Recommending content using semantic vector search
With 71% of Americans getting their news recommendations from social platforms, personalized content has quickly become how new media is discovered. Whether people are searching for specific topics, or interacting with recommended content, everything users see is optimized by algorithms to improve click-through rates (CTR), engagement, and relevance. Sohu is a NASDAQ-listed Chinese online media, video, search and gaming group. It leveraged Milvus, an open-source vector database built by Zilliz, to build a semantic vector search engine inside its news app. This article explains how the company used user profiles to fine-tune personalized content recommendations over time, improving user experience and engagement.
Recommending content using semantic vector search
Sohu News user profiles are built from browsing history and adjusted as users search for, and interact with, news content. Sohu’s recommender system uses semantic vector search to find relevant news articles. The system works by identifying a set of tags that are expected to be of interest to each user based on browsing history. It then quickly searches for relevant articles and sorts the results by popularity (measured by average CTR), before serving them to users.
The New York Times alone publishes 230 pieces of content a day, which offers a glimpse at the magnitude of new content an effective recommendation system must be capable of processing. Ingesting large volumes of news demands millisecond similarity search and hourly matching of tags to new content. Sohu chose Milvus because it processes massive datasets efficiently and accurately, reduces memory usage during search, and supports high-performance deployments.
Understanding a news recommendation system workflow
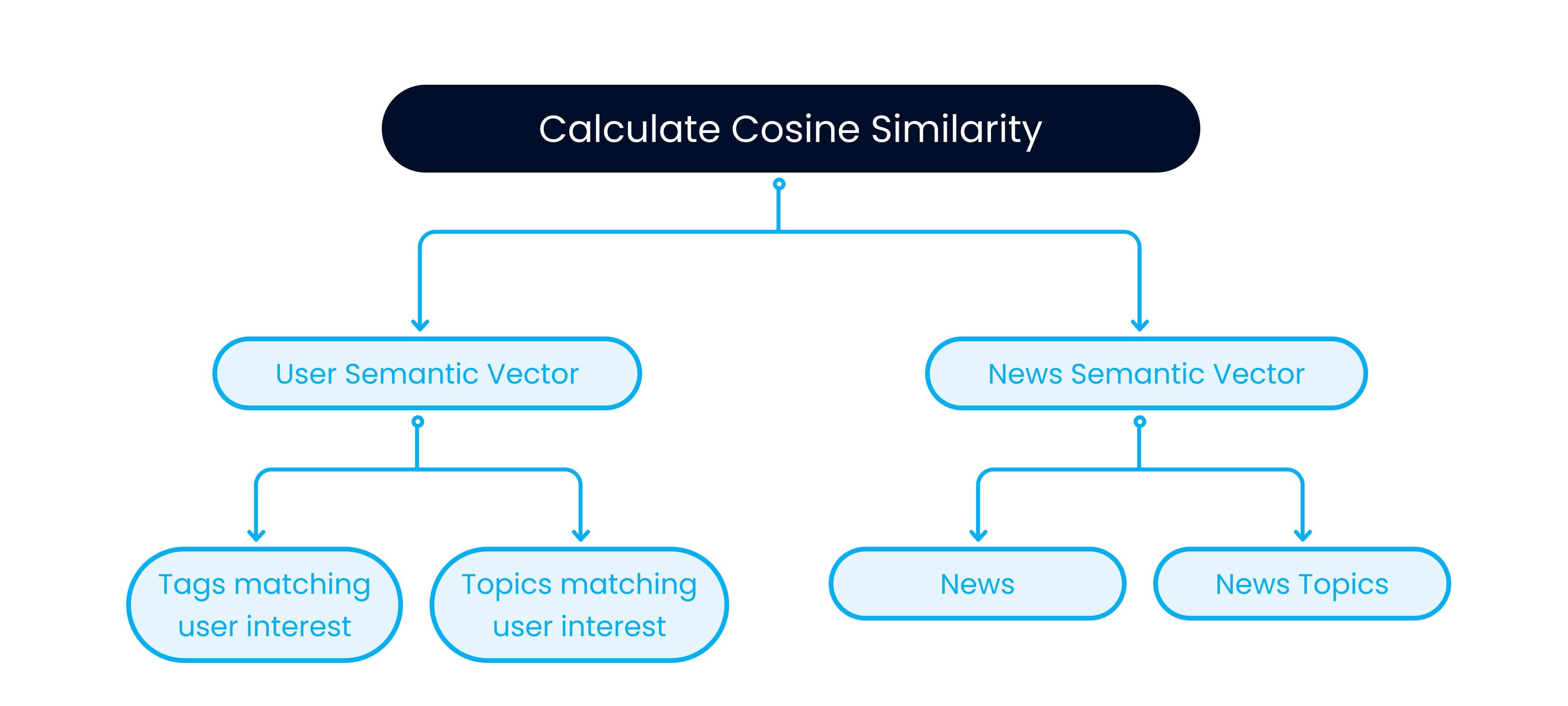
Sohu’s semantic vector search-based content recommendation relies on the Deep Structured Semantic Model (DSSM), which uses two neural networks to represent user queries and news articles as vectors. The model calculates the cosine similarity of the two semantic vectors, then the most similar batch of news is sent to the recommendation candidates pool. Next, news articles are ranked based on their estimated CTR, and those with the highest predicted click-through rate are displayed to users.
Encoding news articles into semantic vectors with BERT-as-service
To encode news articles into semantic vectors, the system uses the BERT-as-service tool. If the word count of any piece of content exceeds 512 while using this model, information loss occurs during the embedding process. To help overcome this, the system first extracts a summary and encodes it into a 768-dimensional semantic vector. Then the two most relevant topics from each news article are extracted, and the corresponding pre-trained topic vectors (200-dimensions) are identified based on topic ID. Next the topic vectors are spliced into the 768-dimensional semantic vector extracted from the article summary, forming a 968-dimensional semantic vector.
New content continuously comes in through Kafta, and is converted into semantic vectors before being inserted into the Milvus database.
Extracting semantically similar tags from user profiles with BERT-as-service
The other neural network of the model is user semantic vector. Semantically similar tags (e.g., coronavirus, covid, COVID-19, pandemic, novel strain, pneumonia) are extracted from user profiles based on interests, search queries, and browsing history. The list of acquired tags is sorted by weight, and the top 200 are divided into different semantic groups. Permutations of the tags within each semantic group are used to generate new tag phrases, which are then encoded into semantic vectors through BERT-as-service
For each user profile, sets of tag phrases have a corresponding set of topics that are marked by a weight indicating a user’s interest level. The top two topics out of all relevant topics are selected and encoded by the machine learning (ML) model to be spliced into the corresponding tag semantic vector, forming a 968-dimensional user semantic vector. Even if the system generates the same tags for different users, different weights for tags and their corresponding topics, as well as explicit variance between each user’s topic vectors, ensures recommendations are unique
The system is able to make personalized news recommendations by calculating the cosine similarity of the semantic vectors extracted from both user profiles and news articles.
 Sohu01.jpg
Sohu01.jpg
Computing new semantic user profile vectors and inserting them to Milvus
Semantic user profile vectors are computed daily, with data from the previous 24-hour period processed the following evening. Vectors are inserted into Milvus individually and run through the query process to serve relevant news results to users. News content is inherently topical, requiring computation to be run hourly to generate a current newsfeed that contains content that has a high predicted click-through rate and is relevant to users. News content is also sorted into partitions by date, and old news is purged daily.
Decreasing semantic vector extraction time from days to hours
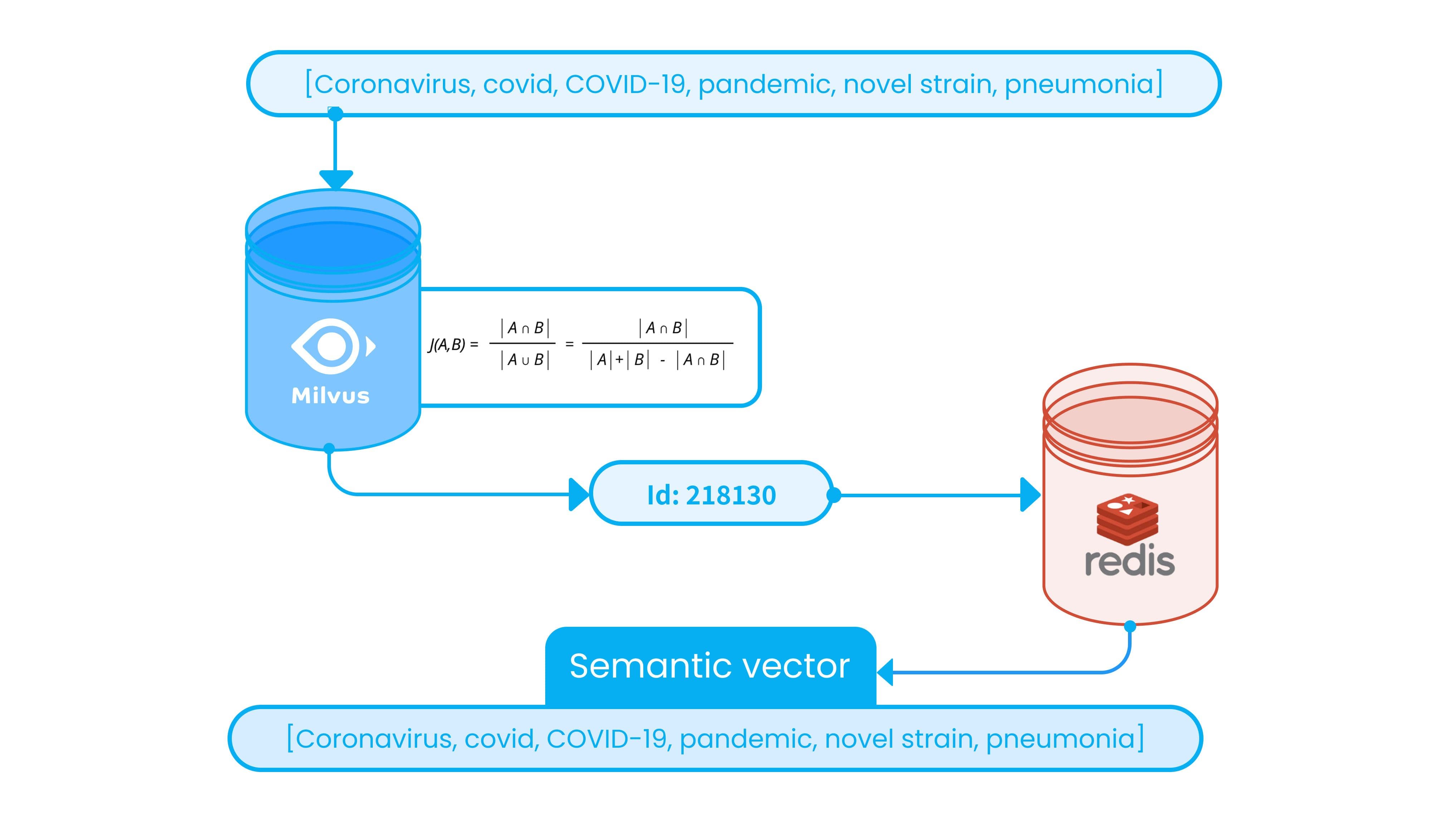
Retrieving content using semantic vectors requires converting tens of millions of tag phrases into semantic vectors every day. This is a time-consuming process that would require days to complete even when running on graphics processing units (GPU), which accelerate this type of computation. To overcome this technical issue, semantic vectors from the previous embedding must be optimized so that when similar tag phrases surface corresponding semantic vectors are directly retrieved.
The semantic vector of the existing set of tag phrases is stored, and a new set of tag phrases that is generated daily gets encoded into MinHash vectors. Jaccard distance is used to compute similarity between the MinHash vector of the new tag phrase and the saved tag phrase vector. If the Jaccard distance exceeds a pre-defined threshold, the two sets are considered similar. If the similarity threshold is met, new phrases can leverage the semantic information from previous embeddings. Tests suggest a distance above 0.8 should guarantee enough accuracy for most situations.
Through this process, the daily conversion of the tens of millions of vectors mentioned above is reduced from days to around two hours. Although other methods of storing semantic vectors might be more appropriate depending on specific project requirements, computing similarity between two tag phrases using Jaccard distance in a Milvus database remains an efficient and accurate method in a wide variety of scenarios.
 Sohu02.jpg
Sohu02.jpg
Overcoming “bad cases” of short text classification
When classifying news text, short news articles have fewer features for extraction than longer ones. Because of this, classification algorithms fail when content of varying lengths is run through the same classifier. Milvus helps solve this issue by searching for multiple pieces of long text classification information with similar semantics and reliable scores, then using a voting mechanism to modify short text classification.
Identifying and resolving misclassified short text
Precise classification of each news article is crucial to providing useful content recommendations. Since short news articles have fewer features, applying the same classifier for news with different lengths results in a higher error rate for short text classification. Human labeling is too slow and inaccurate for this task, so BERT-as-service and Milvus are used to quickly identify misclassified short text in batches, correctly reclassify them, then use batches of data as a corpus for training against this problem.
BERT-as-service is used to encode a total number of five million long news articles with a classifier score greater than 0.9 into semantic vectors. After inserting the long text articles into Milvus, short text news is encoded into semantic vectors. Each short news semantic vector is used to query the Milvus database and obtain the top 20 long news articles with the highest cosine similarity to the target short news. If 18 of the top 20 semantically similar long news appear to be in the same classification and it differs from that of the query short news, then the short news classification is considered incorrect and must be adjusted to align with the 18 long news articles.
This process quickly identifies and corrects inaccurate short text classifications. Random sampling statistics show that after short text classifications are corrected, the overall accuracy of text classification exceeds 95%. By leveraging the classification of high-confidence long text to correct the classification of short text, the majority of bad classification cases are corrected in a short amount of time. This also offers a good corpus for training a short text classifier.

Milvus can power real-time news content recommendation and more
Milvus greatly improved the real-time performance of Sohu’s news recommendation system, and also bolstered the efficiency of identifying misclassified short text. If you’re interested in learning more about Milvus and its various applications:
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



