Milvus Metadata Management (2)
In the last blog, we mentioned how to view your metadata using MySQL or SQLite. This article mainly intends to introduce in detail the fields in the metadata tables.
Fields in the Tables table
Take SQLite as an example. The following result comes from 0.5.0. Some fields are added to 0.6.0, which will be introduced later. There is a row in Tables specifying a 512-dimensional vector table with the name <codetable_1. When the table is created, index_file_size is 1024 MB, engine_type is 1 (FLAT), nlist is 16384, metric_type is 1 (Euclidean distance L2). id is the unique identifier of the table. state is the state of the table with 0 indicating a normal state. created_on is the creation time. flag is the flag reserved for internal use.
 1-image-1.png
1-image-1.png
The following table shows field types and descriptions of the fields in Tables.
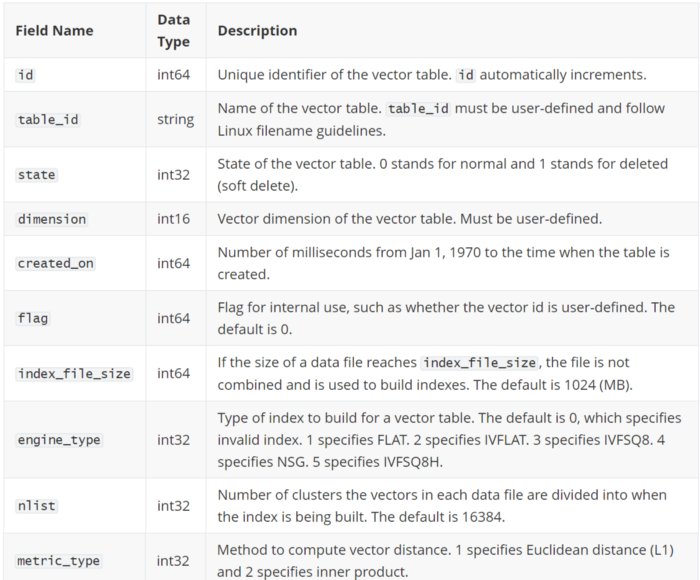 2-field-types-descriptions-milvus-metadata.png
2-field-types-descriptions-milvus-metadata.png
Table partitioning is enabled in 0.6.0 with a few new fields, including owner_table,partition_tag and version. A vector table, table_1, has a partition called table_1_p1, which is also a vector table. partition_name corresponds to table_id. Fields in a partition table are inherited from the owner table, with the owner table field specifying the name of the owner table and the partition_tag field specifying the tag of the partition.
 3-image-2.png
3-image-2.png
The following table shows new fields in 0.6.0:
 4-new-fields-milvus-0.6.0.png
4-new-fields-milvus-0.6.0.png
Fields in the TableFiles table
The following example contains two files, which both belong to the table_1 vector table. The index type (engine_type) of the first file is 1 (FLAT); file status (file_type) is 7 (backup of the original file); file_size is 411200113 bytes; number of vector rows is 200,000. The index type of the second file is 2 (IVFLAT); file status is 3 (index file). The second file is actually the index of the first file. We will introduce more information in upcoming articles.
 5-image-3.png
5-image-3.png
The following table shows fields and descriptions of TableFiles:
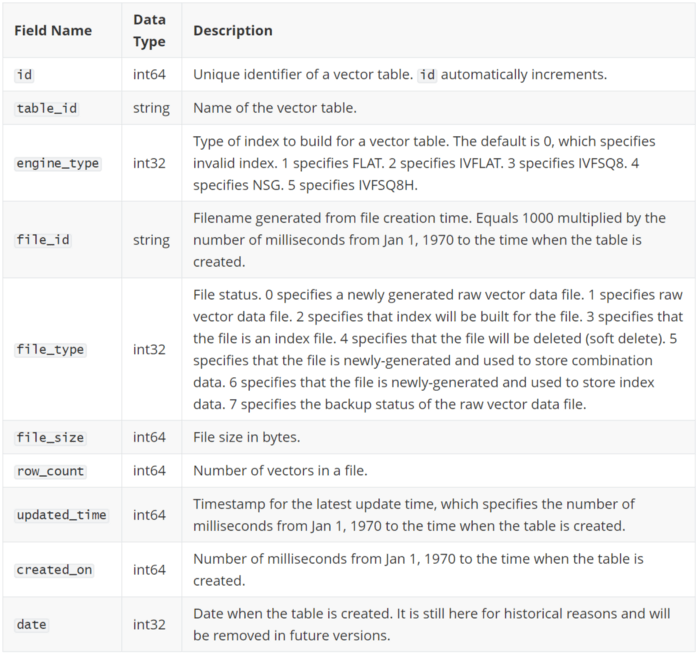 6-field-types-descriptions-tablefile.png
6-field-types-descriptions-tablefile.png
What’s coming next
The upcoming article will show you how to use SQLite to manage metadata in Milvus. Stay tuned!
Any questions, welcome to join our Slack channelor file an issue in the repo.
GitHub repo: https://github.com/milvus-io/milvus
Like the article? Spread the word

