Building Personalized Recommender Systems with Milvus and PaddlePaddle
Background Introduction
With the continuous development of network technology and the ever-expanding scale of e-commerce, the number and variety of goods grow rapidly and users need to spend a lot of time to find the goods they want to buy. This is information overload. In order to solve this problem, recommendation system came into being.
The recommendation system is a subset of the Information Filtering System, which can be used in a range of areas such as movies, music, e-commerce, and Feed stream recommendations. The recommendation system discovers the user’s personalized needs and interests by analyzing and mining user behaviors, and recommends information or products that may be of interest to the user. Unlike search engines, recommendation system do not require users to accurately describe their needs, but model their historical behavior to proactively provide information that meets user interests and needs.
In this article we use PaddlePaddle, a deep learning platform from Baidu, to build a model and combine Milvus, a vector similarity search engine, to build a personalized recommendation system that can quickly and accurately provide users with interesting information.
Data Preparation
We take MovieLens Million Dataset (ml-1m) [1] as an example. The ml-1m dataset contains 1,000,000 reviews of 4,000 movies by 6,000 users, collected by the GroupLens Research lab. The original data includes feature data of the movie, user feature, and user rating of the movie, you can refer to ml-1m-README [2] .
ml-1m dataset includes 3 .dat articles: movies.dat、users.dat and ratings.dat.movies.dat includes movie’s features, see example below:
MovieID::Title::Genres
1::ToyStory(1995)::Animation|Children's|Comedy
This means that the movie id is 1, and the title is 《Toy Story》, which is divided into three categories. These three categories are animation, children, and comedy.
users.dat includes user’s features, see example below:
UserID::Gender::Age::Occupation::Zip-code
1::F::1::10::48067
This means that the user ID is 1, female, and younger than 18 years old. The occupation ID is 10.
ratings.dat includes the feature of movie rating, see example below:
UserID::MovieID::Rating::Timestamp 1::1193::5::978300760
That is, the user 1 evaluates the movie 1193 as 5 points.
Fusion Recommendation Model
In the film personalized recommendation system we used the Fusion Recommendation Model [3] which PaddlePaddle has implemented. This model is created from its industrial practice.
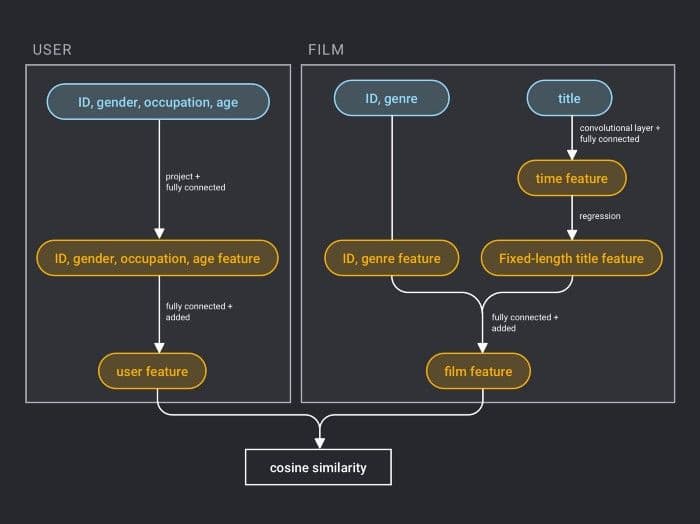
First, take user features and movie features as input to the neural network, where:
- The user features incorporate four attribute information: user ID, gender, occupation, and age.
- The movie feature incorporate three attribute information: movie ID, movie type ID, and movie name.
For the user feature, map the user ID to a vector representation with a dimension size of 256, enter the fully connected layer, and do similar processing for the other three attributes. Then the feature representations of the four attributes are fully connected and added separately.
For movie features, the movie ID is processed in a manner similar to the user ID. The movie type ID is directly input into the fully connected layer in the form of a vector, and the movie name is represented by a fixed-length vector using a text convolutional neural network. The feature representations of the three attributes are then fully connected and added separately.
After obtaining the vector representation of the user and the movie, calculate the cosine similarity of them as the score of the personalized recommendation system. Finally, the square of the difference between the similarity score and the user’s true score is used as the loss function of the regression model.
 1-user-film-personalized-recommender-Milvus.jpg
1-user-film-personalized-recommender-Milvus.jpg
System Overview
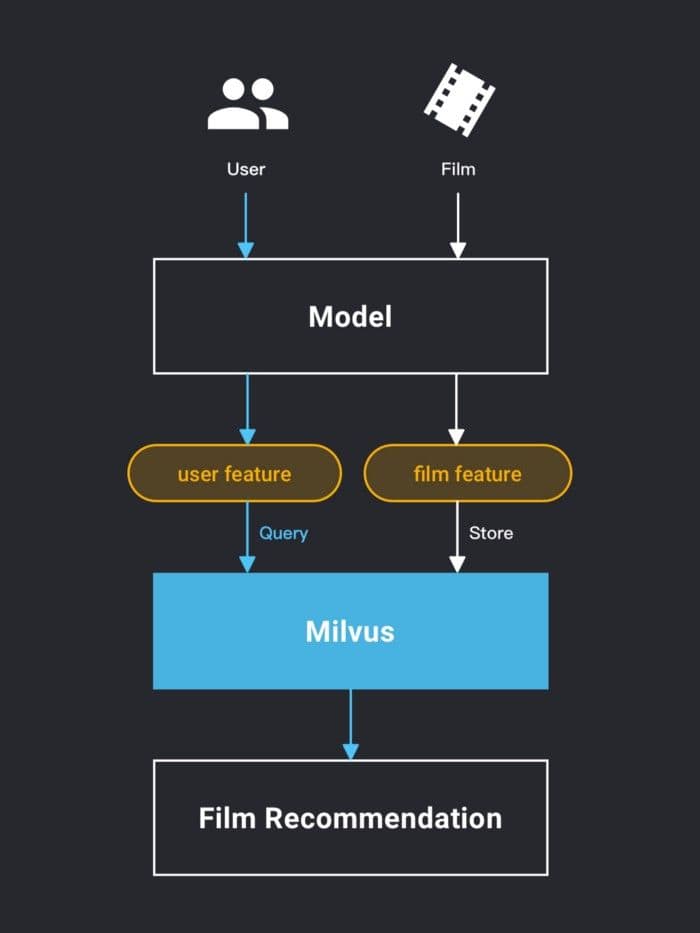
Combined with PaddlePaddle’s fusion recommendation model, the movie feature vector generated by the model is stored in the Milvus vector similarity search engine, and the user feature is used as the target vector to be searched. Similarity search is performed in Milvus to obtain the query result as the recommended movies for the user.
 2-system-overview.jpg
2-system-overview.jpg
The inner product (IP) method is provided in Milvus to calculate the vector distance. After normalizing the data, the inner product similarity is consistent with the cosine similarity result in the fusion recommendation model.
Application of Personal Recommender System
There are three steps in building a personalized recommendation system with Milvus, details on how to operate please refer to Mivus Bootcamp [4].
Step 1:Model Training
# run train.py
$ python train.py
Running this command will generate a model recommender_system.inference.model in the directory, which can convert movie data and user data into feature vectors, and generate application data for Milvus to store and retrieve.
Step 2:Data Preprocessing
# Data preprocessing, -f followed by the parameter raw movie data file name
$ python get_movies_data.py -f movies_origin.txt
Running this command will generate test data movies_data.txt in the directory to achieve pre-processing of movie data.
Step 3:Implementing Personal Recommender System with Milvus
# Implementing personal recommender system based on user conditions
$ python infer_milvus.py -a <age>-g <gender>-j <job>[-i]
Running this command will implement personalized recommendations for specified users.
The main process is:
- Through the load_inference_model, the movie data is processed by the model to generate a movie feature vector.
- Load the movie feature vector into Milvus via milvus.insert.
- According to the user’s age / gender / occupation specified by the parameters, it is converted into a user feature vector, milvus.search_vectors is used for similarity retrieval, and the result with the highest similarity between the user and the movie is returned.
Prediction of the top five movies that the user is interested in:
TopIdsTitleScore
03030Yojimbo2.9444923996925354
13871Shane2.8583481907844543
23467Hud2.849525213241577
31809Hana-bi2.826111316680908
43184Montana2.8119677305221558
Summary
By inputing user information and movie information to the fusion recommendation model we can get matching scores, and then sort the scores of all movies based on the user to recommend movies that may be of interest to the user. This article combines Milvus and PaddlePaddle to build a personalized recommendation system. Milvus, a vector search engine, is used to store all movie feature data, and then similarity retrieval is performed on user features in Milvus. The search result is the movie ranking recommended by the system to the user.
Milvus [5] vector similarity search engine is compatible with various deep learning platforms, searching billions of vectors with only millisecond response. You can explore more possibilities of AI applications with Milvus with ease!
Reference
- MovieLens Million Dataset (ml-1m): http://files.grouplens.org/datasets/movielens/ml-1m.zip
- ml-1m-README: http://files.grouplens.org/datasets/movielens/ml-1m-README.txt
- Fusion Recommendation Model by PaddlePaddle: https://www.paddlepaddle.org.cn/documentation/docs/zh/beginners_guide/basics/recommender_system/index.html#id7
- Bootcamp: https://github.com/milvus-io/bootcamp/tree/master/solutions/recommendation_system
- Milvus: https://milvus.io/
Like the article? Spread the word


