O que é Milvus?
Tudo o que você precisa saber sobre Milvus em menos de 10 minutos.
O que são embeddings vetoriais?
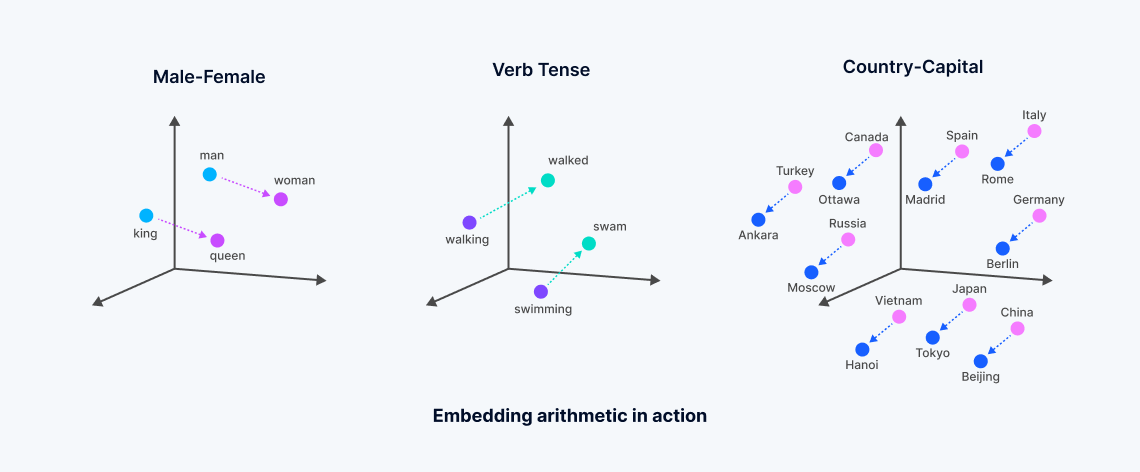
Embeddings vetoriais são representações numéricas derivadas de modelos de aprendizado de máquina, que encapsulam o significado semântico de dados não estruturados. Esses embeddings são gerados através da análise de correlações complexas dentro dos dados por redes neurais ou arquiteturas transformadoras, criando um espaço vetorial denso onde cada ponto corresponde ao "significado" de objetos de dados, como palavras em um documento.
Esse processo transforma dados textuais ou outros dados não estruturados em vetores que refletem semelhanças semânticas—palavras com significados relacionados são posicionadas mais próximas nesse espaço multidimensional, facilitando um tipo de busca conhecido como "busca vetorial densa". Isso contrasta com a busca por palavras-chave tradicional, que depende de correspondências exatas e usa vetores esparsos. O desenvolvimento de embeddings vetoriais, muitas vezes provenientes de modelos fundamentais treinados extensivamente por grandes empresas de tecnologia, permite buscas mais matizadas que capturam a essência dos dados, ultrapassando as limitações dos métodos de busca lexical ou vetorial esparsa.
Para que posso usar embeddings vetoriais?
Embeddings vetoriais podem ser utilizados em várias aplicações, aumentando a eficiência e a precisão de várias maneiras. Aqui estão alguns dos casos de uso mais frequentes:
Encontrar Imagens, Vídeos ou Arquivos de Áudio Semelhantes
Embeddings vetoriais permitem a busca de conteúdo multimídia semelhante por conteúdo, em vez de apenas palavras-chave, usando Redes Neurais Convolucionais (CNNs) para analisar imagens, quadros de vídeo ou segmentos de áudio. Isso permite buscas avançadas, como encontrar imagens com base em pistas sonoras ou vídeos por meio de consultas de imagem, comparando as representações embedidas armazenadas em bancos de dados vetoriais.
Acelerar a Descoberta de Medicamentos
Na indústria farmacêutica, embeddings vetoriais podem codificar estruturas químicas de compostos, facilitando a identificação de candidatos promissores a medicamentos ao medir sua semelhança com proteínas-alvo. Isso acelera o processo de descoberta de medicamentos, economizando tempo e recursos ao focar nas pistas mais viáveis.
Aumentar a Relevância da Busca com Busca Semântica
Ao embedir documentos internos em vetores, as organizações podem utilizar a busca semântica para melhorar a relevância dos resultados da busca. Esse método utiliza o conceito de Geração Aumentada de Recuperação (RAG) para entender a intenção por trás das consultas, fornecendo respostas a partir dos dados da empresa por meio de modelos de IA como o ChatGPT, reduzindo assim resultados irrelevantes e alucinações de IA.
Sistemas de Recomendação
Embeddings vetoriais revolucionam sistemas de recomendação ao representar usuários e itens como embeddings para medir a semelhança. Essa abordagem permite recomendações personalizadas com base em preferências individuais, aumentando a satisfação e o engajamento do usuário com plataformas online.
Detecção de Anomalias
Em campos como detecção de fraudes, segurança de rede e monitoramento industrial, embeddings vetoriais são instrumentais na identificação de padrões incomuns. Pontos de dados representados como embeddings permitem a detecção de anomalias ao calcular distâncias ou dissimilaridades, facilitando a identificação precoce e medidas preventivas contra problemas potenciais.
O que são bases de dados vectoriais?
Bancos de dados vetoriais são sistemas especializados projetados para gerenciar e recuperar dados não estruturados por meio de embeddings vetoriais e representações numéricas que capturam a essência de itens de dados como imagens, áudio, vídeos e conteúdo textual. Ao contrário dos bancos de dados relacionais tradicionais que lidam com dados estruturados com operações de busca precisas, os bancos de dados vetoriais se destacam em buscas de semelhança semântica usando técnicas como o algoritmo Approximate Nearest Neighbor (ANN). Essa capacidade é crucial para o desenvolvimento de aplicações em vários domínios, incluindo sistemas de recomendação, chatbots e ferramentas de busca de conteúdo multimídia, e para abordar os desafios impostos pela IA e grandes modelos de linguagem como o ChatGPT, como entender o contexto e nuances e alucinação de IA.
A chegada de bancos de dados vetoriais como Milvus está transformando indústrias ao permitir buscas baseadas em conteúdo em uma vasta gama de dados não estruturados, ultrapassando as limitações de rótulos gerados por humanos. As características-chave que diferenciam os bancos de dados vetoriais incluem
Escalabilidade e ajustabilidade para lidar com volumes crescentes de dados
Multi-tenancy e isolamento de dados para uso eficiente de recursos e privacidade
Uma suite abrangente de APIs para diversas linguagens de programação
Interfaces amigáveis que simplificam a interação com dados complexos.
Esses atributos garantem que os bancos de dados vetoriais possam atender às demandas de aplicações modernas, oferecendo ferramentas poderosas para explorar e aproveitar dados não estruturados de maneiras que os bancos de dados tradicionais não podem.
Banco de Dados Vetorial vs. Biblioteca de Busca Vetorial
Bibliotecas de busca vetorial como FAISS, ScaNN e HNSW oferecem ferramentas fundamentais para construir sistemas protótipos capazes de realizar buscas de semelhança eficientes e agrupamento vetorial denso. Essas bibliotecas, embora poderosas e de código aberto, são projetadas principalmente para recuperação vetorial e oferecem configuração rápida com capacidades como manipulação de grandes coleções de vetores e fornecimento de interfaces para avaliação e ajuste de parâmetros. No entanto, elas são deficientes em termos de escalabilidade, multi-tenancy e modificação dinâmica de dados, tornando-as menos adequadas para conjuntos de dados maiores e mais complexos e bases de usuários em crescimento.
Em contraste, os bancos de dados vetoriais surgem como uma solução mais abrangente projetada para acomodar o armazenamento e a recuperação em tempo real de milhões a bilhões de vetores. Eles fornecem um nível mais alto de abstração, escalabilidade, natividade na nuvem e recursos amigáveis que superam as funcionalidades básicas das bibliotecas de busca vetorial. Embora bibliotecas como FAISS sejam componentes integrais que os bancos de dados vetoriais podem construir, estes últimos são serviços completos que simplificam operações como inserção e gerenciamento de dados, alinhando-se mais com as demandas de aplicações dinâmicas e em grande escala no campo do processamento de dados não estruturados.
Bancos de Dados Vetoriais vs. Plugins de Busca Vetorial para Bancos de Dados Tradicionais
Bancos de dados vetoriais e plugins de busca vetorial para bancos de dados tradicionais desempenham papéis distintos na manipulação de buscas baseadas em vetores. Plugins como os do Elasticsearch 8.0 oferecem capacidades de busca vetorial dentro de arquiteturas de banco de dados existentes, funcionando como melhorias em vez de soluções abrangentes. Esses plugins carecem de uma abordagem full-stack para gerenciamento de embeddings e busca vetorial, resultando em limitações e desempenho subótimo para aplicações de dados não estruturados.
Características-chave como ajustabilidade e APIs/SDKs amigáveis, essenciais para a operação efetiva do banco de dados vetorial, estão notavelmente ausentes nos plugins de busca vetorial. Por exemplo, o motor ANN do Elasticsearch, embora suporte armazenamento e consulta básicos de vetores, é limitado por seu algoritmo de indexação e opções de métrica de distância, oferecendo menos flexibilidade em comparação com um banco de dados vetorial dedicado como Milvus. Milvus, projetado desde o início como um banco de dados vetorial, oferece uma API mais intuitiva, suporte mais amplo para métodos de indexação e métricas de distância, e o potencial para consultas semelhantes a SQL, destacando sua superioridade na gestão e consulta de dados não estruturados. Essa diferença fundamental sublinha por que bancos de dados vetoriais, com seus conjuntos de recursos abrangentes e arquitetura adaptada para dados não estruturados, são preferidos em relação aos plugins de busca vetorial para alcançar busca e gestão ótimas de embeddings vetoriais.
Como o Milvus se diferencia de outros bancos de dados vetoriais?
Milvus se destaca como um banco de dados vetorial com sua arquitetura escalável e diversas capacidades projetadas para acelerar e unificar experiências de busca em várias aplicações. Os principais destaques de recursos são:
Arquitetura Escalável e Elástica
Milvus é projetado para escalabilidade e elasticidade excepcionais, acomodando as demandas dinâmicas de aplicações modernas. Isso é alcançado por meio de design orientado a serviços, desacoplando armazenamento, coordenadores e workers, permitindo escalabilidade componente a componente. Essa abordagem modular garante que diferentes tarefas computacionais possam escalar independentemente de acordo com as cargas de trabalho variáveis, fornecendo alocação e isolamento de recursos de grão fino.
Suporte Diversificado de Índices
Milvus suporta uma ampla gama de mais de 10 tipos de índices, incluindo os amplamente utilizados como HNSW, IVF, Quantização de Produto e indexação baseada em GPU. Essa variedade capacita os desenvolvedores a otimizar buscas de acordo com requisitos específicos de desempenho e precisão, garantindo que o banco de dados possa se adaptar a uma ampla gama de aplicações e características de dados. A expansão contínua de suas ofertas de índices, por exemplo, índice GPU, melhora ainda mais a adaptabilidade e eficácia do Milvus na gestão de tarefas de busca complexas.
Capacidades de Busca Versáteis
Milvus oferece uma ampla gama de tipos de busca, incluindo top-K Approximate Nearest Neighbor (ANN), Range ANN e busca com filtragem de metadados, e a próxima busca híbrida de vetores densos e esparsos. Essa diversidade permite uma flexibilidade e precisão de consulta inigualáveis, concedendo aos desenvolvedores a capacidade de personalizar estratégias de recuperação de dados para atender às demandas específicas das aplicações, otimizando assim tanto a relevância quanto a eficiência dos resultados da busca.
Consistência Ajustável
Milvus oferece um modelo de consistência delta que permite aos usuários especificar uma "tolerância de obsolescência" para dados de consulta, permitindo um equilíbrio personalizado entre desempenho de consulta e atualização de dados. Essa flexibilidade é crucial para aplicações que exigem resultados atualizados sem sacrificar os tempos de resposta, suportando eficazmente tanto a consistência forte quanto a eventual conforme as necessidades da aplicação.
Suporte para Computação Acelerada por Hardware
Milvus é projetado para aproveitar vários tipos de capacidades de computação, como AVX512 e Neon para execução SIMD, junto com quantização, otimizações cache-aware e suporte a GPU. Essa abordagem permite o uso eficiente das forças específicas do hardware, garantindo processamento rápido e escalabilidade custo-efetiva. Ajustando o uso de recursos às demandas únicas de diferentes aplicações, Milvus melhora tanto a velocidade quanto a eficiência das operações de gerenciamento e busca de dados vetoriais.
Como o Milvus funciona em resumo?
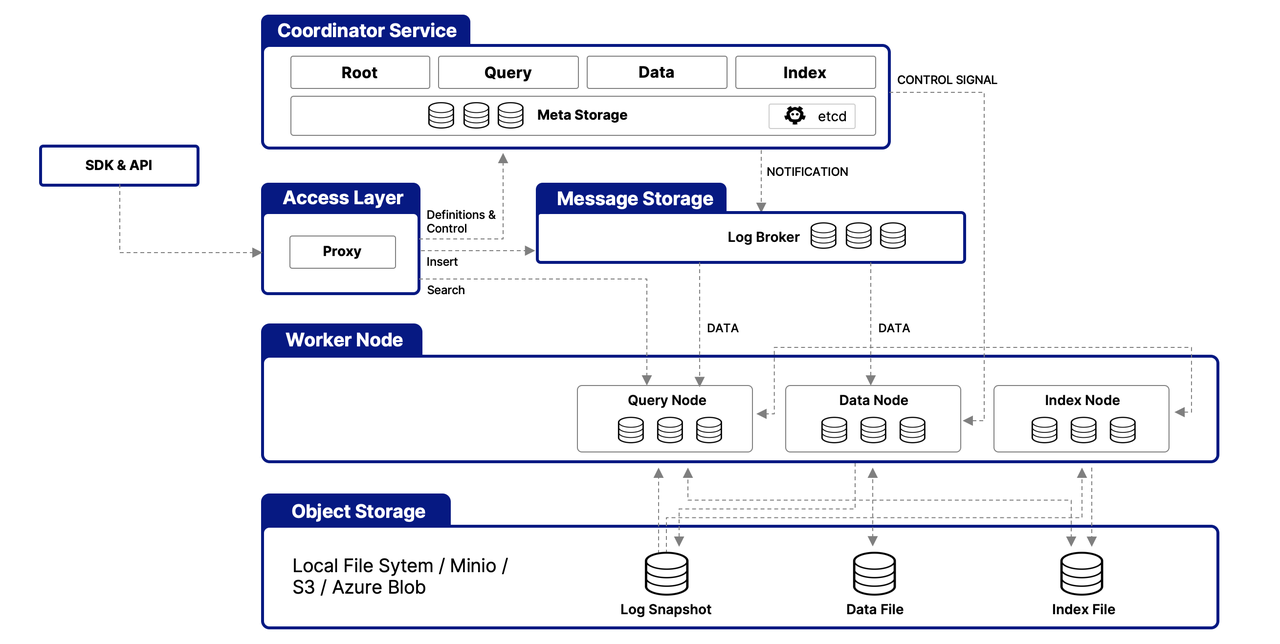
Milvus é estruturado em torno de uma arquitetura multicamadas projetada para gerenciar e processar eficientemente dados vetoriais, garantindo escalabilidade, ajustabilidade e isolamento de dados. Aqui está uma visão simplificada de sua arquitetura:
Camada de Acesso
Essa camada serve como o ponto de contato inicial para solicitações externas, utilizando proxies sem estado para gerenciamento de conexões de clientes, verificação estática e verificações dinâmicas. Esses proxies também lidam com o balanceamento de carga e são fundamentais para implementar a suite abrangente de APIs do Milvus. Uma vez que o serviço downstream processa uma solicitação, a camada de acesso roteia a resposta de volta ao usuário.
Serviço de Coordenação
Atuando como comando central, esse serviço orquestra o balanceamento de carga e o gerenciamento de dados por meio de quatro coordenadores, que garantem o gerenciamento eficiente de dados, consultas e índices.
The Root Coordinator: managing data-related tasks and global timestamps
The Query Coordinator: overseeing query nodes for search operations
The Data Coordinator: handling data nodes and metadata
The Index Coordinator: maintaining index nodes and metadata
Nós de Trabalho
Responsáveis pela execução real das tarefas, os nós de trabalho são pods escaláveis que executam comandos dos coordenadores. Eles permitem que o Milvus se ajuste dinamicamente às mudanças nos dados, consultas e demandas de indexação, suportando a escalabilidade e ajustabilidade do sistema.
Camada de Armazenamento de Objetos
Fundamental para a persistência de dados, essa camada consiste em
Meta store: using etcd for metadata snapshots and system health checks
Log broker: for streaming data persistence and recovery, utilizing Pulsar or RocksDB
Object storage: storing log snapshots, index files, and query results, with support for services like AWS S3, Azure Blob Storage, and MinIO
Para onde ir daqui?
- To get hands-on experience with Milvus, follow the get started guide.
- To understand Milvus in more detail, read the Documentation.
- Browse through the Use Cases to learn how other users in our worldwide community are getting value from Milvus.
Join a local Unstructured Data meetup and our Discord.