Building a Graph-based Recommendation System with Milvus, PinSage, DGL, and MovieLens Datasets
Recommendation systems are powered by algorithms that have humble beginnings helping humans sift through unwanted email. In 1990, the inventor Doug Terry used a collaborative filtering algorithm to sort desirable email from junk mail. By simply “liking” or “hating” an email, in collaboration with others doing the same thing to similar mail content, users could quickly train computers to determine what to push through to a user’s inbox—and what to sequester to the junk mail folder.
In a general sense, recommendation systems are algorithms that make relevant suggestions to users. Suggestions can be movies to watch, books to read, products to buy, or anything else depending on the scenario or industry. These algorithms are all around us, influencing the content we consume and the products we purchase from major tech companies such as Youtube, Amazon, Netflix and many more.
Well designed recommendation systems can be essential revenue generators, cost reducers, and competitive differentiators. Thanks to open-source technology and declining compute costs, customized recommendation systems have never been more accessible. This article explains how to use Milvus, an open-source vector database; PinSage, a graph convolutional neural network (GCN); deep graph library (DGL), a scalable python package for deep learning on graphs; and MovieLens datasets to build a graph-based recommendation system.
Jump to:
- How do recommendation systems work?
- Tools for building a recommender system
- Building a graph-based recommender system with Milvus
How do recommendation systems work?
There are two common approaches to building recommendation systems: collaborative filtering and content-based filtering. Most developers make use of either or both methods and, though recommendation systems can vary in complexity and construction, they typically include three core elements:
- User model: Recommender systems require modeling user characteristics, preferences, and needs. Many recommendation systems base their suggestion on implicit or explicit item-level input from users.
- Object model: Recommender systems also model items in order to make item recommendations based on user portraits.
- Recommendation algorithm: The core component of any recommendation system is the algorithm that powers its recommendations. Commonly used algorithms include collaborative filtering, implicit semantic modeling, graph-based modeling, combined recommendation, and more.
At a high level, recommender systems that rely on collaborative filtering build a model from past user behavior (including behavior inputs from similar users) to predict what a user might be interested in. Systems that rely on content-based filtering use discrete, predefined tags based on item characteristics to recommend similar items.
An example of collaborative filtering would be a personalized radio station on Spotify that is based on a user’s listening history, interests, music library and more. The station plays music that the user hasn’t saved or otherwise expressed interest in, but that other users with similar taste often have. A content-based filtering example would be a radio station based on a specific song or artist that uses attributes of the input to recommend similar music.
Tools for building a recommender system
In this example, building a graph-based recommendation system from scratch depends on the following tools:
Pinsage: A graph convolutional network
PinSage is a random-walk graph convolutional network capable of learning embeddings for nodes in web-scale graphs containing billions of objects. The network was developed by Pinterest, an online pinboard company, to offer thematic visual recommendations to its users.
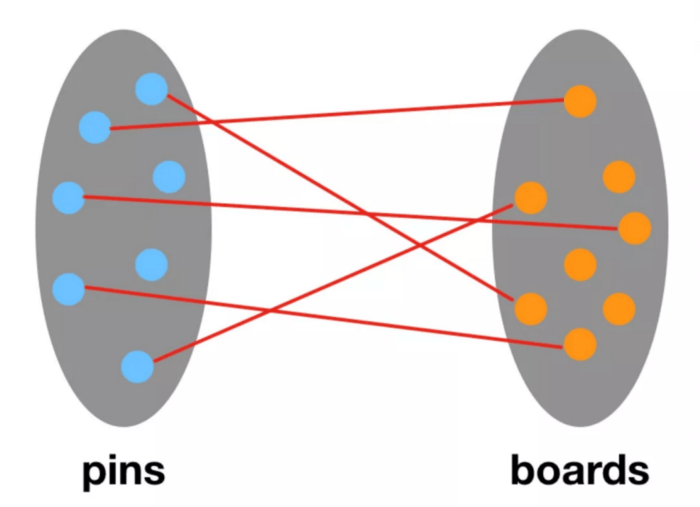
Pinterest users can “pin” content that interests them to “boards,” which are collections of pinned content. With over 478 million monthly active users (MAU) and over 240 billion objects saved, the company has an immense amount of user data that it must build new technology to keep up with.
 1.png
1.png
PinSage uses pins-boards bipartite graphs to generate high-quality embeddings from pins that are used to recommend visually similar content to users. Unlike traditional GCN algorithms, which perform convolutions on the feature matrices and the full graph, PinSage samples the nearby nodes/Pins and performs more efficient local convolutions through dynamic construction of computational graphs.
Performing convolutions on the entire neighborhood of a node will result in a massive computational graph. To reduce resource requirements, traditional GCN algorithms update a node’s representation by aggregating information from its k-hop neighborhood. PinSage simulates random-walk to set frequently visited content as the key neighborhood and then constructs a convolution based on it.
Because there is often overlap in k-hop neighborhoods, local convolution on nodes results in repeated computation. To avoid this, in each aggregate step PinSage maps all nodes without repeated calculation, then links them to the corresponding upper-level nodes, and finally retrieves the embeddings of the upper-level nodes.
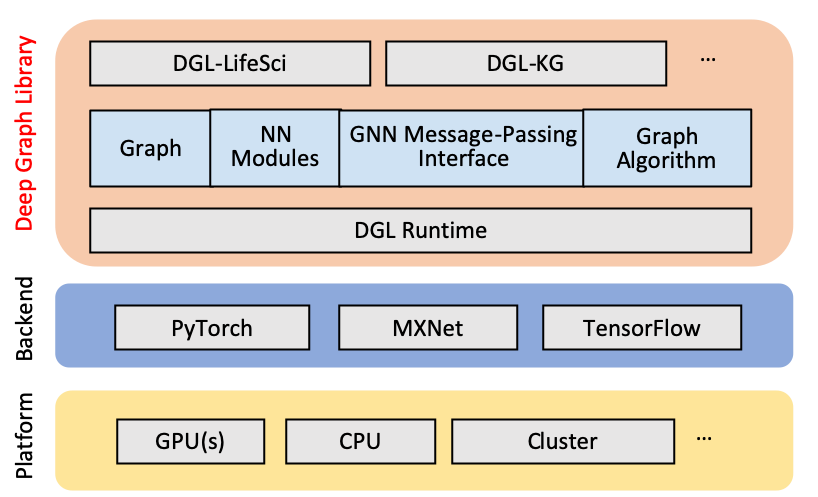
Deep Graph Library: A scalable python package for deep learning on graphs
 dgl-framework-building-graph-based-recommender-milvus.png
dgl-framework-building-graph-based-recommender-milvus.png
Deep Graph Library (DGL) is a Python package designed for building graph-based neural network models on top of existing deep learning frameworks (e.g., PyTorch, MXNet, Gluon, and more). DGL includes a user friendly backend interface, making it easy to implant in frameworks based on tensors and that support automatic generation. The PinSage algorithm mentioned above is optimized for use with DGL and PyTorch.
Milvus: An open-source vector database built for AI and similarity search
 how-does-milvus-work.png
how-does-milvus-work.png
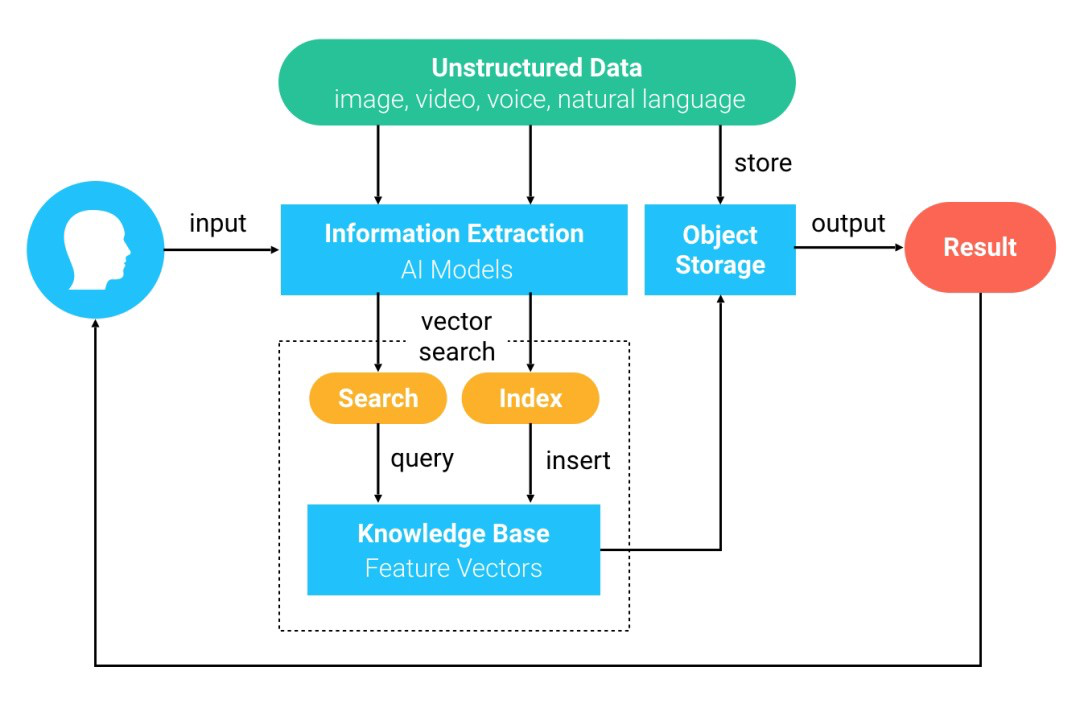
Milvus is an open-source vector database built to power vector similarity search and artificial intelligence (AI) applications. At a high level, Using Milvus for similarity search works as follows:
- Deep learning models are used to convert unstructured data to feature vectors, which are imported into Milvus.
- Milvus stores and indexes the feature vectors.
- Upon request, Milvus searches and returns vectors most similar to an input vector.
Building a graph-based recommendation system with Milvus
 beike-intelligent-house-platform-diagram.jpg
beike-intelligent-house-platform-diagram.jpg
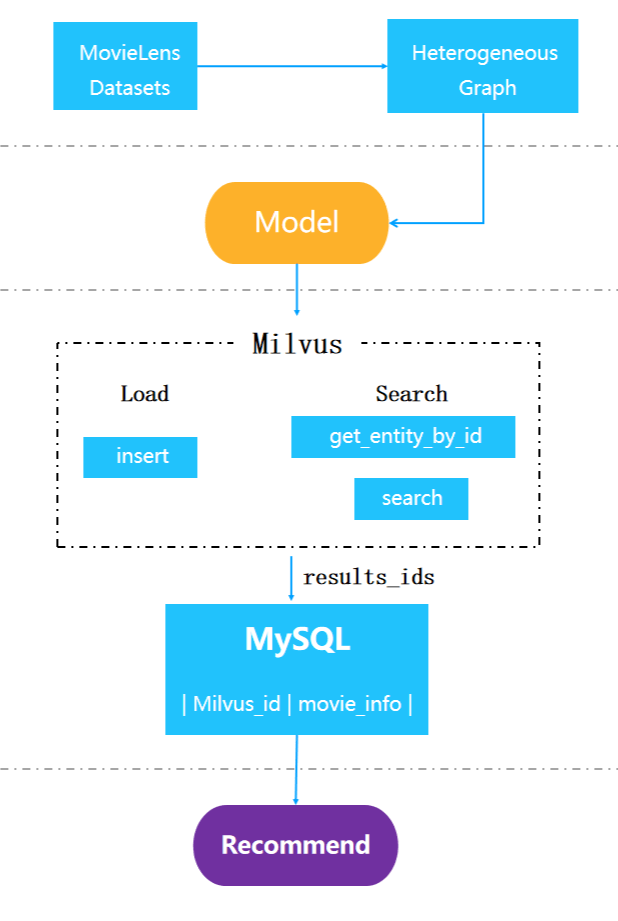 3-building-graph-based-recommender-system.png
3-building-graph-based-recommender-system.png
Building a graph-based recommendation system with Milvus involves the following steps:
Step 1: Preprocess data
Data preprocessing involves turning raw data into a more easily understandable format. This example uses the open data sets MovieLens[5] (m1–1m), which contain 1,000,000 ratings of 4,000 movies contributed by 6,000 users. This data was collected by GroupLens and includes movie descriptions, movie ratings, and user characteristics.
Note that the MovieLens datasets used in this example requires minimal data cleaning or organization. However, if you are using different datasets your mileage may vary.
To begin building a recommendation system, build a user-movie bipartite graph for classification purposes using historical user-movie data from the MovieLens dataset.
graph_builder = PandasGraphBuilder()
graph_builder.add_entities(users, 'user_id', 'user')
graph_builder.add_entities(movies_categorical, 'movie_id', 'movie')
graph_builder.add_binary_relations(ratings, 'user_id', 'movie_id', 'watched')
graph_builder.add_binary_relations(ratings, 'movie_id', 'user_id', 'watched-by')
g = graph_builder.build()
Step 2: Train model with PinSage
Embedding vectors of pins generated using the PinSage model are feature vectors of the acquired movie information. Create a PinSage model based on bipartite graph g and the customized movie feature vector dimensions (256-d by default). Then, train the model with PyTorch to obtain the h_item embeddings of 4,000 movies.
# Define the model
model = PinSAGEModel(g, item_ntype, textset, args.hidden_dims, args.num_layers).to(device)
opt = torch.optim.Adam(model.parameters(), lr=args.lr)
# Get the item embeddings
for blocks in dataloader_test:
for i in range(len(blocks)):
blocks[i] = blocks[i].to(device)
h_item_batches.append(model.get_repr(blocks))
h_item = torch.cat(h_item_batches, 0)
Step 3: Load data
Load the movie embeddings h_item generated by the PinSage model into Milvus, which will return the corresponding IDs. Import the IDs and the corresponding movie information into MySQL.
# Load data to Milvus and MySQL
status, ids = milvus.insert(milvus_table, h_item)
load_movies_to_mysql(milvus_table, ids_info)
Step 4: Conduct vector similarity search
Get the corresponding embeddings in Milvus based on the movie IDs, then use Milvus to carry run similarity search with these embeddings. Next, identify the corresponding movie information in a MySQL database.
# Get embeddings that users like
_, user_like_vectors = milvus.get_entity_by_id(milvus_table, ids)
# Get the information with similar movies
_, ids = milvus.search(param = {milvus_table, user_like_vectors, top_k})
sql = "select * from " + movies_table + " where milvus_id=" + ids + ";"
results = cursor.execute(sql).fetchall()
Step 5: Get recommendations
The system will now recommend movies most similar to user search queries. This is the general workflow for building a recommendation system. To quickly test and deploy recommender systems and other AI applications, try the Milvus bootcamp.
Milvus can power more than recommender systems
Milvus is a powerful tool capable of powering a vast array of artificial intelligence and vector similarity search applications. To learn more about the project, check out the following resources:
- How do recommendation systems work?
- Tools for building a recommender system
- Building a graph-based recommendation system with Milvus
- Milvus can power more than recommender systems
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



