node.score is not None
):
contexts.append(node.text)
relevance_scores.append(node.score)
else:
logging.info("Node does not have required attributes.")
else:
logging.info("No source_nodes attribute found in the chat response.")
return contexts, relevance_scores
context, relevance_scores = get_source_docs(response)
return context, user_query, user_instructions, response.response, task_definition
# Quick check to ensure everything is working with the vector DB
ask_and_validate("Councilman Lopez", instructions_to_evaluate)
(["I know in in New Mexico on some of the reservations, there are people actually doing filming, too, now of some of the elders to make sure that that history is documented and passed on, because it isn't translated in many of the history books you get in your public education system. So I again, just am happy to support this and again commend Councilman Lopez for his efforts in our Indian commission and the work that you all have done with our entire entire community. Thank you, Mr. President. Thank you, Councilwoman. Councilman Lopez, I see you back up. Yeah. You know, I wanted to really emphasize the 10th, Monday, the 10th and proclamation that will be here in the quarters we'd love for. And I wanted to make sure the community because we do have community folks, I want to make sure that we come back on the 10th because we would like to give not only the proclamation, but a copy of the bill over. Right. And and ceremoniously and also just for the community. I know this Saturday I didn't mention this, but the Saturday is going to be, in addition to all the events, a rally at the Capitol at 1130. I mean, 130, 130. You mean marches coming from all over the city and they're going to be here. Good celebration of all directions, all nations. And that that's really when you when you look at the what it really means is all directions all nations for went. Thank you. Thank you, Councilman Lopez. Madam Secretary. Raquel Lopez. Hi. New Ortega I Black High Clerk by Espinosa. By. Flynn. Hi Gilmore I Herndon in Cashman. I can eat. Mr. President. I please close voting in US results. 12 eyes. 12 eyes conceal. 801 passes. Thank you. Thank you. Thank you. You don't get many claps for votes anymore. Thank you. All right. We are moving to the Bloc votes. All other bills for introductions are now ordered published. Councilman, clerk, will you please put the resolutions for adoption and the bills for final considerations? Consideration for final passage on the floor. Thank you, Mr. President. I move that resolutions be adopted and bills on final consideration be placed upon final consideration, and do pass in a block for the following items. 539 811 816. 812. 813. 814. 820. 821. 822. 800. 815. Eight 1724. 761 797. All right. It has been moved. And second, it councilmembers. Please remember that this is a consent or block vote and you will need to vote I or otherwise. This is your last chance to call out an item for a separate vote. Madam Secretary, roll call. Black. I Clark. II. Espinosa, i Flynn, i Gilmore. I Herndon I Cashman. I can eat. I knew. I. Ortega, I. Mr. President. I. Please close the voting. Announce a results. 11 Eyes. 11 Eyes. The resolution resolutions have been adopted and bills have been placed on final consideration and do pass. Tonight there will be a required public hearing for Council Bill 430 Changes on a classification of four Geneva Court and Martin Luther King Jr Boulevard.",
"Thank you, gentlemen. Lopez, can you please place Council Bill 376 on the floor for a vote? Thank you, Madam President. I move that council bill three 76/3 of 2015 be placed upon final, final consideration and do pass. Thank you. It's been moved and seconded. Comments by members of council. Councilwoman Fox. Thank you, Madam President. This is an ordinance that lends money to a developer for relocation costs of a project that's very important along Morrison Road. I approve of the project. I even approve of doing this relocation cost. But I am not willing to do is to lend more money to this specific developer. In a previous deal we had not only a financial deal with the developer, but there were two subsequent amendments to that deal, both of which were to the benefit of the developer, not the taxpayer. And so I am very picky about who I lend money to, and I'm going to say no today. Okay. Thank you, Councilman Lopez. Thank you, Madam President. I do have something to say about this council, bill. Yes? This is Saint Charles Holding Company as the developer of the site. Here's the problem. The problem is this site has been blighted for decades. And in this site, it's not like it's been empty. There have been folks who are living in these conditions that have been substandard and Denver and it's just not right. And we've talked about it for eight years. We looked at opportunities to what can we do to help improve the living conditions here for folks. And there was a lot of unanswered questions and a lot of people who how we had the ability to do it but are afraid to take the risk, afraid to do, afraid to come forward and basically not participate at all. That was true up into the point where Saint Charles Town Company and I think Charles Holding Company here said, you know, we'll do it. Will help will help not only improve the conditions here at this site by acquiring it, but will help trigger the Federal Relocation Act with the city. The city said, we will do this with you. There are folks who are living there who, because of this development, will be able to finally live anywhere else, be able to get benefits for it, relocation costs. And when all these units are built at 60%, am I going to be able to have first refusal, meaning they get the first choice to come back and this is how it should happen. And we can't rely just on VHA or some of the nonprofit folks who are already up. You know, they have their hands full. They don't have enough resources. They're begging for money. They're all fighting over the same pot of money, the same federal pot of money. It should we should actually be working with folks who are in the for profit development side that are willing to do this. And they've done it before on Alameda and Sheridan with those altos down. I mean, it's a very good project, filled a huge need in this city for affordable housing. That's what this does. And now affordable housing in the kind where you know that nobody takes care of and it's forgotten about. And when you complain, you either get kicked out or you just deal with it. Right. But this is the kind of housing these are the kind of units, units that will be maintained that are high quality standard of living, exactly what folks are needing and deserving in this neighborhood. And these are the folks that are willing to do the work. They've been doing the work with the community. It takes partnership from the city. This will help finalize those costs, help those folks find a place to live that way. They're not on the street while this develops or when they come back. I guarantee everybody is going to be standing there wanting to cut that ribbon. So that's what this is all about. And I urge my colleagues to support it. Thank you. Thank you, Councilman Lopez. Madam Secretary. Roll call. Fats? No. Lemon Lopez Monteiro. Hi, Nevitt. Hi, Ortega. Hi, Rob. Shepherd Sussman. Hi, Brooks. Hi, Brown. Hi, Sussman. There's no opportunity for me to click on I. Okay, I'll do it. Madam President. I voted. I call to him. He says, When were you able to vote? No, there's no. I voted for her. Okay. And what was the vote? Yes.",
"This year we may talk trash once in a while, but a manager got an AHA. You run a very good shop with a great manager at his helm. So thank you. Thank you, Councilman Lopez, Councilwoman Monteiro. And thank you, Madam President. I also want to take the opportunity to extend my appreciation. I wish I knew all 1100 employees. But here's what I do know that public works does everything from Keep Denver Beautiful this far as graffiti, graffiti removal all the way to major projects. I'm very mindful of the role that Public Works played in the redevelopment of Denver Union Station and the work that you're doing currently regarding I-70 and the National Western Stock Show. And we couldn't we couldn't do wouldn't be responsive if we didn't have the help of solid waste. Also, permitting and enforcement have worked with a lot of people, their street maintenance. And then of course, Nancy, I have an inbox of a lot of emails that you and I have, so I'm going to have to start deleting some of those. I also want to extend my thank you to host Cornell for all of the work that you do and that and for your steadfast, steadfast leadership. And also to George Delaney, who you're there when Jose is away from the helm. And I really appreciate that. So congratulations again. Let me see if I got these names right. Jason, Chloe, Adrian, Luis, Jeremy, Cindy, Patrick and Ron. So I hope I got everybody's name. Thank you. Thank you, Counselor Monteiro. All right. Looks like we're ready for the vote. Rob, I. Shepherd, I. But I. Herndon, I can eat lemon. Lopez All right. Monteiro I love it. Hi, Ortega. Hi. Madam President. I am close to voting out the results. 11 eyes. 11 eyes. The proclamation is adopted, Councilman Roberts or somebody would like to call up to the podium. Yes, Madam President, I expected my colleagues to support this, but I hope no one out there was sort of insulted with some of the comments. I would like to call up the interesting, sexy, cool and strong executive director of the Public Works Department, which is an interesting, sexy, cool and strong department. Good one. Councilwoman Rob. Cook. I'm single network secretary, director of Public Works and I want to thank on behalf of Public Works this proclamation. It is truly an honor to be part of this organization and work with these 1100 people that I would say are fully committed not only to the council priority by the mayor's priorities, but also the stakeholders priorities, and be able to mix all these priorities together and come up with public works priority, which is to create a smart city, meaning a sustainable city, a city that provides mobility in a safe way and attractive city resiliency, and also a process to be the most transparent process that we can deliver. Somebody says, I was reading this book the other day. Somebody says that the public space is the the visible face of society. And I do believe that. I think that that's how we judge cities when we go around the world and come back. I like to talk a little bit, spend a little bit of time talking about the ten employees that we're honoring tonight, because I think it's very important to mention exactly what these employees have been working and being part of. Jason Rediker from Capital Management recently designed two very critical storm sewer projects. One of them have been in neighborhood. And the other one is at first and university, which is under construction in your district. Chloe Thompson from Finance Administration. She is one of our first black built from the academy. She has worked very hard to improve and develop new models for for the financial track in streamlining contracts, contracting and putting in place a more efficient procurement process. Adrian Goldman from Fleet Management. Adrian was very close with our fleet technicians downloading software that helps to better diagnose vehicles and speed up the repair process. Lewis Gardner From Right of Way Enforcement in permitting, Lewis is a very diligent vehicle investigator who goes above and beyond to assist not only the public but also the the in the agency. He volunteers to maintain city's vehicle inventory and has taken the lead role a role a role in making sure that the motors workshop is free of hazardous materials and and mark problems. Jeremy Hammer from right of way services. He's our lead on floodplain issues. He's responsible for very complex flood floodplains and drainage issues.",
"So. So I think that this is a fitting combination to have these tonight. And I will be happily voting in support of this. Thank you. Thank you, Councilwoman. Councilman Espinosa, I saw you click in. I did, but I. I'll reserve my comments. Okay, great. We have. Let's see. No other comments. Councilman Ortega. Sorry, is shown on my screen. I'm not sure why it's not on yours. Thank you. I just wanted to make a few brief comments as well and thank Councilman Lopez for his efforts in working with the community to bring this forward. And I know this is something that has been in the works for a very long time. So thank you for your efforts. I just. Think that it's important also to mention the role that our Native American community played in. You heard me talk about DIA earlier. When we were moving forward with the construction of the highway, one of the things that happened was we worked with some of the tribal leaders to do a ground blessing on the site. As you all know, that used to be part of the old Sand Creek Massacre corridor. And I thought it was extremely important for Denver to do that. And the interesting thing about the event was the media wanted to know when and where it was going to take place. And I worked with Mayor Webb at the time to ensure that that happened. I didn't attend it. We made sure the media didn't know when and where it was because it was, you know, a very traditional sacred event that needed to take place and to, you know, pray for the lives of of the souls who were lost in that massacre. The other thing that Councilman Lopez talked about was the the history of where Denver started. It started with our Native American community right at the at the core of the Confluence Park. The city acknowledges that to the degree of seeing a number of the the parks, I mean, not the parks, but the roads down in the lower downtown and platte valley area named after some of the tribal leaders. We want to wynkoop a little raven. I remember when the naming of little raven was being proposed. Our public works department was recommending that that be called 29th Street. And I just you know, I was the councilperson of the district at the time. And I said, how do we make these decisions about what streets, what we're naming our streets? And I said, What other names did you look at? And they mentioned Little Raven. And this was when they were bringing through the committee process to do the official naming. And I said, I want it named Little Raven. And so when when that official, you know, name was put up on the street, we actually had some of the tribal leaders from the Cheyenne tribe there, and they actually were given a street sign that they were able to take and put up on display in their community. So just being part of so many of the things that have happened in this city is exciting. I worked at the state capitol when the Commission in Indian Affairs was created in George Brown's office. The lieutenant governors, it's been part of that office. I worked there and had the benefit of going to a peace treaty signing ceremony between the U.S. and the Comanches, who had been at war with each other for for 100 years. And a lot of these things, as Councilman Lopez said, are not written in our history books. You know, you in and one of the things that's occurring and those of you who have not taken the time to talk to your elders and record some of the history so that you pass it on to, you know, our children is is so important. I know in in New Mexico on some of the reservations, there are people actually doing filming, too, now of some of the elders to make sure that that history is documented and passed on, because it isn't translated in many of the history books you get in your public education system. So I again, just am happy to support this and again commend Councilman Lopez for his efforts in our Indian commission and the work that you all have done with our entire entire community. Thank you, Mr. President. Thank you, Councilwoman. Councilman Lopez, I see you back up. Yeah. You know, I wanted to really emphasize the 10th, Monday, the 10th and proclamation that will be here in the quarters we'd love for.",
"President. I call Madam Speaker, close voting. Announce the results. 3913 eyes. Constable 898 has been amended. Councilman Lopez, please. We need a motion to pass as amended now. Mr. President, I move that council bill 898 series of 2016 be moved and be passed on final, final consideration as amended. Okay. It has been moved in second. It comes from members of council. It comes from our take as this from the prior. It was just hasn't gone away. All right. Madam Secretary, roll call. Can each I. LOPEZ All right. New ORTEGA High Assessment by Black. Clark by Espinosa. FLYNN Hi. Gilmore I Herndon. I Cashman. Hi, Mr. President. I Please close the voting and ask for results. 3913 Eyes Council Bill 898 has passed as amended. Okay, just want to make sure looking down the road, make sure there are no other items that need to be called out. We're ready for the block votes. All other bills for introduction are order published. We are now ready. So council members, please remember that this is a consent block vote and you will need to vote. Otherwise this is your last chance to call out an item for a separate votes. Guzman Lopez, will you please put the resolutions for adoption and the bills for final consideration for final passage on the floor? We put them both at the same time. Yeah. The read through. That's what we did last week. Yeah. And it's easy if you do it from the screen. All right. I motion to approve the consent agenda. So the motion would be. No. No, do I. Do I run through all those resolutions and bills? Yep. Just all of them at once. Yep. All right. Back in my day, we brought it on. Oh, I'm just kidding. All right, Mr. President. Okay. I move that. Our series of 2016, the following resolutions 1000 982 998, 1000 to 8, 79, 33, nine, 34, nine, 92 and 93, 96, 99, 1003. And the following bills for consideration to series at 2016 979 nine 8947 nine 5959 961 974, nine, 75 and 85 831 972 973. And 1978 be released upon. Of do pass in block. Okay. Madam Secretary, I think he got all of them. Yes. Would you concur? Okay, great. Rook for. Black Eye Clerk. By. Vanessa Flynn I. Gilmore, i. Herndon, i. Catherine Kennedy I. Lopez I knew Ortega i susman i. Mr. President. I 3939 resolutions have been adopted and bills have been placed upon final consideration and do pass tonight. Council is scheduled to sit as the quasi Judicial Board of Equalization to consider reduction of total cost assessments for the one local maintenance district."],
'Councilman Lopez',
'\n1. Ensure that the response answers all parts of the query completely.\n2. Ensure that the length of the response is under 50 words.\n3. The response must not contain any abusive language or toxic content.\n4. The response must be in a friendly tone.\n',
'Councilman Lopez has been actively involved in community efforts, particularly regarding the documentation of Native American history and supporting housing development projects.',
'\nYour task is to grade the relevance of context document against a specified user query.\nThe domain here is a meeting transcripts.\n',
DetectResult(
status=200,
detect_response=avg_context_doc_length: 18190.0
hallucination: {
"is_hallucinated": "False",
"score": 0.0696,
"sentences": [
{
"score": 0.0696,
"text": "Councilman Lopez has been actively involved in community efforts, particularly
regarding the documentation of Native American history and supporting housing development projects."
}
]
}
instruction_adherence: {
"results": [
{
"adherence": true,
"detailed_explanation": "The response addresses components related to Councilman Lopez's
community involvement and specific areas such as the documentation of Native American history and
housing projects, thus answering the query completely.",
"instruction": "Ensure that the response answers all parts of the query completely."
},
{
"adherence": true,
"detailed_explanation": "The response contains 23 words, which is under the specified
limit of 50 words.",
"instruction": "Ensure that the length of the response is under 50 words."
},
{
"adherence": true,
"detailed_explanation": "The response uses neutral and positive language without any
abusive or toxic content.",
"instruction": "The response must not contain any abusive language or toxic content."
},
{
"adherence": true,
"detailed_explanation": "The tone of the response is friendly and informative,
highlighting Councilman Lopez's positive contributions to the community.",
"instruction": "The response must be in a friendly tone."
}
],
"score": 1.0
}
retrieval_relevance: [
{
"explanations": [
"Document 1 discusses Councilman Lopez's efforts in the Indian commission and his
involvement in community events, directly referencing his name and contributions. However, the
document is lengthy and contains a lot of extraneous information about unrelated topics, which
dilutes the focus on Councilman Lopez and makes it less relevant to a query specifically seeking
information about him.",
"2. In Document 2, Councilman Lopez is mentioned in relation to a council bill and his
comments on a development project, which shows his active role in council discussions. The document,
however, focuses more on the specific project and other council members' opinions rather than
providing substantial information about Councilman Lopez himself, leading to a lower relevance
score.",
"3. Document 3 acknowledges Councilman Lopez in the context of public works and city
management, which shows that he is recognized for his contributions. However, the document primarily
discusses public works and does not delve deeply into Councilman Lopez's specific actions or
achievements, making it less relevant to the query.",
"4. In Document 4, Councilman Lopez is commended for his efforts in the community and
for working with the Native American community, indicating his involvement in significant local
issues. Yet, the document is more focused on the broader context of community history and events,
which detracts from a focused discussion on Councilman Lopez himself.",
"5. Document 5 mentions Councilman Lopez in the context of voting on a council bill and
procedural matters, showcasing his active participation in council decisions. However, it lacks
detailed insights into his specific contributions or perspectives regarding the bills, making it
less informative for someone looking for in-depth information about Councilman Lopez."
],
"query": "Councilman Lopez",
"relevance_scores": [
35.66559540012122,
37.18941956657886,
33.50108754888339,
33.29029488991324,
38.80187100744479
]
}
],
publish_response=[]
))
Lets run through all the queries through the LlamaIndex query engine in the queries_df and compute the overall quality score using AIMon.
NOTE: This will take about 2 mins
import time
quality_scores_vdb = []
avg_retrieval_rel_scores_vdb = []
responses_adb = {}
ast = time.time()
for user_query in queries_df["Query"].to_list():
_, _, _, llm_res, _, aimon_response = ask_and_validate(
user_query, instructions_to_evaluate
)
# These show the average retrieval relevance scores per query. Compare this to the previous brute force method.
retrieval_rel_scores = aimon_response.detect_response.retrieval_relevance[0][
"relevance_scores"
]
avg_retrieval_rel_score_per_query = (
statistics.mean(retrieval_rel_scores) if len(retrieval_rel_scores) > 0 else 0.0
)
avg_retrieval_rel_scores_vdb.append(avg_retrieval_rel_score_per_query)
print(
"Avg. Retrieval relevance score across chunks: {} for query: {}".format(
avg_retrieval_rel_score_per_query, user_query
)
)
quality_scores_vdb.append(compute_quality_score(aimon_response))
responses_adb[user_query] = llm_res
print("Time elapsed: {} seconds".format(time.time() - ast))
Avg. Retrieval relevance score across chunks: 19.932596854170086 for query: What was the key decision in the meeting?
Avg. Retrieval relevance score across chunks: 19.332469976717874 for query: What are the next steps for the team?
Avg. Retrieval relevance score across chunks: 13.695729082342893 for query: Summarize the meeting in 10 words.
Avg. Retrieval relevance score across chunks: 20.276701279455835 for query: What were the main points of discussion?
Avg. Retrieval relevance score across chunks: 19.642715112968148 for query: What decision was made regarding the project?
Avg. Retrieval relevance score across chunks: 17.880496811886246 for query: What were the outcomes of the meeting?
Avg. Retrieval relevance score across chunks: 23.53911458826815 for query: What was discussed in the meeting?
Avg. Retrieval relevance score across chunks: 17.665638657211105 for query: What examples were discussed for project inspiration?
Avg. Retrieval relevance score across chunks: 18.13388221868742 for query: What considerations were made for the project timeline?
Avg. Retrieval relevance score across chunks: 18.955595009379778 for query: Who is responsible for completing the tasks?
Avg. Retrieval relevance score across chunks: 22.840146597476263 for query: What were the decisions made in the meeting?
Avg. Retrieval relevance score across chunks: 19.665652140639054 for query: What did the team decide about the project timeline?
Time elapsed: 125.75674271583557 seconds
# This is the average quality score.
avg_quality_score_vdb = statistics.mean(quality_scores_vdb)
print("Average Quality score for vector DB approach: {}".format(avg_quality_score_vdb))
Average Quality score for vector DB approach: 67.1800392915634
# This is the average retrieval relevance score.
avg_retrieval_rel_score_vdb = statistics.mean(avg_retrieval_rel_scores_vdb)
print(
"Average retrieval relevance score for vector DB approach: {}".format(
avg_retrieval_rel_score_vdb
)
)
Average retrieval relevance score for vector DB approach: 19.296728194100236
🎉 Quality Score improved!
Notice that the overall quality score across all queries improved after using a RAG based QA system.
3. Add Re-ranking to your retrieval
Now, we will add in AIMon’s domain adaptable re-ranker using AIMon’s LlamaIndex postprocessor re-rank integration.
As shown in the figure below, reranking helps bubble up the most relevant documents to the top by using a more advanced Query-Document matching function. The unique feature of AIMon’s re-ranker is the ability to customize it per domain. Similar to how you would prompt engineer an LLM, you can customize reranking performance per domain using the task_definition field. This state-of-the-art reranker runs at ultra low sub second latency (for a ~2k context) and its performance ranks in the top 5 of the MTEB reranking leaderboard.

# Setup AIMon's reranker
from llama_index.postprocessor.aimon_rerank import AIMonRerank
# This is a simple task_definition, you can polish and customize it for your use cases as needed
task_definition = """
Your task is to match documents for a specific query.
The documents are transcripts of meetings of city councils of 6 major U.S. cities.
"""
aimon_rerank = AIMonRerank(
top_n=2,
api_key=userdata.get("AIMON_API_KEY"),
task_definition=task_definition,
)
# Setup a new query engine but now with a reranker added as a post processor after retrieval
query_engine_with_reranking = RetrieverQueryEngine.from_args(
retriever, llm, node_postprocessors=[aimon_rerank]
)
Let’s run through the queries again and recompute the overall quality score to see if there is an improvement.
✨ AIMon’s re-ranking should not add additional latency overhead since it actually reduces the amount of context documents that need to be sent to the LLM for generating a response making the operation efficient in terms of network I/O and LLM token processing cost (money and time).
NOTE: This step will take 2 mins
import time
qual_scores_rr = []
avg_retrieval_rel_scores_rr = []
responses_adb_rr = {}
ast_rr = time.time()
for user_query in queries_df["Query"].to_list():
_, _, _, llm_res, _, aimon_response = ask_and_validate(
user_query, instructions_to_evaluate, query_engine=query_engine_with_reranking
)
# These show the average retrieval relevance scores per query. Compare this to the previous method without the re-ranker
retrieval_rel_scores = aimon_response.detect_response.retrieval_relevance[0][
"relevance_scores"
]
avg_retrieval_rel_score_per_query = (
statistics.mean(retrieval_rel_scores) if len(retrieval_rel_scores) > 0 else 0.0
)
avg_retrieval_rel_scores_rr.append(avg_retrieval_rel_score_per_query)
print(
"Avg. Retrieval relevance score across chunks: {} for query: {}".format(
avg_retrieval_rel_score_per_query, user_query
)
)
qual_scores_rr.append(compute_quality_score(aimon_response))
responses_adb_rr[user_query] = llm_res
print("Time elapsed: {} seconds".format(time.time() - ast_rr))
Avg. Retrieval relevance score across chunks: 36.436465411440366 for query: What was the key decision in the meeting?
Avg. Retrieval relevance score across chunks: 38.804003013309085 for query: What are the next steps for the team?
Avg. Retrieval relevance score across chunks: 45.29209086832342 for query: Summarize the meeting in 10 words.
Avg. Retrieval relevance score across chunks: 36.979413900164815 for query: What were the main points of discussion?
Avg. Retrieval relevance score across chunks: 41.149971422535714 for query: What decision was made regarding the project?
Avg. Retrieval relevance score across chunks: 36.57368907582921 for query: What were the outcomes of the meeting?
Avg. Retrieval relevance score across chunks: 42.34540670899989 for query: What was discussed in the meeting?
Avg. Retrieval relevance score across chunks: 33.857591391574715 for query: What examples were discussed for project inspiration?
Avg. Retrieval relevance score across chunks: 38.419397677952816 for query: What considerations were made for the project timeline?
Avg. Retrieval relevance score across chunks: 42.91262631898647 for query: Who is responsible for completing the tasks?
Avg. Retrieval relevance score across chunks: 41.417109763746396 for query: What were the decisions made in the meeting?
Avg. Retrieval relevance score across chunks: 43.34866213159572 for query: What did the team decide about the project timeline?
Time elapsed: 97.93312644958496 seconds
Notice the difference in average document relevance scores when using the reranker v/s when not using the reranker v/s using a naive, brute-force approach.
# This is the average quality score.
avg_quality_score_rr = statistics.mean(qual_scores_rr)
print(
"Average Quality score for AIMon Re-ranking approach: {}".format(
avg_quality_score_rr
)
)
Average Quality score for AIMon Re-ranking approach: 74.62174819211145
# This is the average retrieval relevance score.
avg_retrieval_rel_score_rr = statistics.mean(avg_retrieval_rel_scores_rr)
print(
"Average retrieval relevance score for AIMon Re-ranking approach: {}".format(
avg_retrieval_rel_score_rr
)
)
Average retrieval relevance score for AIMon Re-ranking approach: 39.794702307038214
🎉 Again, Quality Score improved!
Notice that the overall quality score across all queries improved after using AIMon’s reranker.
In sum, as shown in the figure below, we demonstrated the following:
- Computing a quality score using a weighted combination of 3 different quality metrics: hallucination score, instruction adherence score and retrieval relevance score.
- Established a quality baseline using a brute force string matching approach to match documents to a query and pass that to an LLM.
- Improved the baseline quality using a Vector DB (here, we used Milvus)
- Further improved the quality score using AIMon’s low-latency, domain adaptable re-ranker.
- We also showed how retrieval relevance improves significantly by adding in AIMon’s re-ranker.
We encourage you to experiment with the different components shown in this notebook to further increase the quality score. One idea is to add your own definitions of quality using the instructions field in the instruction_adherence detector above. Another idea is to add another one of AIMon’s checker models as part of the quality metric calculation.
import pandas as pd
df_scores = pd.DataFrame(
{
"Approach": ["Brute-Force", "VectorDB", "AIMon-Rerank"],
"Quality Score": [
avg_quality_score_bf,
avg_quality_score_vdb,
avg_quality_score_rr,
],
"Retrieval Relevance Score": [
avg_retrieval_rel_score_bf,
avg_retrieval_rel_score_vdb,
avg_retrieval_rel_score_rr,
],
}
)
# % increase of quality scores relative to Brute-Force
df_scores["Increase in Quality Score (%)"] = (
(df_scores["Quality Score"] - avg_quality_score_bf) / avg_quality_score_bf
) * 100
df_scores.loc[0, "Increase in Quality Score (%)"] = 0
# % increase of retrieval relative scores relative to Brute-Force
df_scores["Increase in Retrieval Relevance Score (%)"] = (
(df_scores["Retrieval Relevance Score"] - avg_retrieval_rel_score_bf)
/ avg_retrieval_rel_score_bf
) * 100
df_scores.loc[0, "Increase in Retrieval Relevance Score (%)"] = 0
df_scores
| Approach | Quality Score | Retrieval Relevance Score | Increase in Quality Score (%) | Increase in Retrieval Relevance Score (%) | |
|---|---|---|---|---|---|
| 0 | Brute-Force | 51.750446 | 14.317723 | 0.000000 | 0.000000 |
| 1 | VectorDB | 67.180039 | 19.296728 | 29.815382 | 34.775115 |
| 2 | AIMon-Rerank | 74.621748 | 39.794702 | 44.195372 | 177.940153 |
The above table summarizes our results. Your actual numbers will vary depending on various factors such as variations in quality of LLM responses, performance of the nearest neighbor search in the VectorDB etc.
In conclusion, as shown by the figure below, we evaluated quality score, RAG relevance and instruction following capabilities of your LLM application. We used AIMon’s re-ranker to improve the overall quality of the application and the average relevance of documents retrieved from your RAG.