Building a Search by Image Shopping Experience with VOVA and Milvus
Jump to:
- Building a Search by Image Shopping Experience with VOVA and Milvus
- How does image search work? - System process of VOVA’s search by image functionality.
- Target detection using the YOLO model - YOLO network architecture.
- Image feature vector extraction with ResNet - ResNet structure.
- Vector similarity search powered by Milvus - Mishards architecture in Milvus.
- VOVA’s shop by image tool - Screenshots of VOVA’s search by image shopping tool.
- Reference
Online shopping surged in 2020, up 44% in large part due to the coronavirus pandemic. As people sought to socially distance and avoid contact with strangers, no-contact delivery became an incredibly desirable option for many consumers. This popularity has also led to people buying a greater variety of goods online, including niche items that can be hard to describe using a traditional keyword search.
To help users overcome the limitations of keyword-based queries, companies can build image search engines that allow users to use images instead of words for search. Not only does this allow users to find items that are difficult to describe, but it also helps them shop for things they encounter in real life. This functionality helps build a unique user experience and offers general convenience that customers appreciate.
VOVA is an emerging e-commerce platform that focuses on affordability and offering a positive shopping experience to its users, with listings covering millions of products and support for 20 languages and 35 major currencies. To enhance the shopping experience for its users, the company used Milvus to build image search functionality into its e-commerce platform. The article explores how VOVA successfully built an image search engine with Milvus.
How does image search work?
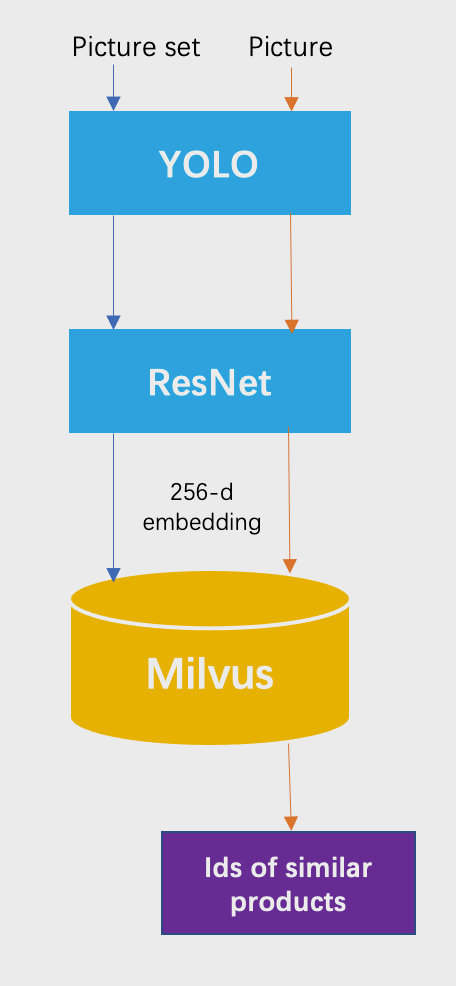
VOVA’s shop by image system searches the company’s inventory for product images that are similar to user uploads. The following chart shows the two stages of the system process, the data import stage (blue) and the query stage (orange):
- Use the YOLO model to detect targets from uploaded photos;
- Use ResNet to extract feature vectors from the detected targets;
- Use Milvus for vector similarity search.
 Vova-1.png
Vova-1.png
Target detection using the YOLO model
VOVA’s mobile apps on Android and iOS currently support image search. The company uses a state-of-the-art, real-time object detection system called YOLO (You only look once) to detect objects in user uploaded images. The YOLO model is currently in its fifth iteration.
YOLO is a one-stage model, using only one convolutional neural network (CNN) to predict categories and positions of different targets. It is small, compact, and well suited for mobile use.
YOLO uses convolutional layers to extract features and fully-connected layers to obtain predicted values. Drawing inspiration from the GooLeNet model, YOLO’s CNN includes 24 convolutional layers and two fully-connected layers.
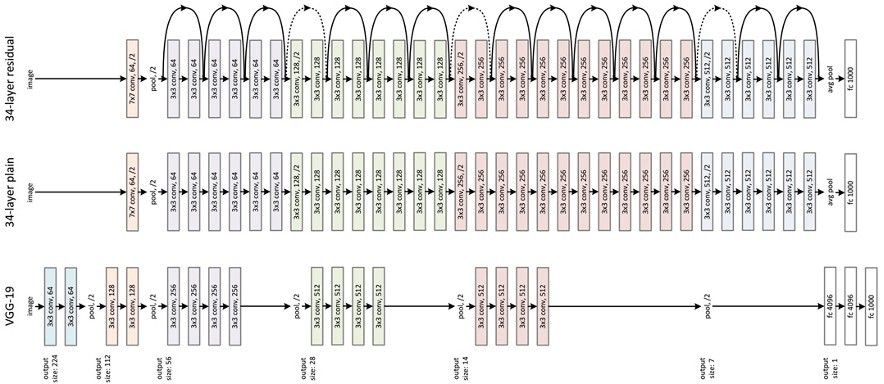
As the following illustration shows, a 448 × 448 input image is converted by a number of convolutional layers and pooling layers to a 7 × 7 × 1024-dimensional tensor (depicted in the third to last cube below), and then converted by two fully-connected layers to a 7 × 7 × 30-dimensional tensor output.
The predicted output of YOLO P is a two-dimensional tensor, whose shape is [batch,7 ×7 ×30]. Using slicing, P[:,0:7×7×20] is the category probability, P[:,7×7×20:7×7×(20+2)] is the confidence, and P[:,7×7×(20+2)]:] is the predicted result of the bounding box.

Image feature vector extraction with ResNet
VOVA adopted the residual neural network (ResNet) model to extract feature vectors from an extensive product image library and user uploaded photos. ResNet is limited because as the depth of a learning network increases, the accuracy of the network decreases. The image below depicts ResNet running the VGG19 model (a variant of the VGG model) modified to include a residual unit through the short circuit mechanism. VGG was proposed in 2014 and includes just 14 layers, while ResNet came out a year later and can have up to 152.
The ResNet structure is easy to modify and scale. By changing the number of channels in the block and the number of stacked blocks, the width and depth of the network can be easily adjusted to obtain networks with different expressive capabilities. This effectively solves the network degeneration effect, where accuracy declines as the depth of learning increases. With sufficient training data, a model with improving expressive performance can be obtained while gradually deepening the network. Through model training, features are extracted for each picture and converted to 256-dimensional floating point vectors.
 vova-3.png
vova-3.png
Vector similarity search powered by Milvus
VOVA’s product image database includes 30 million pictures and is growing rapidly. To quickly retrieve the most similar product images from this massive dataset, Milvus is used to conduct vector similarity search. Thanks to a number of optimizations, Milvus offers a fast and streamlined approach to managing vector data and building machine learning applications. Milvus offers integration with popular index libraries (e.g., Faiss, Annoy), supports multiple index types and distance metrics, has SDKs in multiple languages, and provides rich APIs for managing vector data.
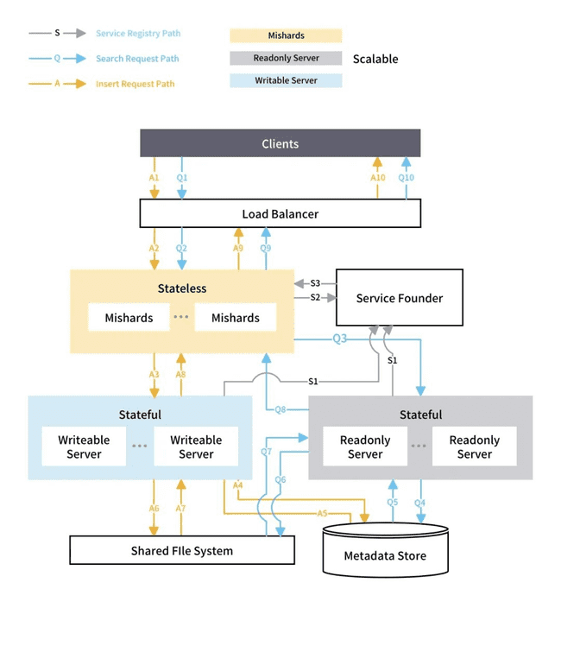
Milvus can conduct similarity search on trillion-vector datasets in milliseconds, with a query time under 1.5 seconds when nq=1 and an average batch query time under 0.08 seconds. To build its image search engine, VOVA referred to the design of Mishards, Milvus’ sharding middleware solution (see the chart below for its system design), to implement a highly available server cluster. By leveraging the horizontal scalability of a Milvus cluster, the project requirement for high query performance on massive datasets was met.
 vova-4.png
vova-4.png
VOVA’s shop by image tool
The screenshots below show the VOVA search by image shopping tool on the company’s Android app.
 vova-5.png
vova-5.png
As more users search for products and upload photos, VOVA will continue to optimize the models that power the system. Additionally, the company will incorporate new Milvus functionality that can further enhance the online shopping experience of its users.
Reference
YOLO:
https://arxiv.org/pdf/1506.02640.pdf
https://arxiv.org/pdf/1612.08242.pdf
ResNet:
https://arxiv.org/abs/1512.03385
Milvus:
https://milvus.io/docs
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



