我們為什麼要建立 Loon:一個永遠不會停止變更的 AI 資料儲存引擎。
本部落格原載於 zilliz.com,經許可轉載。
主要觀點
這是一篇長篇深入的工程探討,因此在進入細節之前,先介紹一下重點。
- AI 資料集並非靜態的表格。當團隊更換嵌入模型、新增稀疏向量、修改標題、回填標籤、重建索引以及執行離線分析時,相同的行列會不斷改變。
- 傳統的儲存佈局有三個缺點:長向量列使得回填成本高昂、單一檔案格式無法同時滿足掃描和點讀的需求,以及私有資料庫儲存強迫外部管道建立額外的真相副本。
- Loon 是 Milvus 和 Zilliz Vector Lakebase 的新儲存引擎。它圍繞混合檔案格式、行 ID 對齊以及定義資料集版本化狀態的 Manifest 而建立。
- 我們的目標是讓單一向量資料集能夠支援線上搜尋、離線分析、回填、壓縮和外部運算,而不需要不斷複製、重寫或重新匯入資料。
簡介
有一段時間,有一種反對向量資料庫的論點聽起來很合理。
傳統資料庫已經可以儲存整數、字串、JSON、blob 和索引。為什麼不增加一個 _vector_ 類型,在它旁邊建立一個 ANN 索引,然後就可以了呢?
對於早期的語意搜尋,這已經夠好用了。一個向量列加上一個索引就可以支援一個 demo、一個小型 RAG 應用程式或一個內部搜尋功能。問題稍後就會出現,也就是當資料集開始表現得不像表格,而更像 AI 資料系統時。
生產向量資料集具有行、主鍵、標量欄位和可查詢欄位。在這個意義上,它看起來就像資料庫的表格。但它也具有資料湖的規模和工作流程形狀。它可能包含數以億計的記錄。它會被 Spark、Ray、DuckDB、訓練管道、評估工作和資料品質系統反覆讀取和重寫。
它也依賴於物件儲存。來源物件通常是保留在 S3、GCS、OSS 或其他物件儲存空間中的視訊、影像、PDF、音訊檔案或 Web 文件。資料庫會儲存引用、元資料、衍生特徵和索引。然後,它會新增一些傳統儲存模型無法建立為一級物件來管理的東西:密集內嵌、稀疏向量、標題、向量索引、文字索引、刪除記錄、統計資料、模型版本、解析器版本、外部 blob 引用,以及所有這些東西之間的版本關係。
這就是「只要新增向量列」開始瓦解的地方。問題不在於資料庫是否可以儲存向量位元組。許多系統都可以。更難的問題在於儲存模型是否能處理向量資料如何改變、如何查詢,以及如何在 AI 資料堆疊中共用。
這就是我們為 Milvus 和 Zilliz Vector Lakebase (Zilliz Cloud 的下一演進版本)打造全新儲存引擎 Loon 的原因 。
Loon 的設計理念有三
- 針對不同類型的欄位使用不同的實體格式。
- 透過共用的行 ID 空間對齊這些列。
- 使用 Manifest 定義資料集的版本控制狀態。
要瞭解這些部分為何重要,讓我們從常見的多模式工作流程開始。
向量資料集永遠不會真正完成。
想像一下 AI 團隊為多模式訓練建立一個視訊資料集。
一段長影片上傳到物件儲存空間。管道會根據場景變化、鏡頭邊界或時間視窗,將它切割成片段。過長或過短、模糊、重複或低品質的片段會被過濾掉。剩餘的片段會由美學模型評分、由另一模型加上字幕、由視覺語言模型嵌入,並儲存在向量資料庫中,以進行搜尋、重複資料刪除和訓練資料篩選。
從高層次來看,這個工作流程看起來很簡單:
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
但資料集並非完全成形。
- 在第一個星期,表格可能只包含
clip_id,video_id,start_offset, 和duration。 - 在第二周,團隊會新增
aesthetic_score。 - 第三周,字幕模型運行,每個片段都會得到一個
caption。 - 在第四周,第一個嵌入模型上線,每個片段都得到一個 768 維的 CLIP 嵌入。
- 一個月後,團隊切換模型並回填
embedding_v2,現在是 1024 維。 - 兩個月後,混合搜尋成為需求,因此團隊增加了稀疏向量列。
- 三個月後,標題經過人工審查,必須就地修正。
資料集從未完成。它不斷累積相同基礎行的新詮釋。
這就是向量資料與傳統商業資料的核心差異之一。同一行會一次又一次地被重新處理。而規模將此從不便變成儲存問題:多模態資料集通常不是數百萬筆記錄,而是數億筆或數十億筆記錄。LAION-5B 是一個有用的形狀參考 - 數十億張圖片-文字對,每張都有元資料、標題和嵌入。因此,困難的部分不在於第一次插入。困難的部分在於資料集開始演進之後的所有事情。這種演進會暴露出三個問題。
第一個問題:長欄位使得寫入放大的成本高昂
Parquet 等列式格式對於許多分析性工作負載來說非常好。當模式相當穩定、讀取資料的頻率高於重寫資料的頻率、掃描只會觸及欄位的子集,而且壓縮很重要時,它們就會運作良好。許多分析格式就是在這種情況下被最佳化的。
向量行比分析行寬得多
TPC-Hlineitem 是一個很好的基準。它有 16 列:整數鍵、十進制值、日期、短字串,以及一個小注釋欄位。一列未壓縮的資料大約是 150 位元組。壓縮後,可能會小得多。使用 64 MB 的行群組,儲存系統可以將數十萬行打包到一個群組中。
向量資料集則不然。
LAION 風格的圖像文字資料集更接近目前許多人工智能管道所產生的資料。每一行仍然有一般的元資料:URL、標題、寬度、高度、品質分數、標籤等等。但是一旦加入嵌入,行的物理形狀就會改變。
一個 768 維的 CLIP 向量在 fp16 中約佔 1.5 KB,在 fp32 中約佔 3 KB。這一列可能比整個 TPC-Hlineitem 行大很多。
以現今的標準來看,768 維並非不尋常或很大。1024 或 2048 維嵌入在多模組管道中很常見。OpenAI 的text-embedding-3-large 最高可達 3072 維,在 fp32 中每個向量約為 12 KB。
兩者的比較非常明顯:
| 資料集的形狀 | 近似行大小 | 行的主要內容 |
|---|---|---|
| TPC-H 行項 | ~150 位元組(未壓縮 | 標量和短字串欄位 |
| 具有 768 位元 fp16 向量的 LAION 風格行 | ~1.5 KB+ | 嵌入 |
| 具有 768 位元 fp32 向量的 LAION 風格行 | ~3 KB+ | 嵌入 |
| 具有 3072 位元 fp32 向量的行 | 僅向量 ~12 KB+ | 嵌入 |
在許多 AI 資料集中,向量列並不只是另一個欄位。在物理上,它是大部分的行。這會改變模式演進的成本。
增加一列向量可能意味著數百 GB 的成本。
假設資料集有 1 億個視訊片段。增加一個新的 1024 維 fp32 嵌入列意味著要寫入大約 400 GB 的原始向量資料。這還不包括統計、索引、元資料更新、物件儲存開銷、驗證或服務路徑整合。

如果團隊每個月新增一或兩個類似向量的欄位,例如embedding_v2 、sparse_vector 或 rerank 功能,模式演進就會變成以數百 GB 或 TB 計的經常性 daAta 工程工作。
小規模的邏輯更新可能會觸發大規模的實體重寫
更新同樣重要。
在列式系統中,舊資料通常不會就地更新。刪除日誌會記錄變更的內容,之後的壓縮會將活的資料重寫到新的檔案中。當行數較少時,這種模式是可以管理的。
對於向量資料,小規模的邏輯更新可能會觸發大規模的實體重寫。
人工檢閱工作可能只會修正標題中的幾百個位元組。但如果標題、密集向量、稀疏向量和其他衍生特徵共享相同的實體檔案生命週期,系統最終可能也會重寫向量。邏輯上的改變很小。實體 I/O 可能很大。
這就是向量儲存的寫入放大問題。昂貴的部分不僅在於向量很大。它是因為大型衍生欄位和小型可變欄位經常被視為單一單位的儲存配置綁在一起。
對於 AI 資料集,回填是例行性的工作量。
對於傳統的分析資料表,模式演進可能只是偶爾發生。對於人工智慧資料集而言,這是例行公事。字幕模型升級。更換嵌入模型。之後加入稀疏向量。出現 Rerank 特徵。修正人為標籤。回填治理標籤。重建索引。
這些作業不是簡單的追加。它們經常會修改或延伸現有的行。
這就是向量儲存無法僅優化掃描吞吐量的原因。它還必須降低回填和部分更新的成本。
第二個問題:同樣的資料必須支援掃描和點讀
資料寫入後,讀取路徑就會分裂。相同的向量資料集通常有兩種截然不同的存取模式:分析性掃描和點讀取。
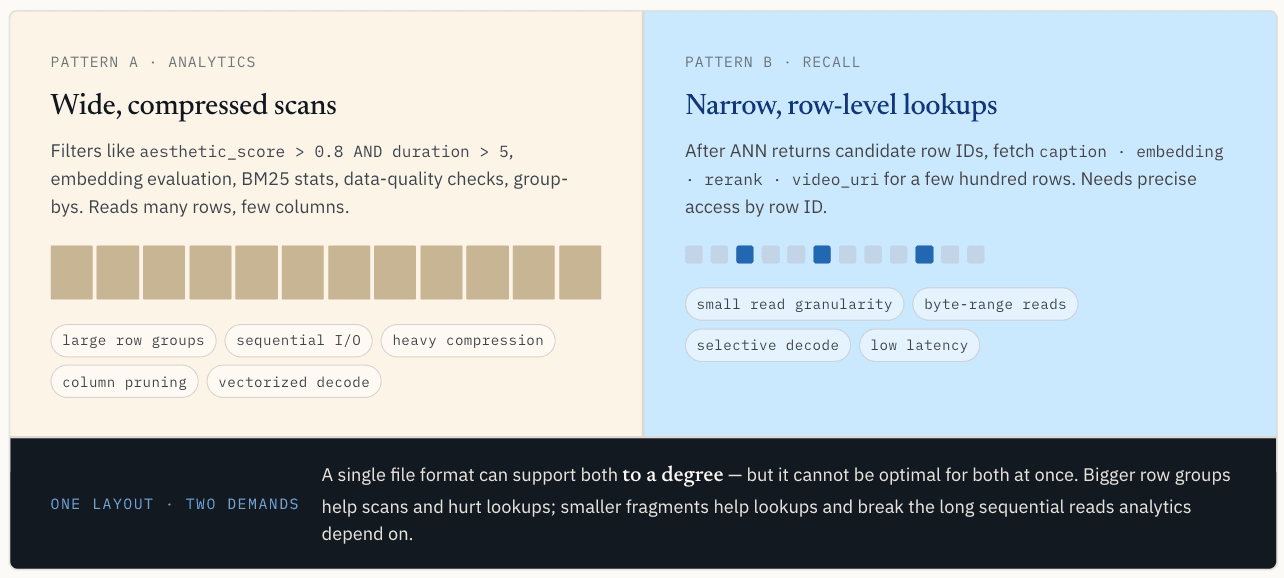
分析型工作負載需要寬範圍的壓縮掃描
管道可能會執行篩選器,例如:
WHERE aesthetic_score > 0.8 AND duration > 5
或執行離線分析、完整嵌入評估、BM25 統計、位圖建構、資料品質檢查、計數和群組分析。
此模式讀取許多行,但只讀取幾列。它喜歡連續 I/O、較大的行群組、壓縮、列修剪、批次解碼和向量化執行。
大型行群在這方面很有幫助。它們可讓單一 I/O 請求讀取大量有用的資料,提高壓縮效率,並為執行引擎提供足夠的連續資料,以攤平開銷。當多個欄位一起讀取時,為了掃描吞吐量而將它們組織起來,也有助於減少向量執行時的快取記憶體錯失。
Parquet 在這條路徑上很強大。
ANN 結果需要狹窄的、行層級的查詢
ANN 搜尋返回候選行 ID 之後,系統通常需要取得如等欄位:
caption
embedding
rerank feature
video_uri
metadata
此模式讀取的行數較少,通常只有數百或數千行,但它需要依行 ID 進行精確的存取。它希望找到特定的行和列,僅擷取所需的位元組範圍,並避免為了擷取幾條記錄而拉取整個行群。
點查找與掃描的偏好幾乎相反。它需要較小的讀取粒度。理想的情況是,儲存層可以依行 ID 找到相關的區段或位元組範圍,僅讀取該範圍,並只解碼結果所需的資料。
壓縮也有不同的取捨。對於掃描,較重的壓縮通常是值得的,因為系統可以讀取大量資料並節省 I/O。對於點查詢,如果擷取一條記錄需要解碼大得多的壓縮區塊,壓縮就會變成負擔。
一種佈局無法同時優化兩種路徑
這是核心衝突。標量篩選和分析需要寬、壓縮、方便掃描的佈局。向量查詢需要狹窄、精確、可回應行的版面。
單一的檔案格式可以在某種程度上支援這兩種需求,但卻無法同時滿足這兩種需求。
如果所有欄位都在 Parquet 中,標量掃描會很舒服。但召回後的 ANN 查找就變得困難了。系統可能只需要幾百個向量、標題或元資料記錄,而儲存層可能必須讀取包含大部分不相關資料的大型行群。
在本機 SSD 上,快取記憶體和 mmap 可以隱藏部分成本。一旦資料儲存在物件儲存中,成本就變得更明顯。每次快取記憶體錯失都可能成為一次遠端範圍讀取。如果候選行分散在許多行群組中,單一查詢可能會觸發多次讀取,每次讀取的資料都會超過查詢所需。在佈局不良的情況下,取得 1,000 個候選行很容易就會造成數十或數百 MB 的不必要 I/O,在極端情況下,甚至會更多。
將行群縮小有助於點查詢,但會損害掃描。太多的小片段會降低壓縮效率、增加元資料開銷,並破壞分析引擎所依賴的長順序讀取。
因此,問題不在於找到單一神奇的行群大小。問題在於同一個資料集被要求像兩個不同的儲存系統一樣運作。
混合搜尋將兩種路徑強制整合為一個查詢
混合搜尋讓衝突更難忽略。單一查詢可能會先套用標量篩選器:
aesthetic_score > 0.8 AND duration > 5
然後執行 ANN 搜尋。
然後再依行 ID 取得標題、向量和元資料。
對使用者而言,這是一個搜尋要求。對儲存層來說,這既是分析掃描,也是低延遲隨機查詢。
這就是為什麼向量儲存需要的不只是更好的 Parquet 設定。它需要根據實際讀取的方式來放置不同的列。
第三個問題:資料集並非活在一個引擎內
前兩個問題發生在資料庫內。第三個問題發生在系統之間的邊界。

AI 資料管道跨越許多系統
在視訊工作流程中,向量資料庫本身很少發生問題。
原始視訊存放在物件儲存空間中。剪輯產生可能在 Spark 或 Ray 中執行。美學評分可以在 GPU 服務中執行。字幕可能會在 LLM 推理管道中執行。嵌入可能由另一個 GPU 工作產生。稀疏向量可能來自 SPLADE 服務。離線評估、訓練資料篩選、人工審查和治理工作都可能在其他地方執行。
向量資料庫為線上搜尋服務,但資料集是由許多系統製作、修正、評估和擴展。
私有儲存格式會產生多份真相副本
如果資料庫使用只有自己才能讀寫的私有實體格式,那麼每個外部作業都需要匯出、轉換、複製和匯入。相同的集合可能存在於資料庫中、Spark 臨時目錄中、評估輸出中,以及本機回填目錄中。那麼真正的問題就來了:
- 哪一份才是真相的來源?
- 哪一份包含上個月的標題模型?
- 哪一行已經經過人工審查修正?
- 哪個稀疏向量列是由哪個模型產生的?
- 哪個向量索引在回填之後仍然有效?
- 這一行是指哪一個原始視訊物件?
在小規模的情況下,團隊有時可以靠命名慣例和人工檢查來生存。如果有數百萬行和 TB 級的嵌入,這就會成為一致性的問題。
向量資料集需要共用的版本控制狀態
Lakehouse 系統解決了結構化資料的版本問題。Iceberg、Delta Lake 和 Hudi 不只是要儲存檔案。它們的核心貢獻是讓多個引擎圍繞相同的資料表狀態進行協調。
向量資料庫現在也需要類似的功能,但狀態更為複雜。它不僅必須包含表檔案和分割,還必須包含向量索引、文字索引、稀疏特徵、刪除記錄、統計資料、行 ID 範圍,以及外部 blob 的參照。
問題並不是簡單的:「Spark 可以讀取 Milvus 檔案嗎?」
問題是,在 Spark 回填稀疏向量列之後,Milvus 如何知道該列屬於哪個版本、涵蓋哪些行、由哪個模型產生,以及線上查詢何時可以安全地使用該列?
答案就在儲存模型裡。
為什麼只有修補程式是不夠的
我們很容易將這三個問題視為三個獨立的工程問題。
- 寫入放大?添加批次。
- 點讀取?增加快取記憶體。
- 外部系統?增加匯出和匯入工具。
這些修補程式可以幫上忙,但無法解決根本問題:向量資料集在物理上是異質的。

在影片範例中,clip_id,video_id,duration, 和aesthetic_score 是短標量欄位。它們有助於篩選和分析。
caption是文字。可用於 BM25、檢視、修正和回填。embedding是長而密集的向量。用於 ANN 召回,之後用於行層級查詢或重排。embedding_v2是新的模型輸出,通常在原始資料插入後很久才回填。sparse_vector支援混合搜尋,並有自己的存取模式。- 原始視訊應留在物件儲存中。資料庫應該儲存參考、校驗和、MIME 類型、解析器版本以及行層級關係。
- 向量索引、文字索引、統計資料和刪除記錄都是衍生物件,有自己的版本語意。
這些物件共用一個邏輯行,但它們不應共用相同的實體佈局或生命週期。
- 如果強制它們使用一個普通的資料表配置,更新就會變得昂貴。
- 如果強迫它們使用一種列式檔案格式,點讀取就會變得昂貴。
- 如果將它們視為不相關的物件檔案,版本管理就會變得很脆弱。
因此,儲存模型必須從資料集是異質的這個事實出發。
這導致三個設計需求:
- 首先,不同的列群應該以不同的實體格式儲存。
- 第二,這些欄位群組需要共用的行 ID 空間,因此它們仍可像單一邏輯表一樣運作。
- 第三,資料集需要一個版本化的 Manifest,以宣告哪些檔案、索引、日誌、統計資料和物件參考屬於目前的檢視。
這就是 Milvus 和 Zilliz Cloud 背後的新儲存引擎 Loon 背後的設計。
Loon: Milvus 與 Zilliz Cloud 背後的儲存引擎,用於演進向量資料集
為了解決上述所有問題,我們為 Milvus 和Zilliz Vector Lakebase(Zilliz Cloud 的下一個演進版本) 建立了Loon 這個新的儲存引擎,專為演進中的向量資料集所設計。
這個名字沿襲了 Zilliz 的鳥類命名傳統。Loon 是一種生活在湖泊上的潛水鳥,與系統的目標不謀而合:向量資料庫每次執行查詢、回填欄位或建立索引時,都不需要移動、掃描或重寫整個資料湖。它應該先瞭解目前資料集的版本,包括其列、索引、統計資料、刪除記錄和物件參考,然後只讀取實際需要的部分。
混合檔案格式、行 ID 對齊和 Manifest 並非三個獨立的功能。它們源自相同的設計假設:向量資料集本質上是異質的。
三個部分,一個儲存模型
混合檔案格式承認不同的欄位有不同的存取模式。標量欄位適合掃描與篩選。向量欄位需要有效率的行層級查詢。原始物件 (例如視訊、PDF、影像和音訊檔案) 屬於物件儲存空間,而非資料庫資料檔案。
行 ID 對齊功能承認這些欄位可能在實體上是分開的,但它們描述的仍是相同的邏輯行。標題、內嵌、稀疏向量和視訊 URI 可能位於不同的檔案和格式中,但它們仍需要匯集為單一結果。
Manifest 承認資料集並不是寫完一次就不管了。它會被多個系統、多個版本、多項任務修改。索引、統計資料、刪除記錄、外部物件引用和列群都必須出現在相同版本的檢視中。
這就是 Loon 不只是更快的向量檔案格式的原因。更快的格式有助於點查詢,但無法解決模式演進或多引擎協調的問題。行 ID 對齊可讓分割的欄位表現得像單一表格,但它無法指定哪些檔案屬於目前的版本。Manifest 可以描述資料集狀態,但如果沒有列群和行 ID 對齊,它就無法清楚地表示一個邏輯集合內的不同實體佈局。
儲存模型需要這三樣東西:不同列群的不同格式、用來重構行的共用行 ID 空間,以及告訴每個讀寫者資料集目前狀態的版本化 Manifest。
Loon 在 Milvus 和 Zilliz Vector Lakebase 中的定位
在 Milvus 中,它以 Manifest、ColumnGroup、檔案格式和檔案系統抽象所建立的模型,取代舊有的段 binlog 儲存層。在Zilliz Vector Lakebase(Zilliz Cloud 的下一個演進) 中,同樣的方向也適用於 Vector Lakebase 架構:保持向量資料庫快速的服務路徑,同時讓底層資料更容易演進、分析,並與外部系統協調。
上層的 Milvus 元件仍保留其熟悉的角色。Proxy 處理路由。QueryCoord 和 DataCoord 處理排程。IndexNode 建立索引。面向應用程式的集合、插入、搜尋和混合搜尋 API 不需要揭露 Manifest 檔案或 ColumnGroup。
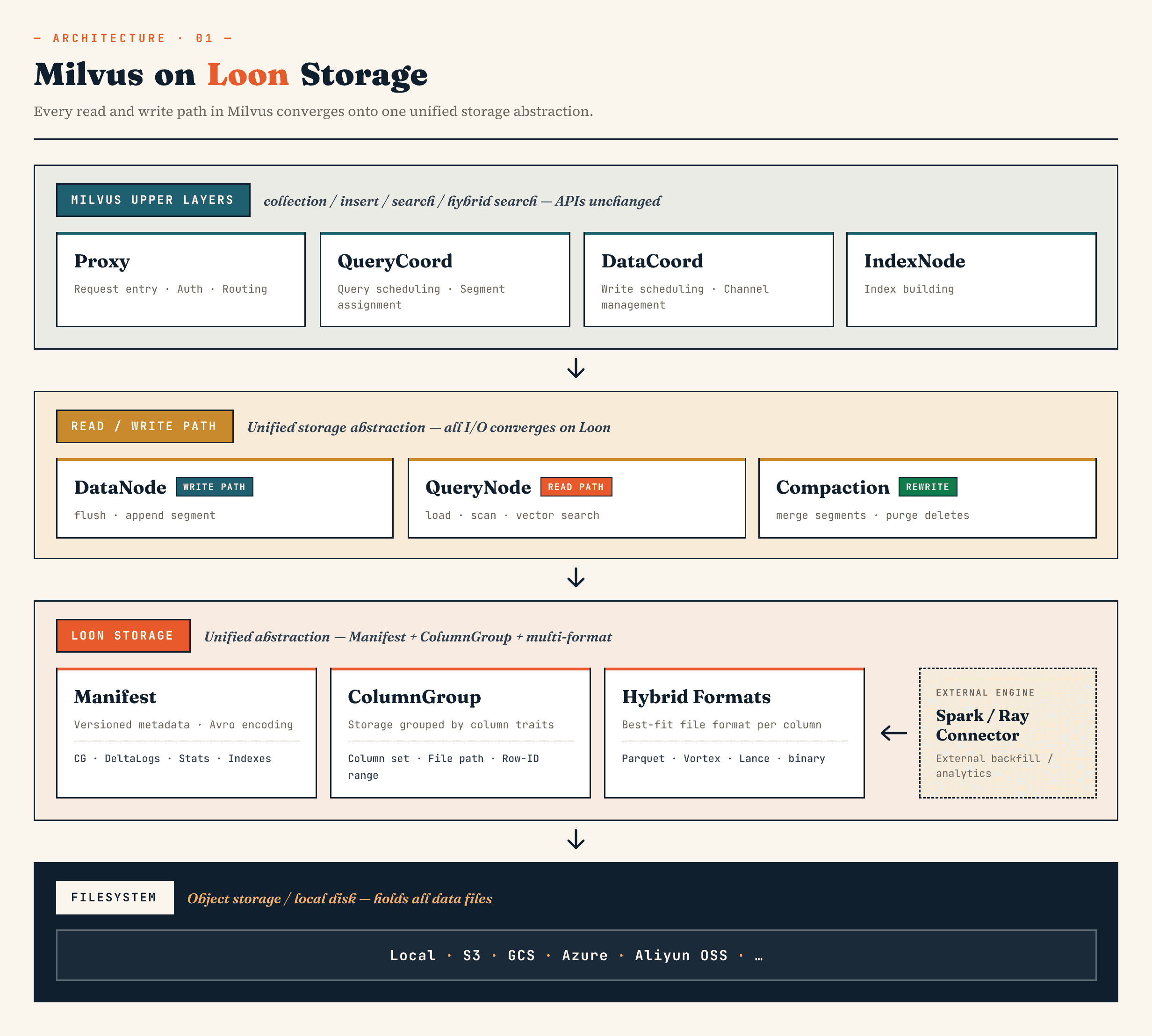
改變在下面。
DataNode、QueryNode、segcore、壓縮和外部連接器可透過相同的儲存抽象運作。這很重要,因為資料集不再僅由資料庫寫入和讀取。它可能會被外部運算系統擴充,並且同時被線上搜尋所使用。
從高層級來看,各層是這樣的:
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
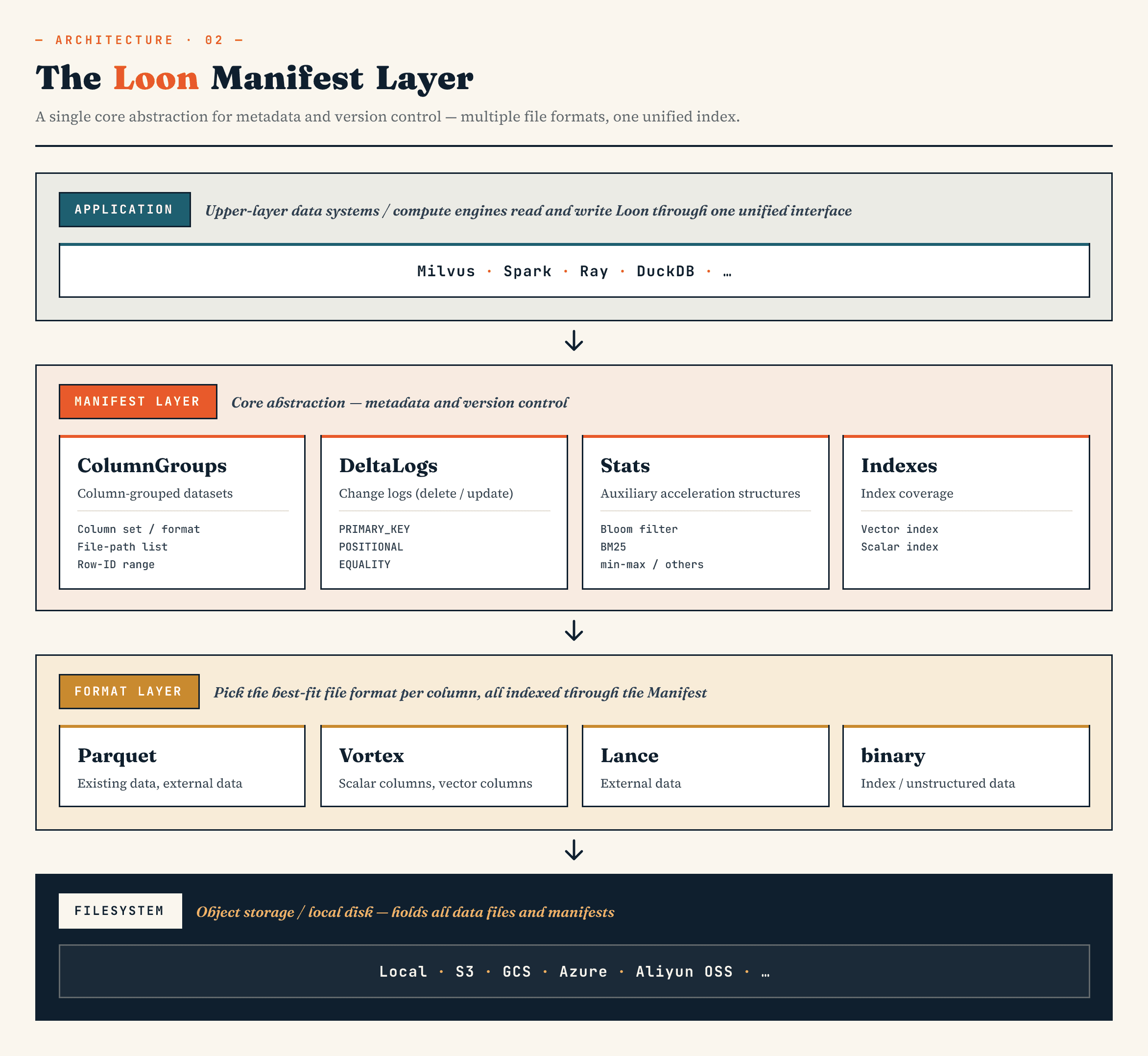
Manifest 描述資料集的版本控制狀態。ColumnGroups 將邏輯集合映射成列的實體群組。檔案格式層可讓每個 ColumnGroup 選擇適當的格式。檔案系統抽象可跨物件儲存與本機儲存運作。
重要的一點是,混合檔案格式、行 ID 對齊和 Manifest 並非獨立的功能。它們共同定義了儲存模型。
有了這個模型,我們就可以逐一檢視三個設計選擇:Loon 如何儲存不同的 ColumnGroup、如何將它們對齊回行,以及 Manifest 如何將這些檔案變成版本化資料集。
設計 1:針對合適的列群使用合適的檔案格式
不同的列有不同的存取模式。它們不應強制使用相同的檔案格式。
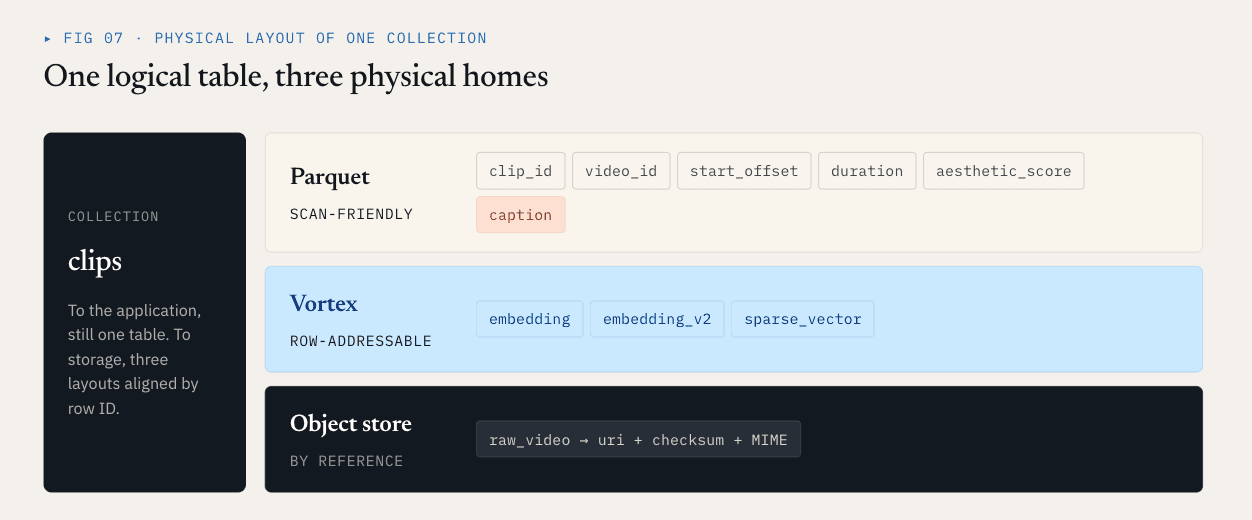
Loon 將邏輯集合分為 ColumnGroups。
- 標量欄位、過濾欄位、業務鍵和統計欄位經常被掃描、過濾、聚合或用於查詢規劃。它們受益於壓縮、欄修剪和生態系統相容性。Parquet 非常適合這些欄位。
- 密集向量、稀疏向量和 rerank 特徵通常會在 ANN 回復後依行 ID 讀取。它們需要低延遲的隨機存取、精確的位元組範圍讀取,以及選擇性的解碼。以區段為導向的佈局較為適合。Loon 在這個方向上使用 Vortex。
- 原始物件,例如視訊、PDF、圖片和音訊檔案,不應該嵌入到向量資料庫的資料檔案中。它們應該保留在物件儲存中。資料庫會記錄引用、校驗和、MIME 類型、解析器版本以及行層級關係。
對於影片範例,實體佈局可能是這樣的:
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
對應用程式而言,這仍然是一個集合。對儲存層而言,該集合的不同部分使用不同的實體格式。這可直接減少不必要的重寫。新增embedding_v2 可以成為一個新的向量 ColumnGroup 加上 Manifest commit。它不需要重寫標題列、標量元資料或現有的嵌入列。
同樣的想法也適用於稀疏向量、rerank 特徵或其他衍生欄位。如果新列能夠在物理上獨立,並透過行 ID 對齊,就不必拖曳不相關的列經過相同的重寫路徑。
Loon 也會適應檔案格式的使用。
對於 Parquet 而言,預設設定並不總是向量重資料的理想選擇。64 MB 的行群對於點查詢來說可能太大,因為一個小的隨機讀取可能會拉出遠多於所需的資料。Loon 將相關路徑中的行群收緊到 1 MB,並停用編碼,例如向量列上的字典編碼,當這些編碼對隨機向量資料沒有幫助時。
對 Vortex 而言,更重要的工作是佈局。Loon 使用平衡掃描效率和點查找的佈局。在一個行群中,相關列的區段可以靠近放置,以支援掃描。為了執行作業,子區段讀取可讓系統只擷取相關位元組,而不是拉取整個區段。
Loon 也支援唯讀的 Lance 整合,因此現有的 Lance 資料集可以在相容性重要時掛載為 ColumnGroup。
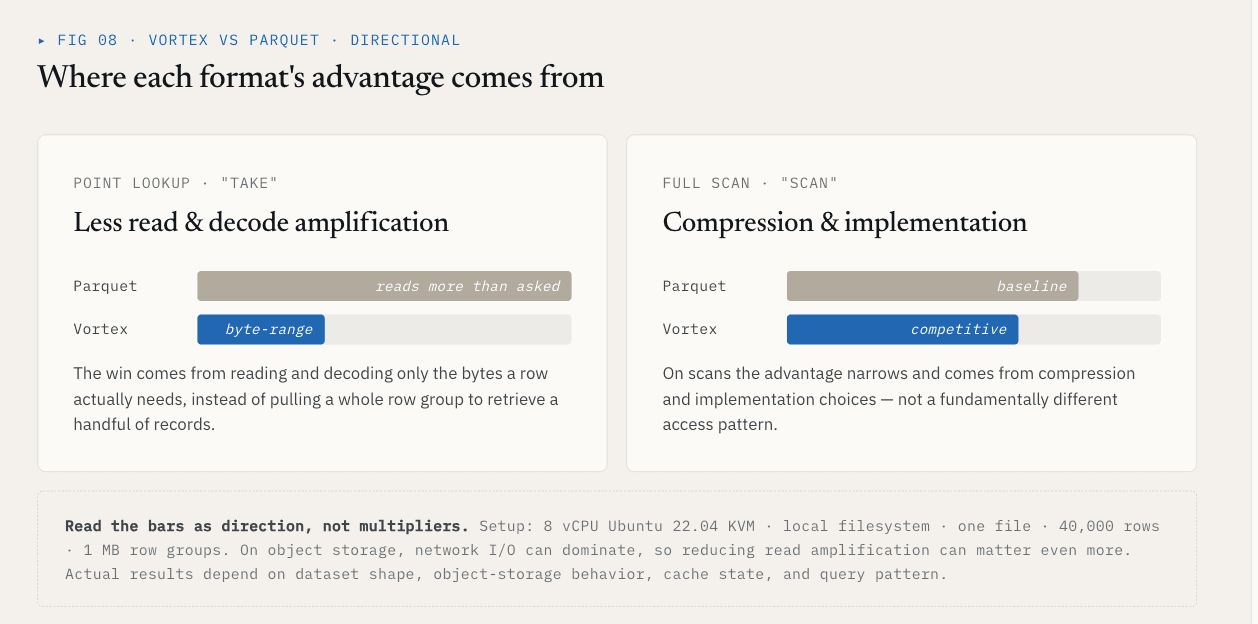
基準測試結果
在一個本機測試中,使用具有 40,000 行的單一檔案和模式{id: int64, name: utf8, value: float64, vector: list<float32>[128]} ,Vortex 顯示出與具有 1 MB 行群的 Parquet 對比的結果:
| 操作 | Vortex | Parquet | 差異 |
|---|---|---|---|
| 採取,K=1000 隨機行 | 5.8 毫秒 | 144 毫秒 | 快 25 倍 |
| 全向量列掃描 | 21 毫秒 | 142 毫秒 | 快 6.76 倍 |
| 檔案大小, ~21 MB 原始資料 | 6.62 MB | 7.16 MB | 小了 7 |
take 的結果來自於減少必須讀取和解碼的無關資料數量。掃描結果來自於壓縮和實作的選擇。
這些數字應依附於其設定:8 vCPU Ubuntu 22.04 KVM、本機檔案系統、一個檔案、40,000 行、1 MB 行群,以及上述模式。在物件儲存上,網路 I/O 可能會佔主導地位,因此降低讀取放大可能更為重要。實際結果取決於資料集的形狀、物件儲存行為、快取儲存狀態和查詢模式。
更廣泛的觀點並非每一列都應該使用 Vortex。
重點是向量資料集需要在 ColumnGroup 層級選擇檔案格式。
設計 2:透過行 ID 對齊實體檔案
混合檔案格式解決了一個問題:不同的列現在可以使用最適合它們的格式。
但這也產生了第二個問題。如果標量欄位住在 Parquet,向量住在 Vortex,而原始物件住在物件儲存空間,系統如何仍將它們視為一個集合?
Loon 使用行 ID 對齊解決了這個問題。
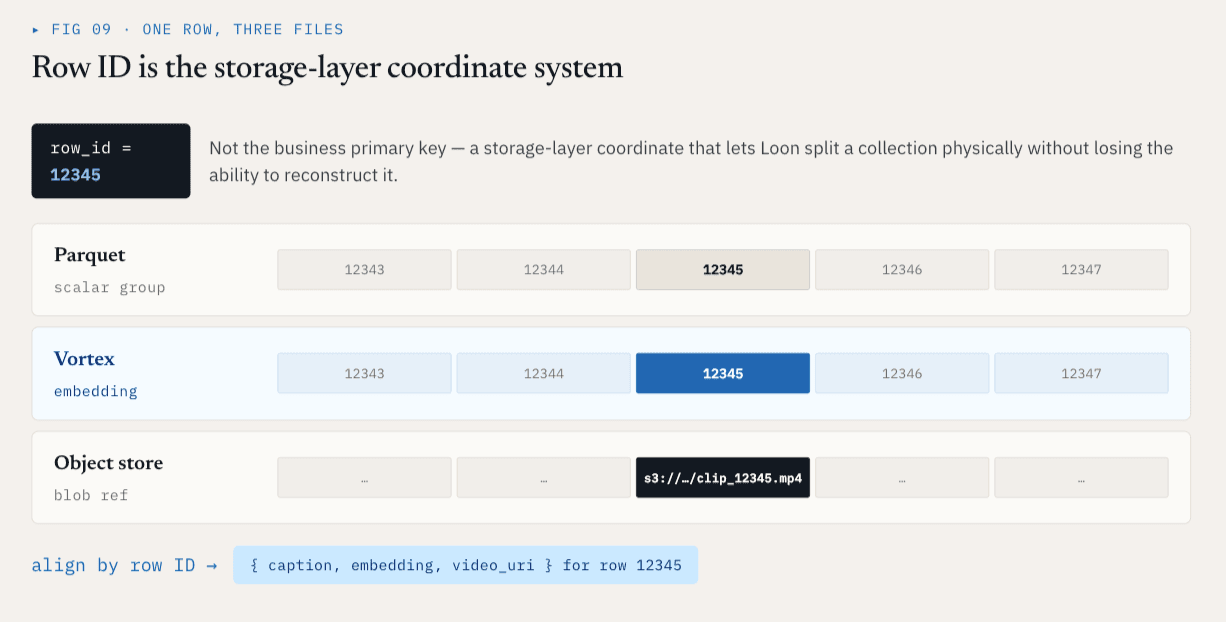
行 ID 是儲存層的坐標系統
每個實體的 ColumnGroupFile 會記錄檔案路徑和它涵蓋的行 ID 範圍:
path
start_index
end_index
不同的 ColumnGroups 可以涵蓋相同的行 ID 空間,即使它們存在於不同的檔案和格式中。
對於行 ID12345 ,標量元資料可能在 Parquet ColumnGroup 中,嵌入可能在 Vortex ColumnGroup 中,而原始視訊可能由物件儲存參考來表示。在邏輯上,它們仍是同一行。這樣儲存層就有了穩定的座標系統。
行 ID 並不是商業主鍵。它是儲存層的坐標系統,可讓 Loon 在物理上分割一個集合,而不會失去邏輯上重建的能力。
新列不需要重寫舊列
新增embedding_v2 不需要重寫原本的標題、元資料或embedding_v1 ColumnGroups。Loon 可以寫入一個新的向量 ColumnGroup,記錄它涵蓋的行 ID 範圍,並透過 Manifest 提交該變更。
這同樣適用於稀疏向量、reerank 特徵,或其他稍後到達的衍生欄位。
只要新的 ColumnGroup 涵蓋正確的行 ID 範圍,它就可以加入相同的邏輯集合,而不會強迫不相關的資料移動。
刪除和壓縮可以更有針對性
行 ID 對齊也有助於刪除。
刪除可以先透過刪除記錄來表達。該行在邏輯層級上會變得不見,而實體清理則會延遲到壓縮為止。當壓縮最終執行時,它並不總是需要重寫與受影響的行相連的每個 ColumnGroup。它可以專注於需要清理的 ColumnGroup。
這一點很重要,因為並非每一列都有相同的成本配置文件。重寫一個簡短的標量 ColumnGroup 與重寫數百 GB 的密集向量是完全不同的。
混合搜尋只能取得它需要的列
行 ID 對齊也是混合搜尋在混合檔案格式之上實用的原因。
ANN 搜尋返回候選行 ID 之後,系統可以只取得最終結果所需的欄位:標題、元資料、向量、重排特徵或物件參考。
例如,查詢可能需要:
caption
embedding
video_uri
這些欄位可能位於不同的 ColumnGroup。Loon 可以依據行 ID 範圍找到相關檔案,讀取必要的位元組範圍,並組合結果。
如果沒有行 ID 對齊,混合格式就只是並排放置的獨立檔案。有了行 ID 對齊,它們就像單一的邏輯集合。
打包閱讀器隱藏了上層的分割
使其可用的運行時元件是 Packed Reader。
上層看到的是統一的 Arrow RecordBatch 串流。在下面,資料可能來自不同檔案格式的多個 ColumnGroup。Packed Reader 隱藏了這些差異,以行 ID 範圍對齊資料,並透過控制記憶體使用量來排程多檔案 I/O。
它也支援按行 ID 直接take 。如果給定一組行 ID,它會找出相關的 ColumnGroupFiles、發出範圍讀取,並傳回所要求的欄位。
對於視訊工作流程,ANN 查詢可能需要caption,embedding, 和video_uri 。Packed Reader 可以取得標量 ColumnGroup 和向量 ColumnGroup,而不碰觸不相關的欄位。
這就是 「分開的檔案」 與 「有多個實體佈局的表格」 之間的差異。
設計 3:讓 Manifest 成為真相的來源
混合檔案格式定義資料如何實體儲存。行 ID 對齊方式決定了分開的 ColumnGroups 仍如何構成單一邏輯表。但系統仍需要回答一個更大的問題:哪些檔案、日誌、統計資料、索引和物件參考屬於資料集的目前版本?這就是 Manifest 的工作。

只有物件儲存目錄是不夠的
物件儲存不是資料庫目錄。目錄可能包含舊檔案、新檔案、失敗的作業輸出、暫存檔案、刪除記錄、仍被舊快照引用的檔案,以及等待清理的檔案。檔案存在的事實,並不表示它屬於目前的資料集版本。
一個 Loon 資料集可能會被組織成類似的目錄:
_metadata/
_data/
_delta/
_stats/
_index/
但目錄結構並非真相的來源。Manifest 才是。讀者不應該列出目錄,並從碰巧存在的任何檔案推斷狀態。他們應該閱讀目前的 Manifest,並遵循它所宣告的版本視圖。
Manifest 定義了資料集的一個版本視圖
Manifest 定義了特定版本的資料集。它記錄
- 存在哪些 ColumnGroups
- 它們涵蓋哪些行 ID 範圍
- 每個 ColumnGroup 使用何種實體格式
- 檔案存放的位置
- 哪些刪除日誌是有效的
- 哪些統計資料可用
- 存在哪些索引
- 引用了哪些外部 blobs
- 這些統計或索引涵蓋哪些列和行範圍
每次更新都會寫入新的 Manifest 版本。開啟第 N 版的讀者會看到第 N 版資料集的穩定視圖。寫入者可以準備第 N+1 版,而不會中斷仍在使用第 N 版的讀者。
Manifest 追蹤的不只是表檔案
在 Loon 中,Manifest 主體使用 Apache Avro 編碼,並圍繞四個主要部分組織。
- ColumnGroups 描述欄位、格式、檔案和行 ID 範圍。
- DeltaLogs 描述刪除。不同的刪除類型涵蓋不同的變更來源,例如來自用戶端的主索引鍵刪除、來自內部壓縮的位置刪除,或來自外部引擎的相等刪除。
- 統計資料包括規劃元資料,例如 bloom 過濾器、BM25 統計資料和最小值/最大值。
- 索引描述索引類型、參數、涵蓋欄位和行 ID 範圍。這可能包括向量索引,例如 HNSW 或 IVF、文字索引、反轉索引、位圖索引以及相關結構。
這是 Loon 與傳統表格清單不同之處。
向量資料集不僅需要追蹤資料檔案和分割區。它也需要追蹤向量索引、文字索引、稀疏特徵、刪除記錄、統計資料、外部物件參考,以及連接這些物件的行 ID 範圍。
Manifest 必須可由資料庫以外的人寫入
最重要的部分不僅是 Manifest 所包含的內容。最重要的是誰可以寫入。
- 如果只有資料庫能夠寫 Manifest,它仍然是內部元資料。更清潔的元資料,但仍是一個引擎的私有資料。
- 如果外部引擎可以產生新的 ColumnGroups、stats 和 Manifest 項目,Manifest 就會變成一個協調介面。
- 例如,Spark 工作可以回填稀疏向量列。它會寫入新的 ColumnGroup、記錄行涵蓋率和統計資料,並提交新的 Manifest。線上查詢可以在作業期間持續讀取舊版本。一旦提交成功,新版本就會變得可見。
這與 Iceberg 和 Delta Lake 的精神類似,但物件模型更為廣泛。向量資料集需要追蹤向量索引、文字索引、稀疏特徵、刪除記錄、統計資料、blob 參考和行 ID 範圍,而不只是表檔案和分割區。
樂觀的提交讓版本更新變得簡單
每次提交都會寫入新的 Manifest 版本。寫入者可以根據版本 N 建立新內容,然後嘗試寫入manifest-{N+1}.avro 。如果版本已經存在,物件儲存的條件寫入或世代配對語意會使提交失敗。寫入者可以針對更新的版本重新嘗試。
這讓 Loon 具備樂觀的並發性,而不會強迫每次更新都要經過繁重、強一致的協調路徑。如果沒有 Manifest,多格式和多引擎儲存最終會變成命名慣例和手動協調。對於小型資料集來說,這也許可行。但對於 TB 規模的向量資料則行不通。
Manifest 可以將異質檔案轉換成一個資料集,讓多個系統可以安全地讀取和更新。
當儲存變成版本控制時,使用者會有什麼改變
對應用程式開發人員而言,Loon 不應該成為新的 API 負擔。
使用者仍可使用熟悉的 Milvus 概念:集合、插入、搜尋及混合搜尋。在正常的應用程式開發過程中,他們應該不需要考慮 Manifest 檔案、ColumnGroups、行 ID 範圍或檔案佈局。
轉變在底下。儲存設備變得更了解 AI 資料集的實際演進方式。
新增嵌入不應移動舊資料
以前,將embedding_v2 加入現有的資料集時,通常需要匯出資料、訓練新模型、產生向量,然後透過 SDK 重新匯入或大量更新資料集。這條路徑會產生大量的作業工作:版本追蹤、失敗作業重試、索引重建、服務影響以及一致性檢查。
有了 Loon,這可以變成模式演進加上新的 ColumnGroup commit。新的嵌入列可以寫成自己的實體 ColumnGroup,以行 ID 對齊,並透過 Manifest 變得可見。舊的標題列、標量元資料列和原始的嵌入列不需要移動。
回填不應需要用戶端更新循環
許多 AI 資料更新都是回填。一個團隊可能會在混合搜尋變得重要之後加入稀疏向量。它可能會在新模型訓練完成後新增 rerank 特徵。它可能會在人工檢閱後修正標題。它可能會在政策更新後加入治理標籤。
在傳統佈局中,即使資料是由 Spark、Ray 或其他外部引擎產生,這些變更通常也會透過用戶端 SDK 更新或僅資料庫寫入路徑發生。
有了 Loon,外部計算系統可以產生新的 ColumnGroups,並透過 Manifest 提交。資料庫不再是每次重寫的唯一入口。
離線分析不應需要另一份真相
以前,團隊通常會將一個線上集合轉換成 Parquet,以進行離線評估或分析。這樣會產生同一資料集的兩個版本:線上合集和分析副本。一旦修正標題、重新生成嵌入、套用刪除記錄或重建索引,團隊就必須詢問哪一個副本是最新的。
透過以 Manifest 為基礎的儲存模型,分析引擎可以讀取與服務系統相同版本的資料集檢視。它們可以只投影所需的列、只掃描相關的行範圍,並針對已宣告的資料集版本而非手動匯出的快照進行工作。
刪除和修正應僅觸及變更的內容
在 AI 資料集中,刪除、標題修正、標籤修正和治理更新都是例行公事。它們不應該強迫每個長向量列通過相同的重寫路徑。
有了 Loon,刪除日誌可以先視為邏輯刪除。之後的壓縮可以清理受影響的 ColumnGroup,而不需要重寫不相關的資料。如果一個簡短的文字欄位變更,儲存層應該不需要重寫數百 GB 的密集向量,只因為它們共用相同的邏輯行。
外部引擎成為工作流程的一部分,而非逃生門
更大的轉變是外部引擎不再被視為向量資料庫以外的系統。
Spark、Ray、評估工作、標籤系統和治理管道已經產生和修改了許多資料。儲存層應該讓他們能夠圍繞單一真相來源進行協作,而不是不斷匯出、複製和重新匯入。
這正是 Manifest 版本所能實現的。它讓線上服務、離線分析、回填工作和壓縮工作擁有資料集的共用檢視。
這些聽起來像是內部儲存的細節,但卻會影響團隊迭代 AI 資料集的速度。每個模型變更、特徵回填、標題修正、品質過濾和索引重建都取決於相同的問題:「系統能否在不移動不需要移動的資料的情況下更新資料集? 」
這就是儲存模型的實用價值。
Loon 可在 Milvus 3.0 beta 和 Zilliz Vector Lakebase 中使用
Loon 可在Milvus 3.0 beta中使用,同時也是Zilliz Vector Lakebase(Zilliz Cloud 的下一個演進版本) 儲存層的一部分。而這個版本著重於三個核心領域:
- Manifest.目標是讓寫入、回填、刪除、統計和索引更新產生版本化的資料集檢視,讓讀者可以一致地開啟。對讀者而言,這表示查詢可以開啟特定的 Manifest 版本,並看到資料集的穩定檢視。對於撰寫者而言,這表示可以先準備新的資料檔案、刪除記錄、統計資料或索引檔案,然後透過版本控制的提交使其可見。
- ColumnGroup 與格式支援。Parquet 支援標量與生態系統友好的列。Vortex 支援重向量存取模式。Lance 可以唯讀模式整合,以與現有的 Lance 資料集相容。
- Lake 上的索引。Scalar 統計、過濾索引和文字倒轉索引可以按行範圍參與 Manifest-based 規劃。Lake 原生向量索引的參與程度較高。HNSW 和 IVF 在物件儲存上有不同的行為,尤其是 HNSW 對隨機存取和快取記憶體的位置性很敏感。它無法簡單地重複使用為本地 SSD 設計的佈局,並期望得到相同的結果。
未來仍有工作要做
- 外部寫入路徑很重要,因為 Spark 和 Ray 應該能夠產生 ColumnGroups 和 Manifest commits,而不需要強制每次回填都經過客戶端 SDK 循環。
- Lakehouse 互操作性很重要,因為許多團隊已經使用目錄和查詢引擎,例如Iceberg、Delta Lake、Trino、DuckDB 和 Athena。向量資料應該能夠參與這個生態系統,而不會失去向量搜尋的效能。
- 索引佈局很重要,因為圖索引和倒轉結構在物件儲存上有不同的存取模式。
- 大型物件語意很重要,因為原始影片、PDF、影像和音訊檔案需要與衍生向量資料集一致的參考管理、版本和刪除行為。
確切的發行行為、預設設定和遷移路徑應遵循相關的 Milvus 和Zilliz Cloud 發行說明。然而,儲存方向是明確的:向量資料庫需要服務層之下的版本化、湖原生基礎。
在 Zilliz Vector Lakebase 下嘗試 Loon
如果您目前的堆疊將線上服務、離線分析、回填以及外部資料湖工作流程分隔為不同的系統,Zilliz Vector Lakebase 值得您一試。您可以在Zilliz Cloud 中試用。新工作電子郵件註冊可獲得 $100 免費點數。也歡迎您與我們討論您的使用案例。
您也可以追蹤Milvus 3.0 版本,看看 Loon 如何在開放原始碼引擎中演化。
Zilliz Vector Lakebase 匯集了
- 針對不同即時效能與成本權衡的分層服務
- 針對大型或探索性工作負載的隨選搜尋,無需隨時運算
- 外部資料湖搜尋,因此您可以直接對現有的資料湖資料進行索引和搜尋
- 跨向量、文字、JSON 和地理空間資料的全方位搜尋,並可進行混合檢索和重新排序
- 以 Vortex 為基礎的統一湖本機儲存,Vortex 是一種開放式格式,專為在向量密集的資料上以更快的速度、更低的成本隨機讀取而設計
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



