什麼是 Milvus?
了解 Milvus 的所有信息,不到 10 分鐘。
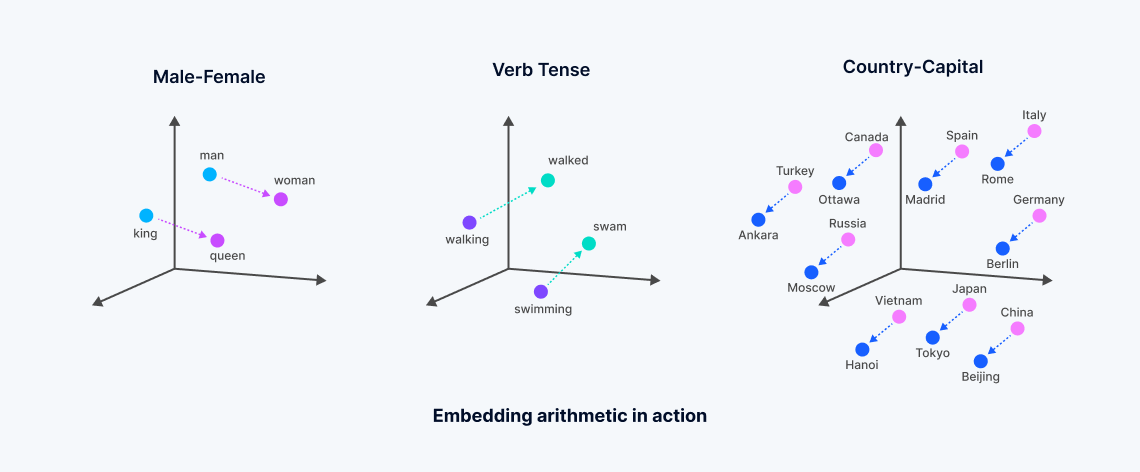
什麼是向量嵌入?
向量嵌入是從機器學習模型中衍生出的數值表示,捕捉非結構化數據的語義。這些嵌入是通過對數據中複雜相關性的分析來生成的,由神經網絡或轉換器架構創建的密集向量空間,其中每個點對應於數據對象的「意義」,例如文檔中的詞。
這個過程將文本或其他非結構化數據轉換為反映語義相似性的向量,從而實現一種稱為「密集向量搜索」的搜索。這與傳統的關鍵字搜索形成鮮明對比,後者依賴於精確匹配並使用稀疏向量。向量嵌入的發展,通常源於主要科技公司訓練的基礎模型,使得搜索更加精確,超越了詞典或稀疏向量搜索方法的侷限。
向量嵌入可以用來做什麼?
向量嵌入可以在各種應用中使用,提高效率和準確性。以下是一些最常見的用例:
查找相似的圖像、視頻或音頻文件
向量嵌入使得可以根據內容而不是關鍵字來搜索相似的多媒體內容,使用卷積神經網絡(CNNs)來分析圖像、視頻幀或音頻片段。這使得可以進行先進搜索,例如根據聲音線索查找圖像,或通過圖像查詢來查找視頻。
加速藥物發現
在製藥行業,向量嵌入可以編碼化學結構,通過測量其與目標蛋白質的相似性來識別有前景的藥物候選者,從而加速藥物發現過程,節省時間和資源,集中在最有可能的線索上。
使用語義搜索提升搜索相關性
通過將內部文檔嵌入到向量中,組織可以利用語義搜索來提升搜索結果的相關性。這種方法使用 RAG(檢索增強生成)的概念來理解查詢背後的意圖,通過 AI 模型如 ChatGPT 提供公司數據的答案,從而減少無關結果和 AI 幻覺。
推薦系統
向量嵌入通過將用戶和商品表示為嵌入來測量相似性,從而實現個性化推薦。這種方法使得推薦更加符合個人偏好,提升用戶滿意度和在線平台的參與度。
異常檢測
在欺詐檢測、網絡安全和工業監控等領域,向量嵌入是識別異常模式的重要工具。數據點表示為嵌入,可以通過計算距離或不相似性來檢測異常,從而實現早期識別和預防潛在措施。
什麼是向量資料庫?
向量數據庫是專為通過向量嵌入和數值表示來捕捉非結構化數據的語義而設計的專門系統。與傳統的關係型數據庫不同,後者處理結構化數據,具有精確的搜索操作,向量數據庫擅長語義相似性搜索,使用 ANN(近似鄰居)等技術。這種能力對於開發跨多個領域的應用至關重要,包括推薦系統、聊機器人和多媒體內容搜索工具,並有助於解決 AI 和大型語言模型(如 ChatGPT)面臨的挑戰,例如理解上下文和語義細微差別以及 AI 幻覺。
向量數據庫如 Milvus 的出現,改變了行業,使得可以在大量非結構化數據中進行基於內容的搜索,超越了人類生成標籤的侷限。其關鍵特徵包括:
可擴展性和可調節性,以應對不斷增長的數據量
多租戶和數據隔離,以實現資源的高效使用和隱私
針對多種編程語言的全面 API 套件
與複雜數據互動的用戶友好界面。
這些屬性確保向量數據庫能夠滿足現代應用的需求,提供強大的工具來探索和利用非結構化數據,這是傳統數據庫無法做到的。
向量數據庫 vs. 向量搜索庫
向量搜索庫如 FAISS、ScaNN 和 HNSW 提供構建原型系統的基礎工具,這些系統能夠進行高效的相似性搜索和密集向量聚類。這些庫雖然功能強大且開源,但主要設計用於向量檢索,具有處理大型向量集和提供用於評估和參數調整的界面等功能。然而,它們在可擴展性、多租戶和動態數據修改方面表現不佳,使其不太適合較大、較複雜的數據集和不斷增長的用戶群。
相比之下,向量數據庫作為更全面的解決方案,設計用於容納和實時檢索數十億個向量。它們提供更高層次的抽象、可擴展性、雲原生性和用戶友好功能,使其更符合大規模、動態應用在非結構化數據處理領域的需求。雖然 FAISS 等庫是向量數據庫可能構建的基本組件,但後者是完整的服務,簡化了數據插入和管理等操作,使其更符合大規模、動態應用的需求。
向量數據庫 vs. 傳統數據庫的向量搜索插件
向量數據庫和傳統數據庫的向量搜索插件在處理基於向量的搜索方面扮演著不同的角色。Elasticsearch 8.0 等插件提供傳統數據庫架構中的向量搜索功能,作為增強而不是全面的解決方案。這些插件缺乏全堆棧式的嵌入管理和向量搜索方法,導致性能和功能受限,不太適合非結構化數據應用。
關鍵功能如可調節性和用戶友好的 API/SDK,這些功能對於有效的向量數據庫操作至關重要,在向量搜索插件中顯然缺失。例如,Elasticsearch 的 ANN 引擎雖然支持基本的向量存儲和查詢,但其索引算法和距離度量選項有限,與專門的向量數據庫如 Milvus 相比,靈活性和靈活性較差。Milvus 從一開始就被設計為向量數據庫,提供更直觀的 API、更廣泛的索引方法和距離度量選項,以及進行類似 SQL 查詢的潛力,突顯了其在管理和查詢非結構化數據方面的優越性。這種根本性差異解釋了為什麼向量數據庫及其全面的功能集和針對非結構化數據的架構,更受青睐於向量搜索插件,以實現最佳的搜索和管理向量嵌入。
Milvus 與其他向量數據庫有何不同?
Milvus 以其可擴展的架構和多樣的功能,設計用於加速和統一各種應用中的搜索體驗。其關鍵特徵包括:
可擴展性和彈性
Milvus 設計用於實現卓越的可擴展性和彈性,以滿足現代應用的動態需求。它通過面向服務的設計、解耦存儲、協調器和工作節點,實現組件式擴展。這種模塊化方法確保不同的計算任務可以根據不同的工作負擔獨立擴展,實現資源的精細分配和隔離。
多樣化的索引支持
Milvus 支持超過 10 種索引類型,包括廣泛使用的 HNSW、IVF、產品量化和基於 GPU 的索引。這種多樣性使開發者能夠根據特定的性能和準確性要求來最佳化搜索,確保數據庫能夠適應各種應用和數據特徵。不斷擴展其索引供應,例如 GPU 索引,進一步提升了 Milvus 的適應性和效能。
多樣化的搜索類型
Milvus 提供多種搜索類型,包括頂 K 近似鄰居(ANN)、範圍 ANN 和帶有元數據過濾的混合搜索,以及即將推出的混合密集和稀疏向量搜索。這種多樣性使開發者能夠自定義數據檢索策略,以滿足特定應用的需求,從而最佳化搜索結果的相關性和效率。
可調節的一致性
Milvus 提供一個 delta 一致性模型,允許用戶指定「陳舊度容忍」來查詢數據,實現一致性和查詢性能之間的平衡。這種靈活性對於需要最新結果但不願意犧牲響應時間的應用至關重要,有效支持強一致性和最終一致性,根據應用需求進行調整。
硬體加速的計算支持
Milvus 設計用於利用各種計算能力,如 AVX512 和 Neon 進行 SIMD 執行,以及量化、高速緩存優化和 GPU 支持。這種方法使得特定硬體的優勢得以充分發揮,確保快速處理和成本效益的可擴展性。通過根據不同應用的具體需求來調整資源使用,Milvus 提升了向量數據的管理和搜索操作的速度和效率。
Milvus 是如何工作的?
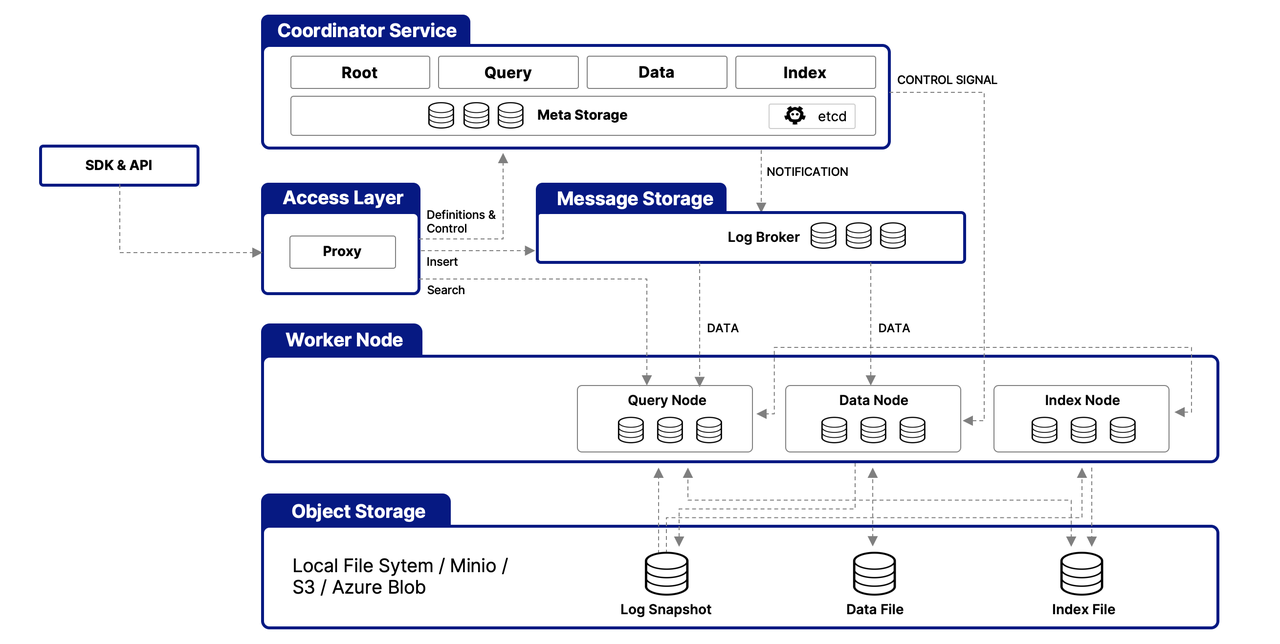
Milvus 構建在多層架構上,設計用於高效處理和處理向量數據,確保可擴展性、可調節性和數據隔離。以下是其架構的簡化概述:
訪問層
作為外部請求的初始接觸點,這一層使用無狀態代理來管理客戶端連接、靜態驗證和動態檢查。這些代理還處理負載均衡,並且是實現 Milvus 全面 API 套件的關鍵。一旦下游服務處理請求,訪問層將響應路由回用戶。
協調服務
作為中央指揮,這項服務通過四個協調器來協調負載均衡和數據管理。
The Root Coordinator: managing data-related tasks and global timestamps
The Query Coordinator: overseeing query nodes for search operations
The Data Coordinator: handling data nodes and metadata
The Index Coordinator: maintaining index nodes and metadata
工作節點
負責實際執行任務,工作節點是可擴展的 pod,執行協調器的命令。它們使 Milvus 能夠動態適應變化的數據、查詢和索引需求,支持系統的可擴展性和可調節性。
對象存儲層
數據持久性的基礎,這一層由
Meta store: using etcd for metadata snapshots and system health checks
Log broker: for streaming data persistence and recovery, utilizing Pulsar or RocksDB
Object storage: storing log snapshots, index files, and query results, with support for services like AWS S3, Azure Blob Storage, and MinIO
從這裡去哪裡?
- To get hands-on experience with Milvus, follow the get started guide.
- To understand Milvus in more detail, read the Documentation.
- Browse through the Use Cases to learn how other users in our worldwide community are getting value from Milvus.
Join a local Unstructured Data meetup and our Discord.