Overall Architecture
With the explosive growth of Internet data scale, the product quantity as well as category in the current mainstream e-commerce platform increase on the one hand, the difficulty for users to find the products they need surges on the other hand.
Vipshop is a leading online discount retailer for brands in China. The Company offers high-quality and popular branded products to consumers throughout China at a significant discount from retail prices. To optimize the shopping experience for their customers, the company decided to build a personalized search recommendation system based on user query keywords and user portraits.
The core function of the e-commerce search recommendation system is to retrieve suitable products from a large number of products and display them to users according to their search intent and preference. In this process, the system needs to calculate the similarity between products and users’ search intent & preference, and recommends the TopK products with the highest similarity to users.
Data such as product information, user search intent, and user preferences are all unstructured data. We tried to calculate the similarity of such data using CosineSimilarity(7.x) of the search engine Elasticsearch (ES), but this approach has the following drawbacks.
Long computational response time - the average latency to retrieve TopK results from millions of items is around 300 ms.
High maintenance cost of ES indexes - the same set of indexes is used for both commodity feature vectors and other related data, which hardly facilitates the index construction, but produces a massive amount of data.
We tried to develop our own locally sensitive hash plug-in to accelerate the CosineSimilarity calculation of ES. Although the performance and throughput were significantly improved after the acceleration, the latency of 100+ ms was still difficult to meet the actual online product retrieval requirements.
After a thorough research, we decided to use Milvus, an open source vector database, which is advantaged with the support for distributed deployment, multi-language SDKs, read/write separation, etc. compared to the commonly used standalone Faiss.
Using various deep learning models, we convert massive unstructured data into feature vectors, and import the vectors into Milvus. With the excellent performance of Milvus, our e-commerce search recommendation system can efficiently query the TopK vectors that are similar to the target vectors.
Overall Architecture
 As shown in the diagram, the system overall architecture consists of two main parts.
Write process: the item feature vectors (hereinafter referred to as item vectors) generated by the deep learning model are normalized and written into MySQL. MySQL then reads the processed item feature vectors using the data synchronization tool (ETL) and import them into the vector database Milvus.
Read process: The search service obtains user preference feature vectors (hereinafter referred to as user vectors) based on user query keywords and user portraits, queries similar vectors in Milvus and recalls TopK item vectors.
Milvus supports both incremental data update and entire data update. Each incremental update has to delete the existing item vector and insert a new item vector, meaning that every newly updated collection will be re-indexed. It better suits the scenario with more reads and fewer writes. Therefore, we choose the entire data update method. Moreover, it takes only a few minutes to write the entire data in batches of multiple partitions, which is equivalent to near real-time updates.
Milvus write nodes perform all write operations, including creating data collections, building indexes, inserting vectors, etc., and provide services to the public with write domain names. Milvus read nodes perform all read operations and provide services to the public with read-only domain names.
Whereas the current version of Milvus does not support switching collection aliases, we introduce Redis to seamlessly switch aliases between multiple entire data collections.
The read node only needs to read existing metadata information and vector data or indexes from MySQL, Milvus, and GlusterFS distributed file system, so the read capability can be horizontally extended by deploying multiple instances.
Implementation Details
Data Update
The data update service includes not only writing vector data, but also data volume detection of vectors, index construction, index pre-loading, alias control, etc. The overall process is as follows.
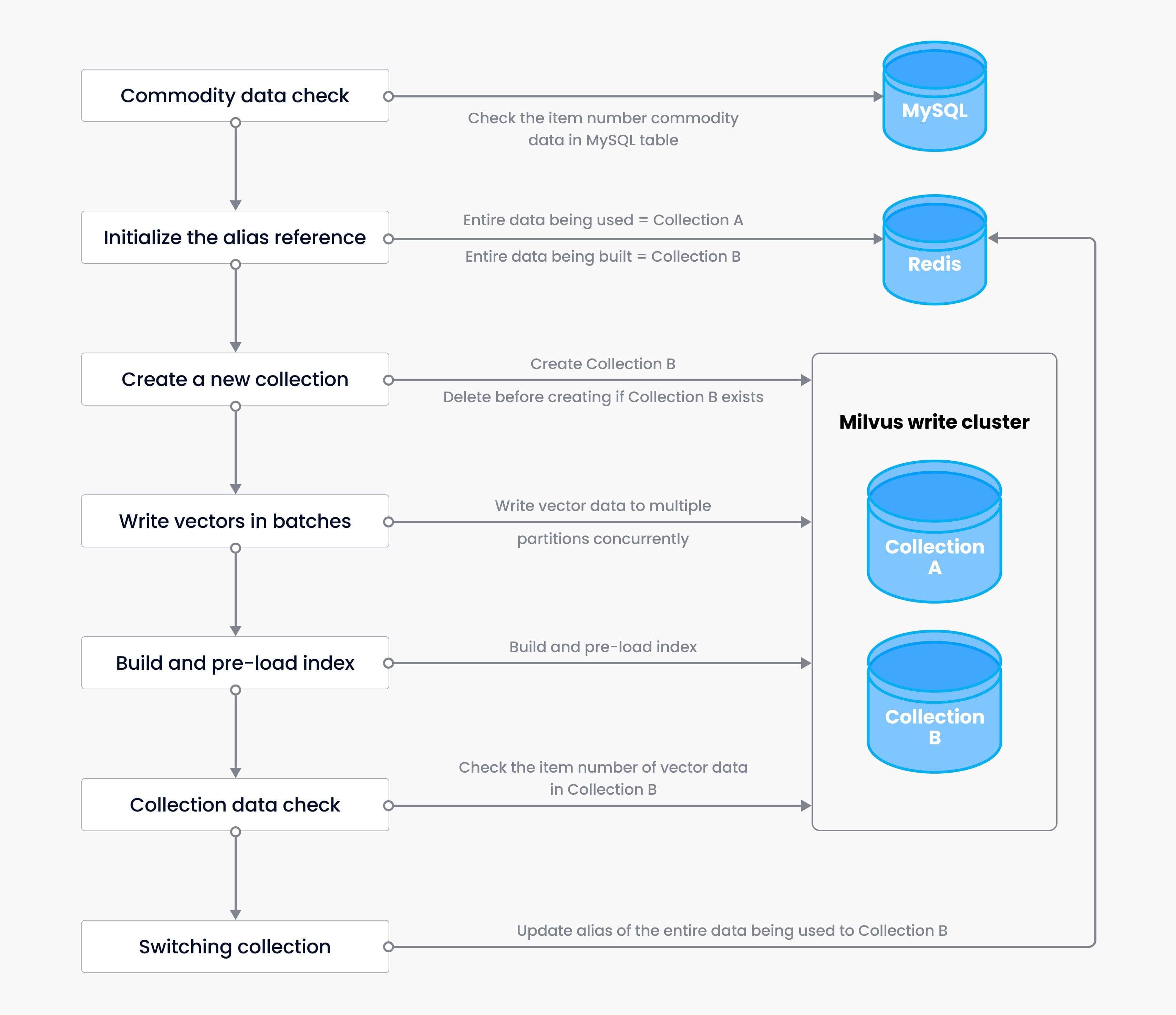 Process
Process
Assume that before building the entire data, CollectionA provides data service to the public, and the entire data being used is directed to CollectionA (
redis key1 = CollectionA). The purpose of constructing entire data is to create a new collection CollectionB.Commodity data check - check the item number of commodity data in the MySQL table, compare the commodity data with the existing data in CollectionA. Alert can be set in accordance with quantity or percentage. If the set quantity (percentage) is not reached, the entire data will not be built, and it will be regarded as the failure of this building operation, triggering the alert; once the set quantity (percentage) is reached, the entire data building process starts.
Start building the entire data - initialize the alias of the entire data being built, and update Redis. After updating, the alias of the entire data being built is directed to CollectionB (
redis key2 = CollectionB).Create a new entire collection - determine if CollectionB exists. If it does, delete it before creating a new one.
Data batch write-in - calculate the partition ID of each commodity data with its own ID using modulo operation, and write the data to multiple partitions to the newly created collection in batches.
Build and pre-load index - Create index (
createIndex()) for the new collection. The index file is stored in distributed storage server GlusterFS. The system automatically simulates query on the new collection and pre-load the index for query warm-up.Collection data check - check the item number of data in the new collection, compare the data with the existing collection, and set alarms based on the quantity and percentage. If the set number (percentage) is not reached, the collection will not be switched and the building process will be regarded as a failure, triggering the alert.
Switching collection - Alias control. After updating Redis, the entire data alias being used is directed to CollectionB (
redis key1 = CollectionB), the original Redis key2 is deleted, and the building process is completed.
Data Recall
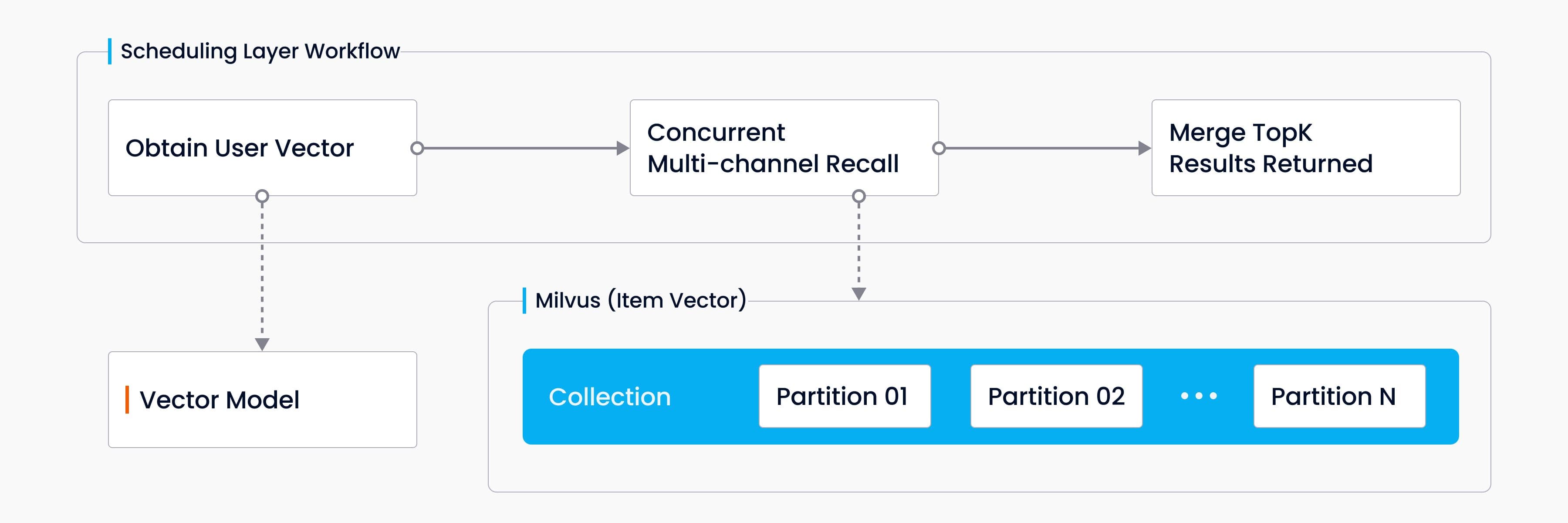
The Milvus partition data is called several times to calculate the similarity between user vectors, obtained based on user query keywords and user portrait, and item vector, and the TopK item vectors are returned after merging. The overall workflow schematic is as follow:
 workflow
workflow
The following table lists the main services involved in this process. It can be seen that the average latency for recalling TopK vectors is about 30 ms.
| Service | Role | Input Parameters | Output parameters | Response latency |
|---|---|---|---|---|
| User vectors acquisition | Obtain user vector | user info + query | user vector | 10 ms |
| Milvus Search | Calculate the vector similarity and return TopK results | user vector | item vector | 10 ms |
| Scheduling Logic | Concurrent result recalling and merging | Multi-channel recalled item vectors and the similarity score | TopK items | 10 ms |
Implementation process:
- Based on the user query keywords and user portrait, the user vector is calculated by the deep learning model.
- Obtain the collection alias of the entire data being used from Redis currentInUseKeyRef and get Milvus CollectionName. This process is data synchronization service, i.e. switching alias to Redis after entire data update.
- Milvus is called concurrently and asynchronously with the user vector to obtain data from different partitions of the same collection, and Milvus calculates the similarity between the user vector and the item vector, and returns the TopK similar item vectors in each partition.
- Merge the TopK item vectors returned from each partition, and rank the results in the reverse order of similarity distance, which are calculated using the IP inner product (the greater the distance between the vectors, the more similar they are). The final TopK item vectors are returned.
Looking Ahead
At present, Milvus-based vector search can be used steadily in the search of recommendation scenarios, and its high performance gives us more room to play in the dimensionality of the model and algorithm selection.
Milvus will play a crucial role as the middleware for more scenarios, including recall of main site search and all-scenario recommendations.
The three most anticipated features of Milvus in the future are as follows.
- Logic for collection alias switching - coordinate the switching across collections without external conponents.
- Filtering mechanism - Milvus v0.11.0 only supports ES DSL filtering mechanism in standalone version. The newly released Milvus 2.0 supports scalar filtering, and read/write separation.
- Storage support for Hadoop Distributed File System (HDFS) - The Milvus v0.10.6 we are using only supports POSIX file interface, and we have deployed GlusterFS with FUSE support as the storage backend. However, HDFS is a better choice in terms of performance and ease of scaling.
Lessons Learned and Best Practices
- For applications where read operations are the primary focus, a read-write separation deployment can significantly increase the processing power and improve performance.
- The Milvus Java client lacks a reconnection mechanism because the Milvus client used by the recall service is resident in memory. We have to build our own connection pool to ensure the availability of the connection between the Java client and the server through heartbeat test.
- Slow queries occur occasionally on Milvus. This is due to insufficient warm-up of the new collection. By simulating the query on the new collection, the index file is loaded into the memory to achieve the index warm-up.
- nlist is the index building parameter and nprobe is the query parameter. You need to get a reasonable threshold value according to your business scenario through pressure testing experiments to balance the retrieval performance and accuracy.
- For static data scenario, it is more efficient to import all data into the collection first and build indexes later.
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



