Optimize Vector Databases, Enhance RAG-Driven Generative AI
This post was originally published on Intel’s Medium Channel and is reposted here with permission.
Two methods to optimize your vector database when using RAG

Photo by Ilya Pavlov on Unsplash
By Cathy Zhang and Dr. Malini Bhandaru Contributors: Lin Yang and Changyan Liu
Generative AI (GenAI) models, which are seeing exponential adoption in our daily lives, are being improved by retrieval-augmented generation (RAG), a technique used to enhance response accuracy and reliability by fetching facts from external sources. RAG helps a regular large language model (LLM) understand context and reduce hallucinations by leveraging a giant database of unstructured data stored as vectors — a mathematical presentation that helps capture context and relationships between data.
RAG helps to retrieve more contextual information and thus generate better responses, but the vector databases they rely on are getting ever larger to provide rich content to draw upon. Just as trillion-parameter LLMs are on the horizon, vector databases of billions of vectors are not far behind. As optimization engineers, we were curious to see if we could make vector databases more performant, load data faster, and create indices faster to ensure retrieval speed even as new data is added. Doing so would not only result in reduced user wait time, but also make RAG-based AI solutions a little more sustainable.
In this article, you’ll learn more about vector databases and their benchmarking frameworks, datasets to tackle different aspects, and the tools used for performance analysis — everything you need to start optimizing vector databases. We will also share our optimization achievements on two popular vector database solutions to inspire you on your optimization journey of performance and sustainability impact.
Understanding Vector Databases
Unlike traditional relational or non-relational databases where data is stored in a structured manner, a vector database contains a mathematical representation of individual data items, called a vector, constructed using an embedding or transformation function. The vector commonly represents features or semantic meanings and can be short or long. Vector databases do vector retrieval by similarity search using a distance metric (where closer means the results are more similar) such as Euclidean, dot product, or cosine similarity.
To accelerate the retrieval process, the vector data is organized using an indexing mechanism. Examples of these organization methods include flat structures, inverted file (IVF), Hierarchical Navigable Small Worlds (HNSW), and locality-sensitive hashing (LSH), among others. Each of these methods contributes to the efficiency and effectiveness of retrieving similar vectors when needed.
Let’s examine how you would use a vector database in a GenAI system. Figure 1 illustrates both the loading of data into a vector database and using it in the context of a GenAI application. When you input your prompt, it undergoes a transformation process identical to the one used to generate vectors in the database. This transformed vector prompt is then used to retrieve similar vectors from the vector database. These retrieved items essentially serve as conversational memory, furnishing contextual history for prompts, akin to how LLMs operate. This feature proves particularly advantageous in natural language processing, computer vision, recommendation systems, and other domains requiring semantic comprehension and data matching. Your initial prompt is subsequently “merged” with the retrieved elements, supplying context, and assisting the LLM in formulating responses based on the provided context rather than solely relying on its original training data.
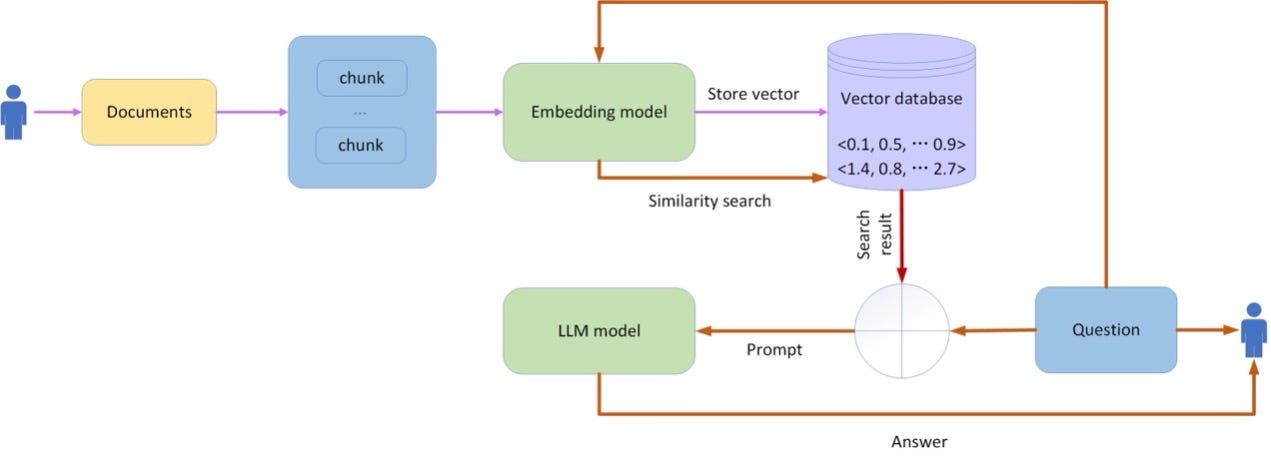
Figure 1. A RAG application architecture.
Vectors are stored and indexed for speedy retrieval. Vector databases come in two main flavors, traditional databases that have been extended to store vectors, and purpose-built vector databases. Some examples of traditional databases that provide vector support are Redis, pgvector, Elasticsearch, and OpenSearch. Examples of purpose-built vector databases include proprietary solutions Zilliz and Pinecone, and open source projects Milvus, Weaviate, Qdrant, Faiss, and Chroma. You can learn more about vector databases on GitHub via LangChain and OpenAI Cookbook.
We’ll take a closer look at one from each category, Milvus and Redis.
Improving Performance
Before diving into the optimizations, let’s review how vector databases are evaluated, some evaluation frameworks, and available performance analysis tools.
Performance Metrics
Let’s look at key metrics that can help you measure vector database performance.
- Load latency measures the time required to load data into the vector database’s memory and build an index. An index is a data structure used to efficiently organize and retrieve vector data based on its similarity or distance. Types of in-memory indices include flat index, IVF_FLAT, IVF_PQ, HNSW, scalable nearest neighbors (ScaNN),and DiskANN.
- Recall is the proportion of true matches, or relevant items, found in the Top K results retrieved by the search algorithm. Higher recall values indicate better retrieval of relevant items.
- Queries per second (QPS) is the rate at which the vector database can process incoming queries. Higher QPS values imply better query processing capability and system throughput.
Benchmarking Frameworks
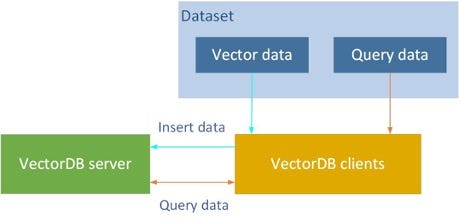
Figure 2. The vector database benchmarking framework.
Benchmarking a vector database requires a vector database server and clients. In our performance tests, we used two popular open source tools.
- VectorDBBench: Developed and open sourced by Zilliz, VectorDBBench helps test different vector databases with different index types and provides a convenient web interface.
- vector-db-benchmark: Developed and open sourced by Qdrant, vector-db-benchmark helps test several typical vector databases for the HNSW index type. It runs tests through the command line and provides a Docker Compose __file to simplify starting server components.

Figure 3. An example vector-db-benchmark command used to run the benchmark test.
But the benchmark framework is only part of the equation. We need data that exercises different aspects of the vector database solution itself, such as its ability to handle large volumes of data, various vector sizes, and speed of retrieval.With that, let’s look at some available public datasets.
Open Datasets to Exercise Vector Databases
Large datasets are good candidates to test load latency and resource allocation. Some datasets have high dimensional data and are good for testing speed of computing similarity.
Datasets range from a dimension of 25 to a dimension of 2048. The LAION dataset, an open image collection, has been used for training very large visual and language deep-neural models like stable diffusion generative models. OpenAI’s dataset of 5M vectors, each with a dimension of 1536, was created by VectorDBBench by running OpenAI on raw data. Given each vector element is of type FLOAT, to save the vectors alone, approximately 29 GB (5M * 1536 * 4) of memory is needed, plus a similar amount extra to hold indices and other metadata for a total of 58 GB of memory for testing. When using the vector-db-benchmark tool, ensure adequate disk storage to save results.
To test for load latency, we needed a large collection of vectors, which deep-image-96-angular offers. To test performance of index generation and similarity computation, high dimensional vectors provide more stress. To this end we chose the 500K dataset of 1536 dimension vectors.
Performance Tools
We’ve covered ways to stress the system to identify metrics of interest, but let’s examine what’s happening at a lower level: How busy is the computing unit, memory consumption, waits on locks, and more? These provide clues to databasebehavior, particularly useful in identifying problem areas.
The Linux top utility provides system-performance information. However, the perf tool in Linux provides a deeper set of insights. To learn more, we also recommend reading Linux perf examples and the Intel top-down microarchitecture analysis method. Yet another tool is the Intel® vTune™ Profiler, which is useful when optimizing not just application but also system performance and configuration for a variety of workloads spanning HPC, cloud, IoT, media, storage, and more.
Milvus Vector Database Optimizations
Let’s walk through some examples of how we attempted to improve the performance of the Milvus vector database.
Reducing Memory Movement Overhead in Datanode Buffer Write
Milvus’s write path proxies write data into a log broker via MsgStream. The data nodes then consume the data, converting and storing it into segments. Segments will merge the newly inserted data. The merge logic allocates a new buffer to hold/move both the old data and the new data to be inserted and then returns the new buffer as old data for the next data merge. This results in the old data getting successively larger, which in turn makes data movement slower. Perf profiles showed a high overhead for this logic.

Figure 4. Merging and moving data in the vector database generates a high-performance overhead.
We changed the merge buffer logic to directly append the new data to be inserted into the old data, avoiding allocating a new buffer and moving the large old data. Perf profiles confirm that there is no overhead to this logic. The microcode metrics metric_CPU operating frequency and metric_CPU utilization indicate an improvement that is consistent with the system not having to wait for the long memory movement anymore. Load latency improved by more than 60 percent. The improvement is captured on GitHub.
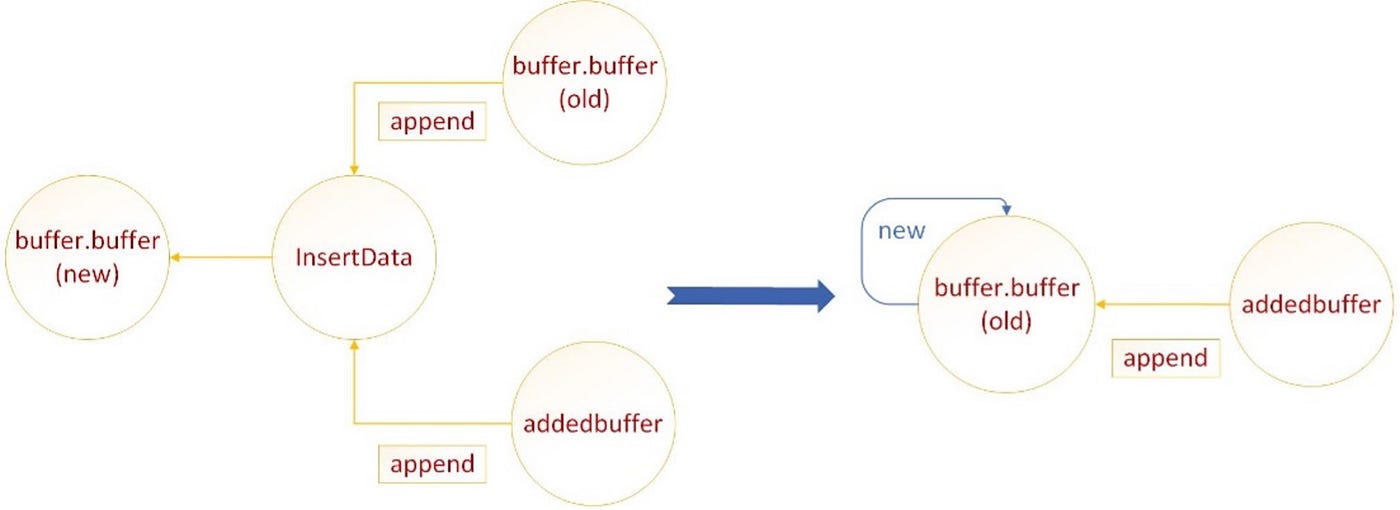
Figure 5. With less copying we see a performance improvement of more than 50 percent in load latency.
Inverted Index Building with Reduced Memory Allocation Overhead
The Milvus search engine, Knowhere, employs the Elkan k-means algorithm to train cluster data for creating inverted file (IVF) indices. Each round of data training defines an iteration count. The larger the count, the better the training results. However, it also implies that the Elkan algorithm will be called more frequently.
The Elkan algorithm handles memory allocation and deallocation each time it’s executed. Specifically, it allocates memory to store half the size of symmetric matrix data, excluding the diagonal elements. In Knowhere, the symmetric matrix dimension used by the Elkan algorithm is set to 1024, resulting in a memory size of approximately 2 MB. This means for each training round Elkan repeatedly allocates and deallocates 2 MB memory.
Perf profiling data indicated frequent large memory allocation activity. In fact, it triggered virtual memory area (VMA)allocation, physical page allocation, page map setup, and updating of memory cgroup statistics in the kernel. This pattern of large memory allocation/deallocation activity can, in some situations, also aggravate memory fragmentation. This is a significant tax.
The IndexFlatElkan structure is specifically designed and constructed to support the Elkan algorithm. Each data training process will have an IndexFlatElkan instance initialized. To mitigate the performance impact resulting from frequent memory allocation and deallocation in the Elkan algorithm, we refactored the code logic, moving the memory management outside of the Elkan algorithm function up into the construction process of IndexFlatElkan. This enables memory allocation to occur only once during the initialization phase while serving all subsequent Elkan algorithm function calls from the current data training process and helps to improve load latency by around 3 percent. Find the Knowhere patch here.
Redis Vector Search Acceleration through Software Prefetch
Redis, a popular traditional in-memory key-value data store, recently began supporting vector search. To go beyond a typical key-value store, it offers extensibility modules; the RediSearch module facilitates the storage and search of vectors directly within Redis.
For vector similarity search, Redis supports two algorithms, namely brute force and HNSW. The HNSW algorithm is specifically crafted for efficiently locating approximate nearest neighbors in high-dimensional spaces. It uses a priority queue named candidate_set to manage all vector candidates for distance computing.
Each vector candidate encompasses substantial metadata in addition to the vector data. As a result, when loading a candidate from memory it can cause data cache misses, which incur processing delays. Our optimization introduces software prefetching to proactively load the next candidate while processing the current one. This enhancement has resulted in a 2 to 3 percent throughput improvement for vector similarity searches in a single instance Redis setup. The patch is in the process of being upstreamed.
GCC Default Behavior Change to Prevent Mixed Assembly Code Penalties
To drive maximum performance, frequently used sections of code are often handwritten in assembly. However, when different segments of code are written either by different people or at different points in time, the instructions used may come from incompatible assembly instruction sets such as Intel® Advanced Vector Extensions 512 (Intel® AVX-512) and Streaming SIMD Extensions (SSE). If not compiled appropriately, the mixed code results in a performance penalty. Learn more about mixing Intel AVX and SSE instructions here.
You can easily determine if you’re using mixed-mode assembly code and have not compiled the code with VZEROUPPER, incurring the performance penalty. It can be observed through a perf command like sudo perf stat -e ‘assists.sse_avx_mix/event/event=0xc1,umask=0x10/’
The Clang compiler by default inserts VZEROUPPER, avoiding any mixed mode penalty. But the GCC compiler only inserted VZEROUPPER when the -O2 or -O3 compiler flags were specified. We contacted the GCC team and explained the issue and they now, by default, correctly handle mixed mode assembly code.
Start Optimizing Your Vector Databases
Vector databases are playing an integral role in GenAI, and they are growing ever larger to generate higher-quality responses. With respect to optimization, AI applications are no different from other software applications in that they reveal their secrets when one employs standard performance analysis tools along with benchmark frameworks and stress input.
Using these tools, we uncovered performance traps pertaining to unnecessary memory allocation, failing to prefetch instructions, and using incorrect compiler options. Based on our findings, we upstreamed enhancements to Milvus, Knowhere, Redis, and the GCC compiler to help make AI a little more performant and sustainable. Vector databases are an important class of applications worthy of your optimization efforts. We hope this article helps you get started.
- Understanding Vector Databases
- Improving Performance
- Milvus Vector Database Optimizations
- Redis Vector Search Acceleration through Software Prefetch
- GCC Default Behavior Change to Prevent Mixed Assembly Code Penalties
- Start Optimizing Your Vector Databases
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



