Milvus 2.0 Redefining Vector Database
It was only like yesterday when we put down the first line of code for Milvus in October 2018. In March 2021, after 19 iterations tested by 1,000+ users around the world, we launched Milvus 1.0, our first offical release with long-term support. As the world's most popular open-source vector database, Milvus 1.0 managed to solve some fundamental issues in vector management, such as CRUD operations and data persistence. However, as new scenarios and requirements emerge, we began to realize that there are so many more issues yet to resolve. This article offers a recap on the observations we made in the past three years, the challenges that Milvus 2.0 is expected to address, and why Milvus 2.0 is deemed a better solution to such challenges. To learn more about what Milvus 2.0 has to offer, check out the Milvus 2.0 Release Notes.
Challenges Milvus 1.x is faced with
Data silo: Milvus 1.0 is only capable of handling vector embeddings generated from unstructured data, and gives little support for scalar query. The disaggregation of data storage in its design results in duplicate data and adds to the complexity of application development, and hybrid search between vector and scalar data is unsatisfactory due to the lack of a unified optimizer.
Dilemma between timeliness and efficiency: Milvus 1.0 is a near real-time system, which relies on regular or force flush to ensure data visibility. This approach adds to the complexity and uncertainty in stream data processing at a number of levels. Besides, although this batch insertion approach is said to improve processing efficiency, it still consumes plenty of resources. So bulkload approach is needed.
Lacking scalability & elasticity: Milvus 1.0 relies on Mishards, a sharding middleware solution, to achieve scability, and network-attached storage (NAS) for data persistence. This classical architecture built upon shared storage does not contribute much to the overall scalability for the following reasons:
- Only one write node is supported in Mishards and cannot be scaled.
- The scaling of the read nodes in Mishards is implemented using consistent hash-based routing. Although consistent hashing is easy to implement and helps solve the issue of data distribution uniformity, it is not flexible enough in data scheduling and falls short of addressing the mismatch between data size and computational power.
- Milvus 1.0 relies on MySQL to manage metadata, but the queries and dataset size that a standalone MySQL server is capable of handling is fairly limited.
Lacking high availability: One observation we've made is that most of Milvus' users tend to favor availability over consistency, whilst Milvus 1.x lacks capacities such as in-memory replicas and disaster recovery and is not quite up to par in terms of high availability. Therefore, we are exploring the possibility of sacrificing a certain degree of accuracy to achieve higher availability.
Prohibitively high costs: Milvus 1.0 relies on NAS for data persistence, the cost of which is usually tenfold that of a local or object storage. Since vector search relies heavily on computing resources and memory, the high costs it incurs could well become a hurdle to further exploration in large-scale datasets or complex business scenarios.
Unintuitive user experience:
- Complicated distributed deployment incurs high operational costs.
- A well-designed graphical user interface (GUI) is not available.
- Unintuitive APIs have become a drag on the development of applications.
Whether to move on from patch or to start from scratch is a big question. Charles Xie, the father of Milvus, believes that, just as many traditional automakers could never progressively turn Tesla, Milvus has to become a game changer in the field of unstructured data processing and analytics in order to thrive. It is this conviction that spurred us to kick start Milvus 2.0, a refactored cloud-native vector database.
The Making of Milvus 2.0
Design principles
As our next-generation cloud-native vector database, Milvus 2.0 is built around the following three principles:
Cloud-native first: We believe that only architectures supporting storage and computing separation can scale on demand and take the full advantage of cloud's elasticity. We'd also like to bring your attention to the microservice design of Milvus 2.0, which features read and write separation, incremental and historical data separation, and CPU-intensive, memory-intensive, and IO-intensive task separation. Microservices help optimize allocation of resources for the ever-changing heterogeneous workload.
Logs as data: In Milvus 2.0, the log broker serves as the system' backbone: All data insert and update operations must go through the log broker, and worker nodes execute CRUD operations by subscribing to and consuming logs. This design reduces system complexity by moving core functions such as data persistence and flashback down to the storage layer, and log pub-sub make the system even more flexible and better positioned for future scaling.
Unified batch and stream processing: Milvus 2.0 implements the unified Lambda architecture, which integrates the processing of the incremental and historical data. Compared with the Kappa architecture, Milvus 2.0 introduces log backfill, which stores log snapshots and indexes in the object storage to improve failure recovery efficiency and query performance. To break unbounded (stream) data down into bounded windows, Milvus embraces a new watermark mechanism, which slices the stream data into multiple message packs according to write time or event time, and maintains a timeline for users to query by time.
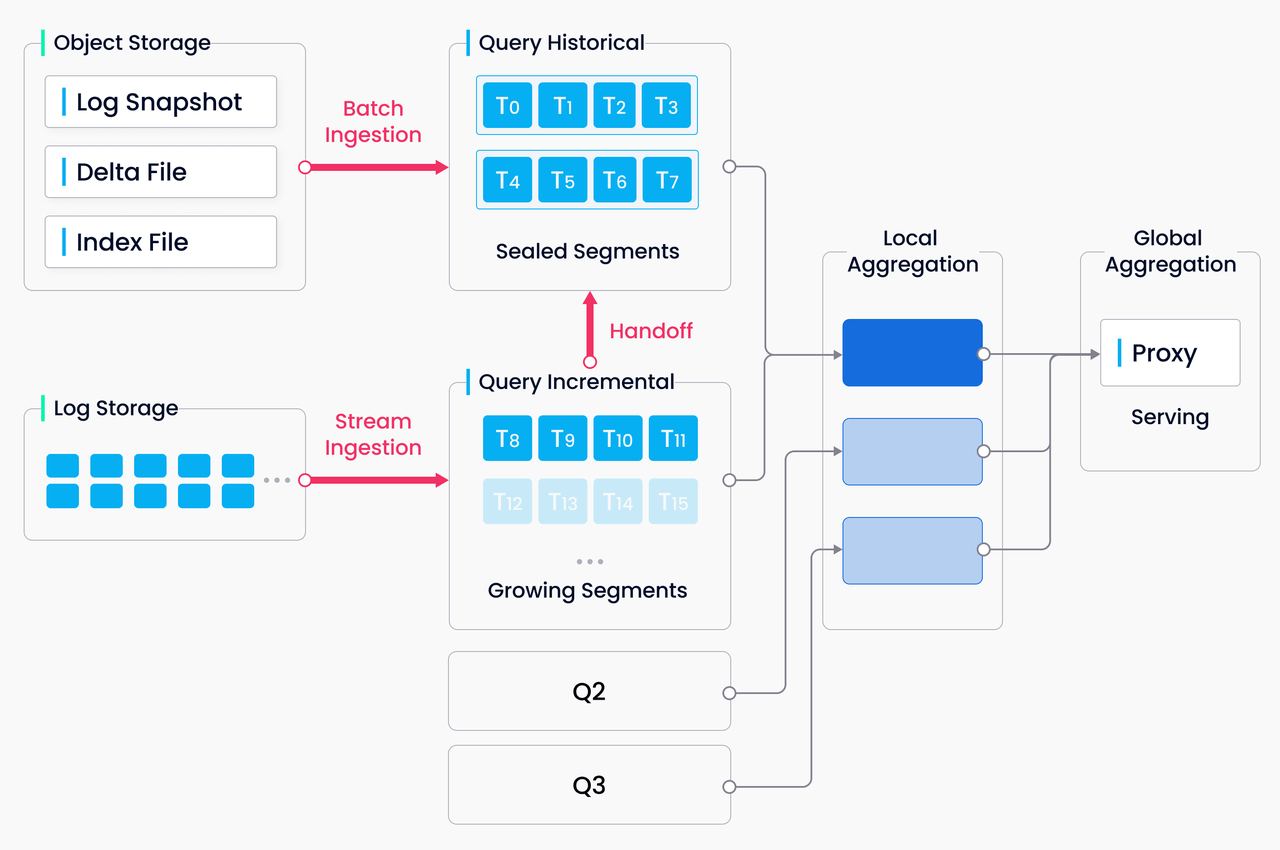 2.0 image 1.png
2.0 image 1.png
System architecture
As mentioned above, the design of Milvus 2.0 strictly follows the principles of storage and computing separation and control and data plane separation. The system breaks down into four layers: access layer, coordinator service, worker nodes, and storage.
Access layer: The interface: The access layer is the front layer of the system and endpoint to users. It is in charge of forwarding requests and gathering results.
Coordinator service: The coordinator service assigns tasks to the worker nodes and functions as the system's brain. There are four coordinator types: root coordinator (root coord), data coordinator (data coord), query coordinator (query coord), and index coordinator (index coord).
Worker nodes: The arms and legs. Worker nodes are dumb executors that follow the instructions from the coordinator service and respond to the read/write requests from the access layer. There are three types of worker nodes: data nodes, query nodes, and index nodes.
Storage: The bones. Storage has three types: meta storage, log broker, and object storage.
- Implemented by etcd, meta storage is used to store metadata such as collection and checkpoint for the coordinator service.
- Implemented by Pulsar, log broker is used mainly to store incremental logs and implement reliable asynchronous notifications.
- Implemented by MinIO or S3, object storage is used mainly to store log snapshots and index files.
The following is the system architecture diagram of Milvus 2.0:
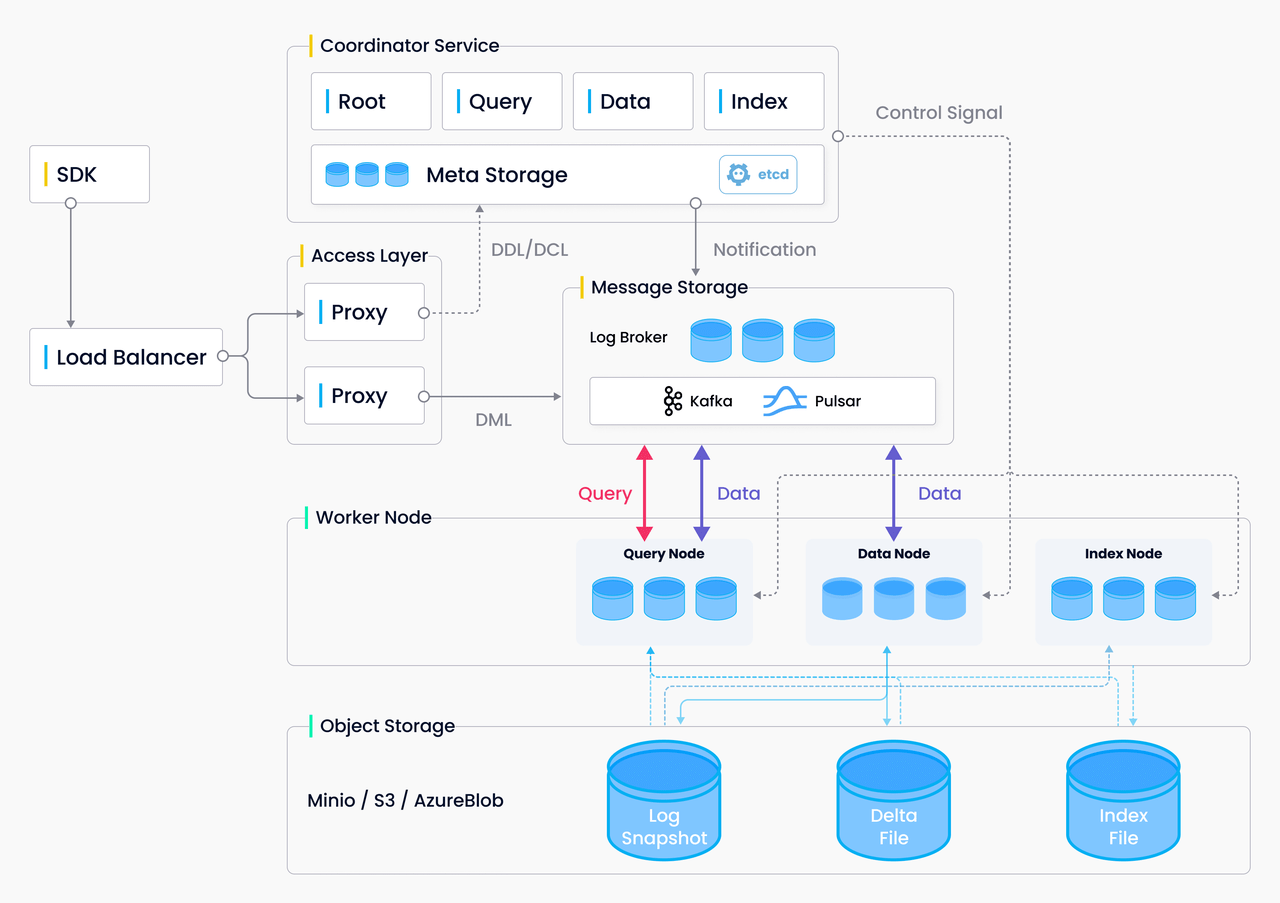 2.0 image 2.png
2.0 image 2.png
Key features
The costs of running a database involve not only runtime resource consumption, but also the potential learning costs and the operational and maintenance costs. Practically speaking, the more user-friendly a database is, the more likely it is going to save such potential costs. From Milvus' calendar day one, ease of use is always put on the top of our list, and the latest Milvus 2.0 has quite a few to offer in the way of reducing such costs.
Always online
Data reliability and service sustainability are the basic requirements for a database, and our strategy is "fail cheap, fail small, and fail often".
- "Fail cheap" refers to storage and computing separation, which makes the handling of node failure recovery straightforward and at a low cost.
- "Fail small" refers to the "divide and conquer" strategy, which simplifies the design complexity by having each coordinator service handle only a small portion of read/write/incremental/historical data.
- "Fail often" refers to the introduction of chaos testing, which uses fault injection in a testing environment to simulate situations such as hardware failures and dependency failures and accelerate bug discovery.
Hybrid search between scalar and vector data
To leverage synergy between structured and unstructured data, Milvus 2.0 supports both scalar and vector data and enables hybrid search between them. Hybrid search helps users find the approximate nearest neighbors that match a filter criteria. Currently, Milvus supports relational operations such as EQUAL, GREATER THAN, and LESS THAN, and logical operations such as NOT, AND, OR, and IN.
Tunable consistency
As a distributed database abiding by the PACELC theorem, Milvus 2.0 has to trade off between consistency and availability & latency. In most scenarios, overemphasizing data consistency in production can overkill because allowing a small portion of data to be invisible has little impact on the overall recall but can significantly improve the query performance. Still, we believe that consistency levels, such as strong, bounded staleness, and session, have their own unique application. Therefore, Milvus supports tunable consistency at the request level. Taking testing as an example, users may require strong consistence to ensure test results are absolutely correct.
Time travel
Data engineers often need to do data rollback to fix dirty data and code bugs. Traditional databases usually implement data rollback through snapshots or even data retrain. This could bring excessive overhead and maintenance costs. Milvus maintains a timeline for all data insert and delete operations, and users can specify a timestamp in a query to retrieve a data view at a specified point in time. With time travel, Milvus can also implement a lightweight data backup or data clone.
ORM Python SDK
Object relational mapping (ORM) allows users to focus more on the upper-level business model than on the underlying data model, making it easier for developers to manage relations between collections, fields, and programs. To close the gap between proof of concept (PoC) for AI algorithms and production deployment, we engineered PyMilvus ORM APIs, which can work with an embedded library, a standalone deployment, a distributed cluster , or even a cloud service. With a unified set of APIs, we provide users with a consistent user experience and reduce code migration or adaptation costs.
 2.0 image 3.png
2.0 image 3.png
Supporting tools
- Milvus Insight is Milvus's graphical user interface offering practical functionalities such as cluster state management, meta management, and data query. The source code of Milvus Insight will also be open sourced as an independent project. We are looking for more contributors to join this effort.
- Out-of-box experience (OOBE), faster deployment: Milvus 2.0 can be deployed using helm or docker-compose.
- Milvus 2.0 uses Prometheus, an open-source time-series database, to store performance and monitor data, and Grafana, an open observability platform, for metrics visualization.
Looking to the future
In retrospect, we believe the system architecture based on big data + AI application is overly complicated. The top priority of the Milvus community has always been to make Milvus easier to use. Moving forward, the Milvus project will focus on the following areas:
DB for AI: Besides the basic CRUD functions, Milvus, as a database system, needs to have a smarter query optimizer, more powerful data query capabilities, and more comprehensive data management functions. Our work for the next stage will be focusing on the data manipulation language (DML) functions and data types not yet available in Milvus 2.0, including adding delete and update operations and supporting string data types.
AI for DB: Knob tuning of parameters such as index types, system configurations, user workload, and hardware types complicates the use of Milvus and should be avoided as much as possible. We've set about analyzing system load and gathering access frequency of the data, and plan on introducing auto-tuning in the future to reduce learning costs.
Cost optimization: The biggest challenge for vector retrieval is the need to process massive-scale datasets within a limited period of time. This is both CPU-intensive and memory-intensive. Introducing GPU and FPGA heterogeneous hardware acceleration at the physical layer can greatly reduce CPU overhead. We are also developing a hybrid on-disk and in-memory ANN indexing algorithms to realize high-performance queries on massive datasets with limited memory. What's more, we are evaluating the performance of existing open-source vector indexing algorithms such as ScaNN and NGT.
Ease of use: Milvus keeps improving its usability by providing cluster management tools, SDKs in multiple languages, deployment tools, operational tools, and more.
To learn more about Milvus' release plans, check out the Milvus Roadmap.
Kudos to all Milvus community contributors, without whom Milvus 2.0 would not have been possible. Feel free to submit an issue or contribute your code to the Milvus community!
About the author
Xiaofan Luan is now working at Zilliz as Director of Engineering managing R&D of the Milvus project. He has 7 years' work experience focusing on building database/storage systems. After graduating from Cornell University, he worked at Oracle, HEDVIG, and Alibaba Cloud consecutively.
Like the article? Spread the word

