vLLM Semantic Router + Milvus: How Semantic Routing and Caching Build Scalable AI Systems the Smart Way
Most AI apps rely on a single model for every request. But that approach quickly runs into limits. Large models are powerful yet expensive, even when they’re used for simple queries. Smaller models are cheaper and faster but can’t handle complex reasoning. When traffic surges—say your AI app suddenly goes viral with ten million users overnight—the inefficiency of this one-model-for-all setup becomes painfully apparent. Latency spikes, GPU bills explode, and the model that ran fine yesterday starts gasping for air.
And my friend, you, the engineer behind this app, have to fix it—fast.
Imagine deploying multiple models of varying sizes and having your system automatically select the best one for each request. Simple prompts go to smaller models; complex queries route to larger ones. That’s the idea behind the vLLM Semantic Router—a routing mechanism that directs requests based on meaning, not endpoints. It analyzes the semantic content, complexity, and intent of each input to select the most suitable language model, ensuring every query is handled by the model best equipped for it.
To make this even more efficient, the Semantic Router pairs with Milvus, an open-source vector database that serves as a semantic cache layer. Before recomputing a response, it checks whether a semantically similar query has already been processed and instantly retrieves the cached result if found. The result: faster responses, lower costs, and a retrieval system that scales intelligently rather than wastefully.
In this post, we’ll dive deeper into how the vLLM Semantic Router works, how Milvus powers its caching layer, and how this architecture can be applied in real-world AI applications.
What is a Semantic Router?
At its core, a Semantic Router is a system that decides which model should handle a given request based on its meaning, complexity, and intent. Instead of routing everything to one model, it distributes requests intelligently across multiple models to balance accuracy, latency, and cost.
Architecturally, it’s built on three key layers: Semantic Routing, Mixture of Models (MoM), and a Cache Layer.
Semantic Routing Layer
The semantic routing layer is the brain of the system. It analyzes each input—what it’s asking, how complex it is, and what kind of reasoning it requires—to select the model best suited for the job. For example, a simple fact lookup might go to a lightweight model, while a multi-step reasoning query is routed to a larger one. This dynamic routing keeps the system responsive even as traffic and query diversity increase.
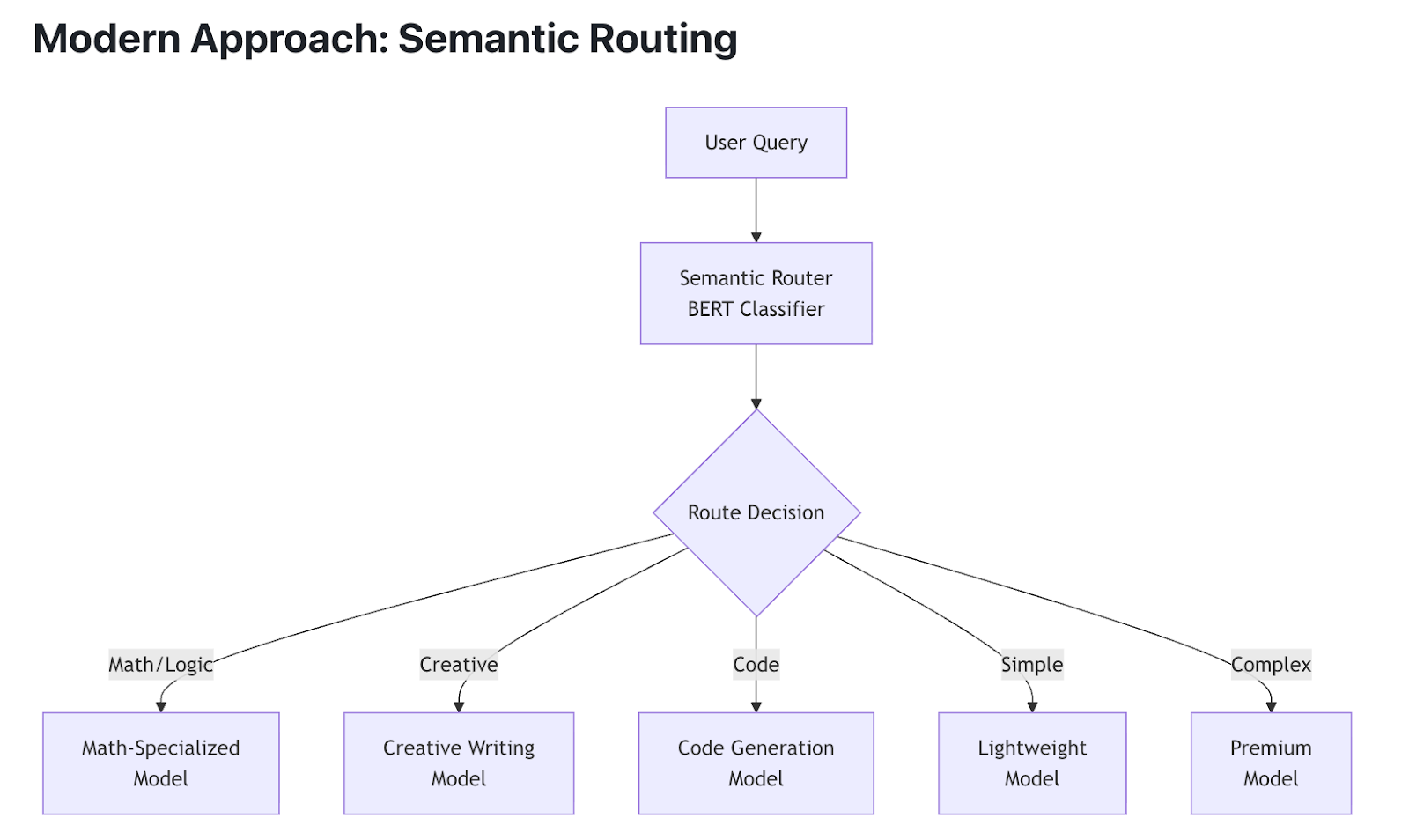
The Mixture of Models (MoM) Layer
The second layer, the Mixture of Models (MoM), integrates multiple models of different sizes and capabilities into one unified system. It’s inspired by the Mixture of Experts (MoE) architecture, but instead of picking “experts” inside a single large model, it operates across multiple independent models. This design reduces latency, lowers costs, and avoids being locked into any single model provider.
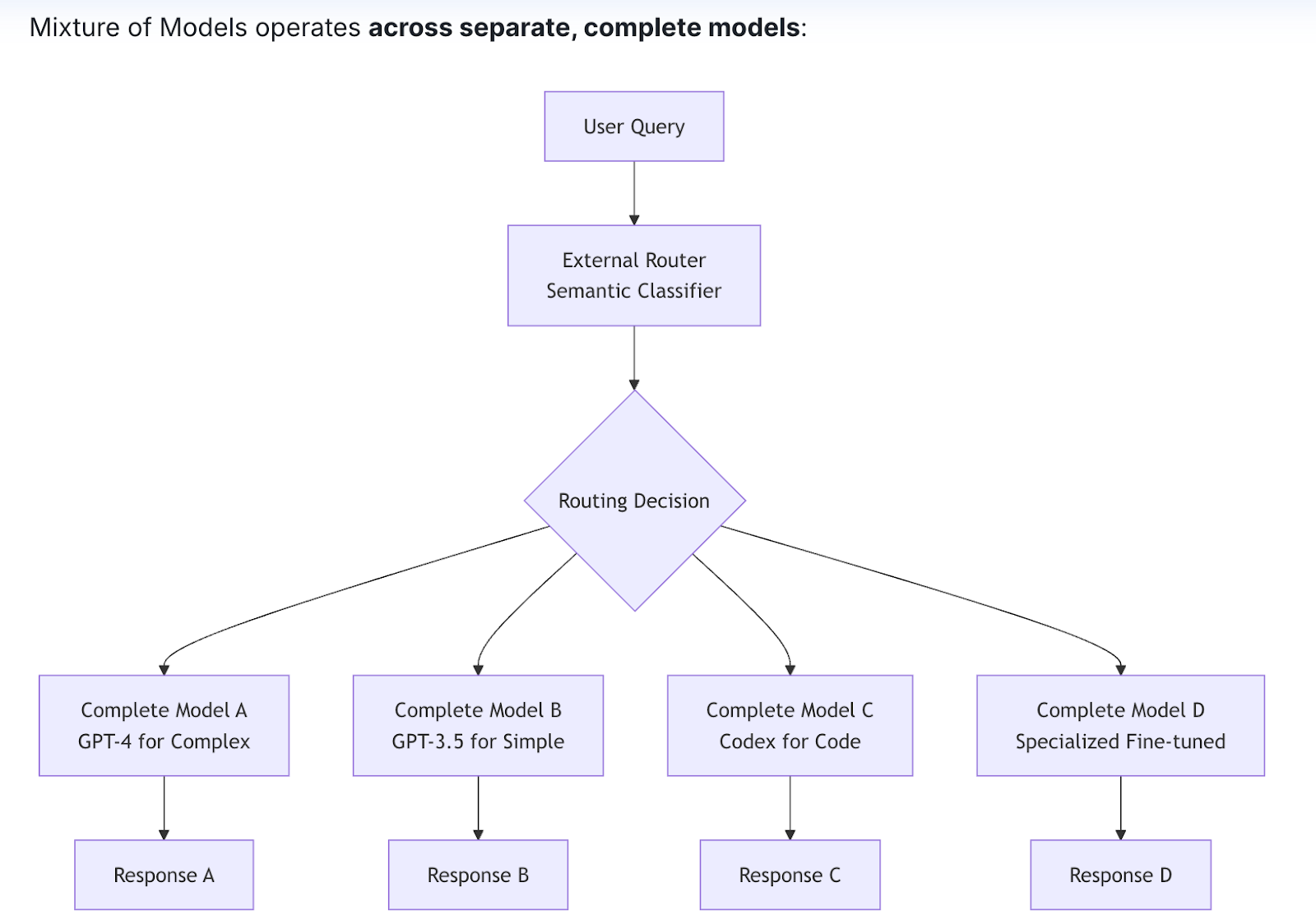
The Cache Layer: Where Milvus Makes the Difference
Finally, the cache layer—powered by Milvus Vector Database—acts as the system’s memory. Before running a new query, it checks whether a semantically similar request has been processed before. If so, it retrieves the cached result instantly, saving compute time and improving throughput.
Traditional caching systems rely on in-memory key-value stores, matching requests by exact strings or templates. That works fine when queries are repetitive and predictable. But real users rarely type the same thing twice. Once the phrasing changes—even slightly—the cache fails to recognize it as the same intent. Over time, the cache hit rate drops, and performance gains vanish as language naturally drifts.
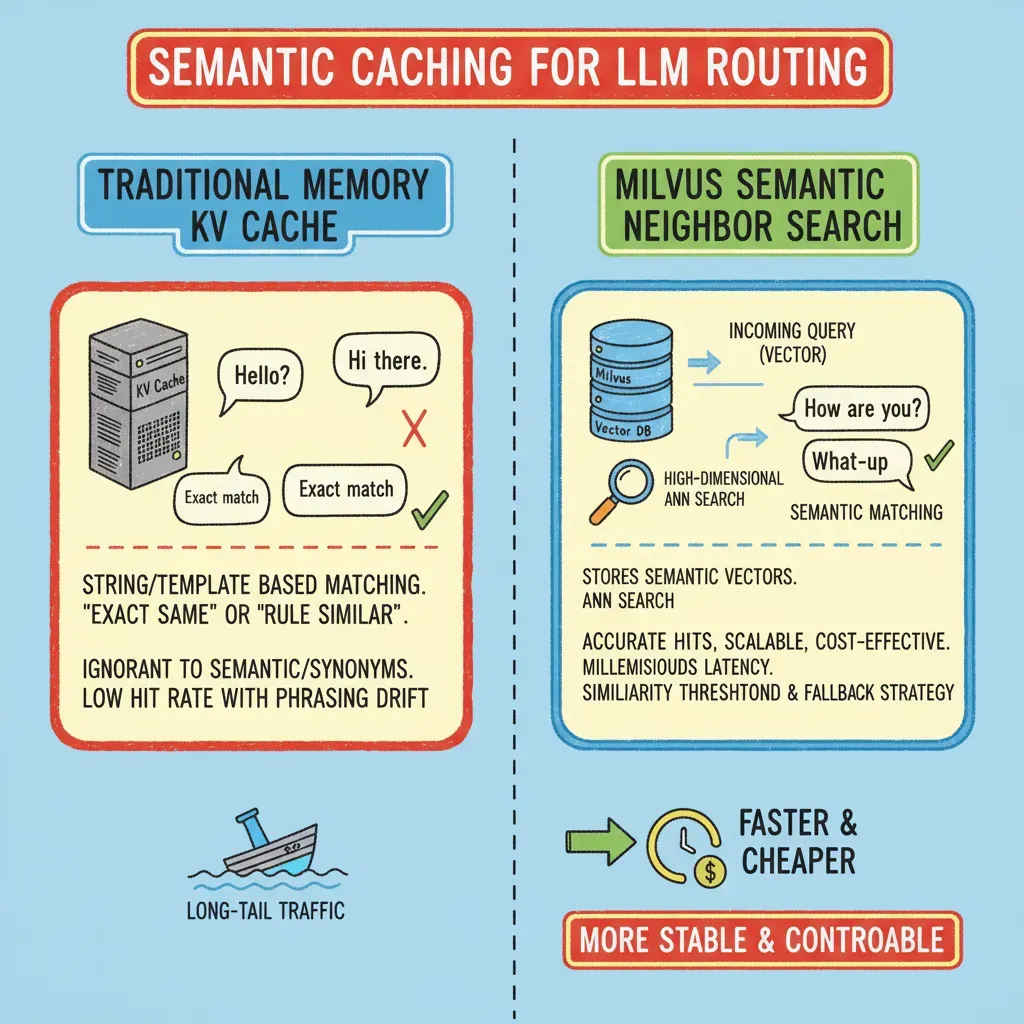
To fix this, we need caching that understands meaning, not just matching words. That’s where semantic retrieval comes in. Instead of comparing strings, it compares embeddings—high-dimensional vector representations that capture semantic similarity. The challenge, though, is scale. Running a brute-force search across millions or billions of vectors on a single machine (with time complexity O(N·d)) is computationally prohibitive. Memory costs explode, horizontal scalability collapses, and the system struggles to handle sudden traffic spikes or long-tail queries.
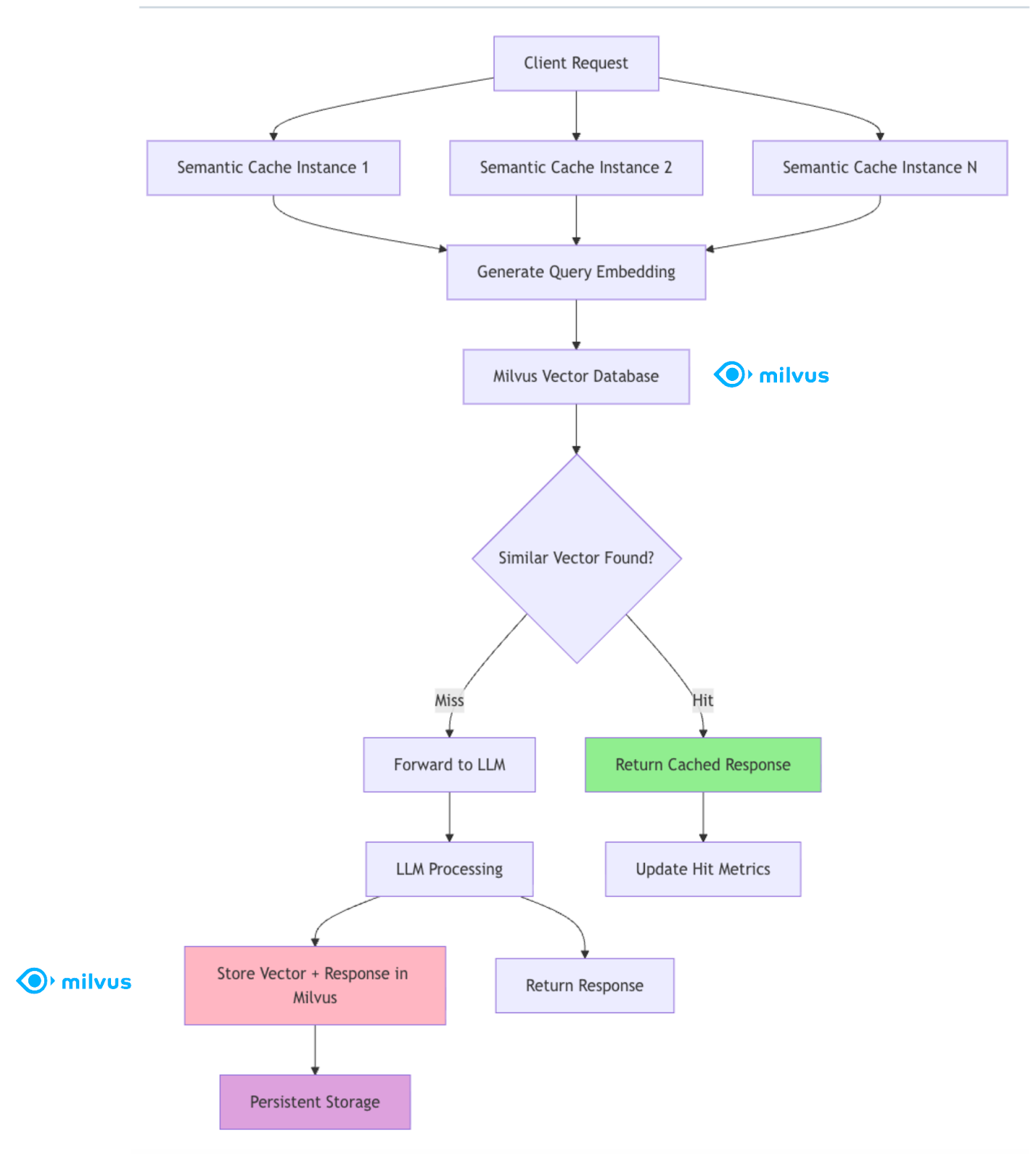
As a distributed vector database purpose-built for large-scale semantic search, Milvus brings the horizontal scalability and fault tolerance this cache layer needs. It stores embeddings efficiently across nodes and performs Approximate Nearest Neighbor (ANN) searches with minimal latency, even at massive scale. With the right similarity thresholds and fallback strategies, Milvus ensures stable, predictable performance—turning the cache layer into a resilient semantic memory for your entire routing system.
How Developers Are Using Semantic Router + Milvus in Production
The combination of vLLM Semantic Router and Milvus shines in real-world production environments where speed, cost, and reusability all matter.
Three common scenarios stand out:
1. Customer Service Q&A
Customer-facing bots handle massive volumes of repetitive queries every day—password resets, account updates, delivery statuses. This domain is both cost- and latency-sensitive, making it ideal for semantic routing. The router sends routine questions to smaller, faster models and escalates complex or ambiguous ones to larger models for deeper reasoning. Meanwhile, Milvus caches previous Q&A pairs, so when similar queries appear, the system can instantly reuse past answers instead of regenerating them.
2. Code Assistance
In developer tools or IDE assistants, many queries overlap—syntax help, API lookups, small debugging hints. By analyzing the semantic structure of each prompt, the router dynamically selects an appropriate model size: lightweight for simple tasks, more capable for multi-step reasoning. Milvus boosts responsiveness further by caching similar coding problems and their solutions, turning prior user interactions into a reusable knowledge base.
3. Enterprise Knowledge Base
Enterprise queries tend to repeat over time—policy lookups, compliance references, product FAQs. With Milvus as the semantic cache layer, frequently asked questions and their answers can be stored and retrieved efficiently. This minimizes redundant computation while keeping responses consistent across departments and regions.
Under the hood, the Semantic Router + Milvus pipeline is implemented in Go and Rust for high performance and low latency. Integrated at the gateway layer, it continuously monitors key metrics—like hit rates, routing latency, and model performance—to fine-tune routing strategies in real time.
How to Quickly Test the Semantic Caching in the Semantic Router
Before deploying semantic caching at scale, it’s useful to validate how it behaves in a controlled setup. In this section, we’ll walk through a quick local test that shows how the Semantic Router uses Milvus as its semantic cache. You’ll see how similar queries hit the cache instantly while new or distinct ones trigger model generation—proving the caching logic in action.
Prerequisites
- Container Environment: Docker + Docker Compose
- Vector Database: Milvus Service
- LLM + Embedding: Project downloaded locally
1.Deploy the Milvus Vector Database
Download the deployment files
wget https://github.com/Milvus-io/Milvus/releases/download/v2.5.12/Milvus-standalone-docker-compose.yml -O docker-compose.yml
Start the Milvus service.
docker-compose up -d
docker-compose ps -a

2. Clone the project
git clone https://github.com/vllm-project/semantic-router.git
3. Download local models
cd semantic-router
make download-models

4. Configuration Modifications
Note: Modify the semantic_cache type to milvus
vim config.yaml
semantic_cache:
enabled: true
backend_type: "milvus" # Options: "memory" or "milvus"
backend_config_path: "config/cache/milvus.yaml"
similarity_threshold: 0.8
max_entries: 1000 # Only applies to memory backend
ttl_seconds: 3600
eviction_policy: "fifo"
Modify the Mmilvus configuration Note: Fill in the Milvusmilvus service just deployed
vim milvus.yaml
# Milvus connection settings
connection:
# Milvus server host (change for production deployment)
host: "192.168.7.xxx" # For production: use your Milvus cluster endpoint
# Milvus server port
port: 19530 # Standard Milvus port
# Database name (optional, defaults to "default")
database: "default"
# Connection timeout in seconds
timeout: 30
# Authentication (enable for production)
auth:
enabled: false # Set to true for production
username: "" # Your Milvus username
password: "" # Your Milvus password
# TLS/SSL configuration (recommended for production)
tls:
enabled: false # Set to true for secure connections
cert_file: "" # Path to client certificate
key_file: "" # Path to client private key
ca_file: "" # Path to CA certificate
# Collection settings
collection:
# Name of the collection to store cache entries
name: "semantic_cache"
# Description of the collection
description: "Semantic cache for LLM request-response pairs"
# Vector field configuration
vector_field:
# Name of the vector field
name: "embedding"
# Dimension of the embeddings (auto-detected from model at runtime)
dimension: 384 # This value is ignored - dimension is auto-detected from the embedding model
# Metric type for similarity calculation
metric_type: "IP" # Inner Product (cosine similarity for normalized vectors)
# Index configuration for the vector field
index:
# Index type (HNSW is recommended for most use cases)
type: "HNSW"
# Index parameters
params:
M: 16 # Number of bi-directional links for each node
efConstruction: 64 # Search scope during index construction
5. Start the project
Note: It is recommended to modify some Dockerfile dependencies to domestic sources
docker compose --profile testing up --build
6. Test Requests
Note: Two requests in total (no cache and cache hit) First request:
echo "=== 第一次请求(无缓存状态) ===" && \
time curl -X POST http://localhost:8801/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer test-token" \
-d '{
"model": "auto",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What are the main renewable energy sources?"}
],
"temperature": 0.7
}' | jq .
Output:
real 0m16.546s
user 0m0.116s
sys 0m0.033s
Second request:
echo "=== 第二次请求(缓存状态) ===" && \
time curl -X POST http://localhost:8801/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer test-token" \
-d '{
"model": "auto",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What are the main renewable energy sources?"}
],
"temperature": 0.7
}' | jq .
Output:
real 0m2.393s
user 0m0.116s
sys 0m0.021s
This test demonstrates Semantic Router’s semantic caching in action. By leveraging Milvus as the vector database, it efficiently matches semantically similar queries, improving response times when users ask the same or similar questions.
Conclusion
As AI workloads grow and cost optimization becomes essential, the combination of vLLM Semantic Router and Milvus provides a practical way to scale intelligently. By routing each query to the right model and caching semantically similar results with a distributed vector database, this setup cuts compute overhead while keeping responses fast and consistent across use cases.
In short, you get smarter scaling—less brute force, more brains.
If you’d like to explore this further, join the conversation in our Milvus Discord or open an issue on GitHub. You can also book a 20-minute Milvus Office Hours session for one-on-one guidance, insights, and technical deep dives from the team behind Milvus.
- What is a Semantic Router?
- Semantic Routing Layer
- The Mixture of Models (MoM) Layer
- The Cache Layer: Where Milvus Makes the Difference
- How Developers Are Using Semantic Router + Milvus in Production
- 1. Customer Service Q\&A
- 2. Code Assistance
- 3. Enterprise Knowledge Base
- How to Quickly Test the Semantic Caching in the Semantic Router
- Prerequisites
- 1.Deploy the Milvus Vector Database
- 2. Clone the project
- 3. Download local models
- 4. Configuration Modifications
- 5. Start the project
- 6. Test Requests
- Conclusion
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



