什么是 Milvus?
在不到 10 分钟内了解您需要知道的关于 Milvus 的一切。
什么是向量嵌入?
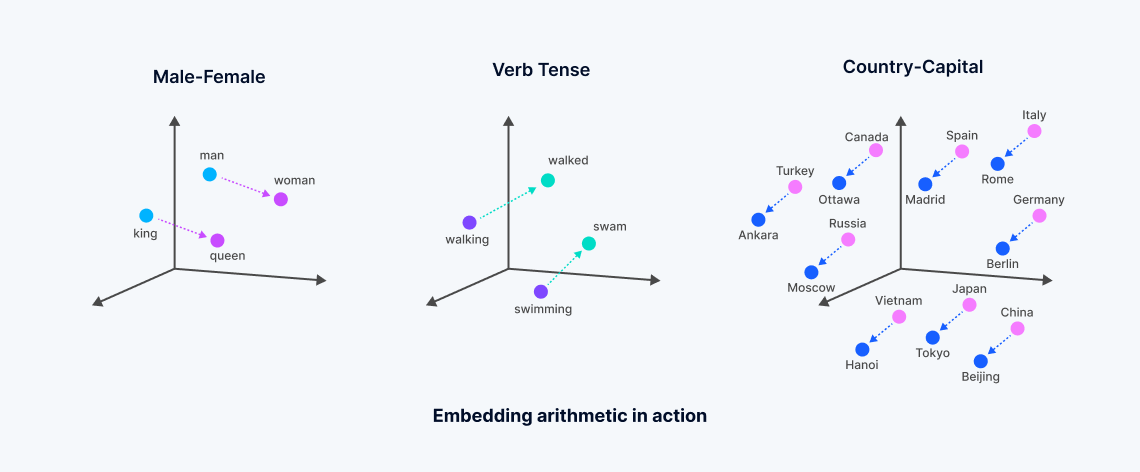
向量嵌入是从机器学习模型中提取的数值表示,捕捉非结构化数据的语义含义。这些嵌入通过神经网络或变压器架构对数据中的复杂相关性进行分析,创建一个密集的向量空间,其中每个点对应于数据对象(如文档中的词)的“含义”。
这个过程将文本或其他非结构化数据转换为反映语义相似性的向量——在这个多维空间中,意义相关的词被放置得更近,从而实现一种称为“密集向量搜索”的搜索方式。这与依赖精确匹配和使用稀疏向量的传统关键词搜索形成对比。向量嵌入的发展,通常源于大型科技公司广泛训练的基础模型,使得搜索能够捕捉数据的本质,超越词汇或稀疏向量搜索方法的局限性。
我可以用向量嵌入做什么?
向量嵌入可以在各种应用中使用,以多种方式提高效率和准确性。以下是一些最常见的用例:
查找相似的图像、视频或音频文件
向量嵌入使得可以通过内容而不仅仅是关键词来搜索相似的多媒体内容,使用卷积神经网络(CNN)分析图像、视频帧或音频片段。这使得可以通过比较存储在向量数据库中的嵌入表示来进行高级搜索,例如通过声音线索找到图像或通过图像查询找到视频。
加速药物发现
在制药行业,向量嵌入可以编码化合物的化学结构,通过测量其与目标蛋白质的相似性来识别有前景的药物候选物。这加速了药物发现过程,通过专注于最有可能的线索来节省时间和资源。
提升搜索相关性的语义搜索
通过将内部文档嵌入到向量中,组织可以利用语义搜索来提高搜索结果的相关性。这种方法使用检索增强生成(RAG)的概念来理解查询背后的意图,通过类似 ChatGPT 的 AI 模型从公司的数据中提供答案,从而减少无关结果和 AI 幻觉。
推荐系统
向量嵌入通过将用户和项目表示为嵌入来测量相似性,从而改变了推荐系统。这种方法使得可以根据个人偏好提供个性化推荐,增强用户满意度和在线平台的参与度。
异常检测
在欺诈检测、网络安全和工业监控等领域,向量嵌入在识别异常模式方面起着重要作用。通过将数据点表示为嵌入,可以通过计算距离或不相似性来检测异常,从而实现对潜在问题的早期识别和预防措施。
什么是矢量数据库?
向量数据库是专门设计用于通过向量嵌入和数值表示来管理和检索非结构化数据的系统,这些表示捕捉了图像、音频、视频和文本内容等数据项的本质。与处理结构化数据并执行精确搜索操作的传统关系数据库不同,向量数据库擅长使用 Approximate Nearest Neighbor(ANN)算法等技术进行语义相似性搜索。这种能力对于开发推荐系统、聊天机器人和多媒体内容搜索工具等各种领域的应用程序,以及解决 ChatGPT 等大型语言模型和 AI 带来的挑战(如理解上下文和细微差别以及 AI 幻觉)至关重要。
向量数据库如 Milvus 的出现正在通过在大量非结构化数据中进行基于内容的搜索来改变行业,超越了人类生成标签的限制。使向量数据库脱颖而出的关键特性包括
可扩展性和可调性以处理不断增长的数据量
多租户和数据隔离以提高资源使用效率和隐私
适用于各种编程语言的全面 API 套件
简化与复杂数据交互的用户友好界面
这些属性确保向量数据库能够满足现代应用程序的需求,提供传统数据库无法实现的强大工具来探索和利用非结构化数据。
向量数据库 vs. 向量搜索库
向量搜索库如 FAISS、ScaNN 和 HNSW 提供了构建能够执行高效相似性搜索和密集向量聚类的原型系统的基础工具。这些库虽然功能强大且开源,但主要设计用于向量检索,并提供快速设置功能,如处理大型向量集合和提供评估和参数调整的接口。然而,它们在可扩展性、多租户和动态数据修改方面存在不足,使其不太适合更大、更复杂的数据集和不断增长的用户群。
相比之下,向量数据库作为一种更全面的解决方案,旨在存储和实时检索数百万到数十亿个向量。它们提供了更高的抽象层次、可扩展性、云原生性和用户友好特性,超越了向量搜索库的基本功能。虽然 FAISS 等库是向量数据库可能构建的基本组件,但后者是完整的服务,简化了数据插入和管理等操作,使其更符合大规模动态应用程序在非结构化数据处理领域的需求。
向量数据库 vs. 传统数据库的向量搜索插件
向量数据库和传统数据库的向量搜索插件在处理基于向量的搜索方面发挥着不同的作用。例如,Elasticsearch 8.0 中的插件在现有数据库架构中提供向量搜索功能,作为增强功能而不是全面解决方案。这些插件缺乏嵌入管理和向量搜索的全栈方法,导致在非结构化数据应用中的局限性和性能不佳。
向量数据库操作所需的关键功能(如可调性和用户友好的 API/SDK)在向量搜索插件中显著缺失。例如,Elasticsearch 的 ANN 引擎虽然支持基本的向量存储和查询,但其索引算法和距离度量选项受限,灵活性不如专用向量数据库 Milvus。Milvus 从一开始就被设计为向量数据库,提供了更直观的 API、更广泛的索引方法和距离度量支持,以及潜在的类 SQL 查询能力,突显了其在管理和查询非结构化数据方面的优越性。这种根本区别解释了为什么向量数据库及其为非结构化数据量身定制的全面功能集和架构,优于向量搜索插件,能够实现向量嵌入的最佳搜索和管理。
Milvus 与其他向量数据库有何不同?
Milvus 作为向量数据库,以其可扩展的架构和多样化的功能,旨在加速和统一各种应用程序的搜索体验。其关键特性包括:
可扩展和弹性的架构
Milvus 设计用于卓越的可扩展性和弹性,以适应现代应用程序的动态需求。它通过面向服务的设计实现这一点,解耦存储、协调器和工作节点,允许根据不同的工作负载独立扩展各个计算任务。这种模块化方法确保了不同计算任务可以根据不同的工作负载独立扩展,提供细粒度的资源分配和隔离。
多样化的索引支持
Milvus 支持超过 10 种索引类型,包括广泛使用的 HNSW、IVF、产品量化和基于 GPU 的索引。这种多样性使开发人员能够根据特定的性能和准确性要求优化搜索,确保数据库能够适应各种应用程序和数据特性。通过扩展其索引选项(例如 GPU 索引),Milvus 进一步增强了其在处理复杂搜索任务方面的适应性和有效性。
多样化的搜索能力
Milvus 提供了各种搜索类型,包括 Top-K Approximate Nearest Neighbor(ANN)、Range ANN 和带元数据过滤的搜索,以及即将推出的混合密集和稀疏向量搜索。这种多样性提供了无与伦比的查询灵活性和精度,使开发人员能够根据特定应用程序的需求定制数据检索策略,从而优化搜索结果的相关性和效率。
可调节的一致性
Milvus 提供了一个增量一致性模型,允许用户为查询数据指定“陈旧容忍度”,实现查询性能和数据新鲜度之间的平衡。这种灵活性对于需要最新结果而不牺牲响应时间的应用程序至关重要,有效支持根据应用程序需求的强一致性和最终一致性。
硬件加速计算支持
Milvus 设计用于利用各种计算能力,如 AVX512 和 Neon 的 SIMD 执行,以及量化、缓存感知优化和 GPU 支持。这种方法实现了特定硬件优势的高效利用,确保快速处理和成本效益的可扩展性。通过根据不同应用程序的独特需求调整资源使用,Milvus 增强了向量数据管理和搜索操作的速度和效率。
Milvus 的工作原理简述
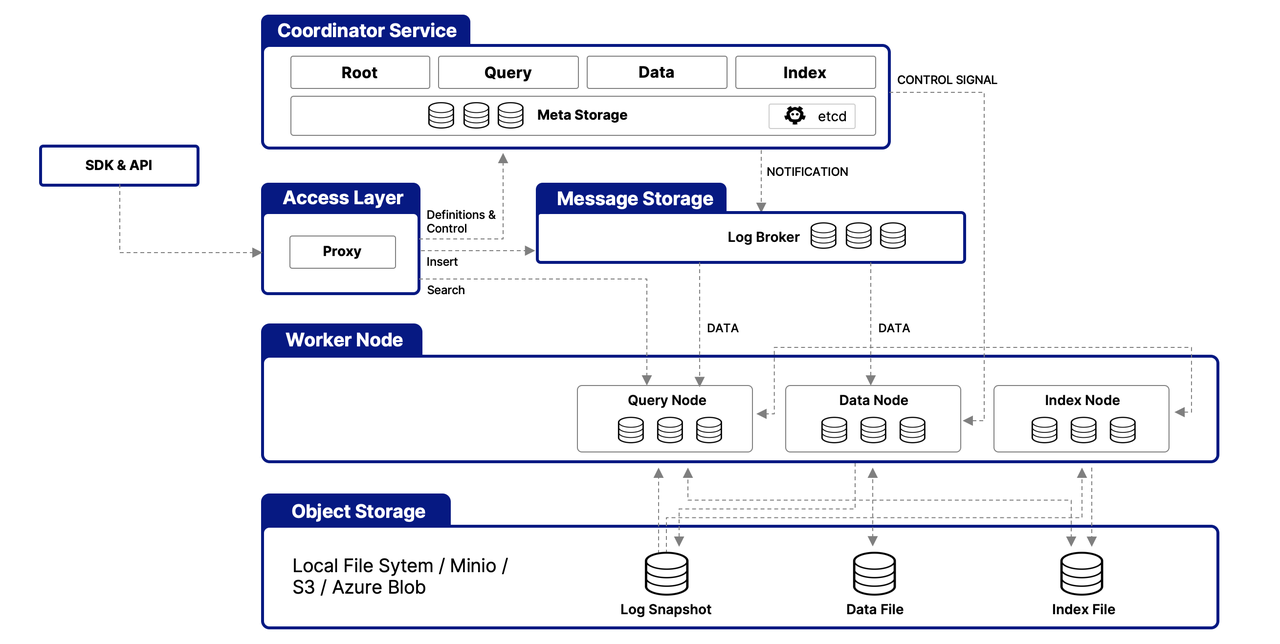
Milvus 围绕多层架构设计,旨在高效处理和管理向量数据,确保可扩展性、可调性和数据隔离。以下是其架构的简化概述:
访问层
这一层作为外部请求的初始接触点,利用无状态代理进行客户端连接管理、静态验证和动态检查。这些代理还处理负载均衡,是实现 Milvus 全面 API 套件的关键。一旦下游服务处理请求,访问层将响应路由回用户。
协调服务
作为中央指挥,这项服务通过四个协调器进行负载均衡和数据管理,确保数据、查询和索引管理的高效性。
The Root Coordinator: managing data-related tasks and global timestamps
The Query Coordinator: overseeing query nodes for search operations
The Data Coordinator: handling data nodes and metadata
The Index Coordinator: maintaining index nodes and metadata
工作节点
负责实际执行任务的工作节点是可扩展的 pod,执行协调器的命令。它们使 Milvus 能够动态适应不断变化的数据、查询和索引需求,支持系统的可扩展性和可调性。
对象存储层
数据持久性的基础,这一层包括
Meta store: using etcd for metadata snapshots and system health checks
Log broker: for streaming data persistence and recovery, utilizing Pulsar or RocksDB
Object storage: storing log snapshots, index files, and query results, with support for services like AWS S3, Azure Blob Storage, and MinIO
接下来去哪里?
- To get hands-on experience with Milvus, follow the get started guide.
- To understand Milvus in more detail, read the Documentation.
- Browse through the Use Cases to learn how other users in our worldwide community are getting value from Milvus.
Join a local Unstructured Data meetup and our Discord.