Milvusとは?
Milvusについて知るために必要なすべての情報を10分以内で提供します。
ベクトル埋め込みとは?
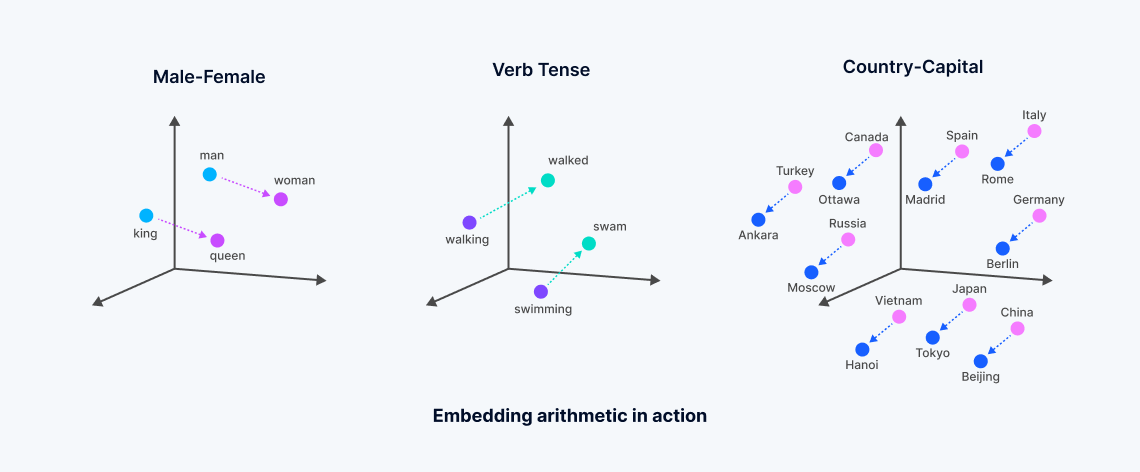
ベクトル埋め込みは、機械学習モデルから派生した数値表現で、非構造化データの意味をカプセル化します。これらの埋め込みは、ニューラルネットワークやトランスフォーマーアーキテクチャによるデータ内の複雑な相関関係の分析を通じて生成され、各ポイントがドキュメント内の単語などのデータオブジェクトの「意味」に対応する密なベクトル空間を作成します。
このプロセスは、テキストや他の非構造化データを、意味的な類似性を反映するベクトルに変換します。意味の関連する単語は、この多次元空間でより近くに配置され、「密ベクトル検索」と呼ばれる検索タイプを容易にします。これは、正確な一致に依存する伝統的なキーワード検索とは対照的であり、疎ベクトルを使用します。ベクトル埋め込みの開発(しばしば主要なテクノロジー企業によって広範にトレーニングされた基礎モデルから派生)は、データの本質を捉えるよりニュアンスのある検索を可能にし、語彙的または疎ベクトル検索方法の制限を超えます。
ベクトル埋め込みを何に使用できますか?
ベクトル埋め込みは、さまざまなアプリケーションで効率と正確性を向上させるために活用できます。以下は最も頻繁なユースケースのいくつかです:
類似した画像、動画、音声ファイルの検索
ベクトル埋め込みを使用すると、畳み込みニューラルネットワーク(CNN)を使用して画像、ビデオフレーム、音声セグメントを分析し、キーワードだけでなくコンテンツに基づいて類似したマルチメディアコンテンツを検索できます。これにより、音声のヒントに基づいて画像を見つけたり、画像クエリを通じてビデオを見つけたりするような高度な検索が可能になります。
薬品発見の加速
製薬業界では、ベクトル埋め込みを使用して化合物の化学構造を符号化し、ターゲットタンパク質との類似性を測定して有望な薬物候補を特定することができます。これにより、薬物発見プロセスが加速され、最も有望なリードに集中することで時間とリソースが節約されます。
セマンティック検索による検索の関連性向上
内部ドキュメントをベクトルに埋め込むことで、組織はセマンティック検索を活用して検索結果の関連性を向上させることができます。この方法は、Retrieval Augmented Generation(RAG)の概念を使用してクエリの意図を理解し、ChatGPTのようなAIモデルを通じて会社のデータから回答を提供することで、関連性のない結果とAIの幻覚を減少します。
推奨システム
ベクトル埋め込みは、ユーザーとアイテムを埋め込みとして表現して類似性を測定することで、推奨システムを革新します。このアプローチにより、個々の好みに基づいたパーソナライズされた推奨が可能になり、オンラインプラットフォームでのユーザー満足度とエンゲージメントが向上します。
異常検出
詐欺検出、ネットワークセキュリティ、産業監視などの分野では、ベクトル埋め込みが異常パターンの特定に不可欠です。埋め込みとして表現されたデータポイントを使用して、距離や不似合いを計算することで異常を検出し、潜在的な問題に対する早期の特定と予防策を可能にします。
ベクターデータベースとは?
ベクトルデータベースは、画像、音声、ビデオ、テキストコンテンツなどのデータアイテムの本質を捉えるベクトル埋め込みと数値表現を通じて非構造化データを管理および取得するために設計された特殊なシステムです。伝統的なリレーショナルデータベースが、正確な検索操作を使用して構造化データを処理するのとは異なり、ベクトルデータベースは意味的な類似性検索に優れています。これにより、推奨システム、チャットボット、マルチメディアコンテンツ検索ツールなど、さまざまなドメインのアプリケーションの開発が可能になり、ChatGPTなどのAIと大規模言語モデルが提示する課題に対処します。
Milvusのようなベクトルデータベースの登場は、広範な非構造化データを対象としたコンテンツベースの検索を可能にし、人間が生成したラベルの制約を超えて業界を変革しています。ベクトルデータベースを他のデータベースと区別するキー機能には、
成長するデータ量を処理するためのスケーラビリティと調整可能性
効率的なリソース使用とプライバシーのためのマルチテナンシーとデータ分離
多様なプログラミング言語のための包括的なAPIスイート
複雑なデータとの対話を簡素化するユーザーフレンドリーなインターフェース
これらの属性により、ベクトルデータベースは現代のアプリケーションの要件を満たし、伝統的なデータベースでは不可能な方法で非構造化データを探索して活用するための強力なツールを提供します。
ベクトルデータベース vs. ベクトル検索ライブラリ
FAISS、ScaNN、HNSWなどのベクトル検索ライブラリは、効率的な類似性検索と密ベクトルクラスタリングを実行できるプロトタイプシステムを構築するための基礎ツールを提供します。これらのライブラリは強力でオープンソースであり、ベクトル取得のために主に設計されており、大規模なベクトルコレクションの処理や評価とパラメータ調整のためのインターフェースを提供するなどの機能を提供します。ただし、スケーラビリティ、マルチテナンシー、動的データ変更の点で不足しており、より大規模で複雑なデータセットや成長するユーザーベースには不向きです。
一方、ベクトルデータベースは、数十億のベクトルのストレージとリアルタイム取得をサポートするために設計された、より包括的なソリューションとして登場します。これらは、ベクトル検索ライブラリの基本機能を超える高い抽象化レベル、スケーラビリティ、クラウドネイティブ性、ユーザーフレンドリーな機能を提供します。FAISSのようなライブラリは、ベクトルデータベースが構築できる重要なコンポーネントですが、後者はデータ挿入と管理の操作を簡素化する完全なサービスであり、非構造化データ処理の大規模で動的なアプリケーションの要件により適合しています。
ベクトルデータベース vs. 伝統的なデータベースのベクトル検索プラグイン
ベクトルデータベースと伝統的なデータベースのベクトル検索プラグインは、ベクトルベースの検索を処理する際に異なる役割を果たします。Elasticsearch 8.0などのプラグインは、既存のデータベースアーキテクチャ内でベクトル検索機能を提供し、拡張機能として機能するのではなく、包括的なソリューションとして機能します。これらのプラグインには、埋め込み管理とベクトル検索に対するフルスタックアプローチが欠けており、非構造化データアプリケーションに対する制限とサブオプティマルなパフォーマンスが生じます。
調整可能性とユーザーフレンドリーなAPI/SDKなどのキー機能は、ベクトル検索プラグインに著しく欠けています。たとえば、ElasticsearchのANNエンジンは基本的なベクトルストレージとクエリをサポートしていますが、インデックスアルゴリズムと距離メトリックのオプションに制限されており、Milvusのような専用ベクトルデータベースと比較して柔軟性が低いです。Milvusは、より直感的なAPI、広範なインデックス方法と距離メトリックのサポート、およびSQLのようなクエリの可能性を提供し、非構造化データの管理とクエリにおいて優れています。この根本的な違いは、ベクトル埋め込みの最適な検索と管理を実現するために、非構造化データに最適化された包括的な機能セットとアーキテクチャを持つベクトルデータベースがベクトル検索プラグインに優れている理由を説明しています。
Milvusは他のベクトルデータベースとどのように異なりますか?
Milvusは、検索体験を加速し統合するために設計されたスケーラブルなアーキテクチャと多様な機能を備えたベクトルデータベースとして際立っています。主要な機能のハイライトは次のとおりです:
スケーラブルでエラスティックなアーキテクチャ
Milvusは、現代のアプリケーションの動的な要件に対応するために、例外的なスケーラビリティとエラスティックを実現するために設計されています。これは、サービス指向の設計を通じて、ストレージ、コーディネーター、ワーカーをデカップリングし、コンポーネントごとにスケーリングすることで実現されます。このモジュール方式により、異なる計算タスクが異なるワークロードに応じて独立してスケーリングでき、細かいリソース割り当てと分離が可能になります。
多様なインデックスサポート
Milvusは、HNSW、IVF、製品量子化、GPUベースのインデックスなど、10種類以上のインデックスタイプをサポートしています。この多様性により、開発者は特定のパフォーマンスと正確性の要件に応じて検索を最適化し、データ特性の広範なアプリケーションに適応できるデータベースを確保できます。GPUインデックスなどのインデックス提供の継続的な拡大により、Milvusの適応性と複雑な検索タスクの処理能力がさらに向上します。
多様な検索機能
Milvusは、トップK近似最近傍(ANN)、範囲ANN、メタデータフィルタリング付きの検索、および今後のハイブリッド密/疎ベクトル検索を含む、さまざまな検索タイプを提供します。この多様性により、比類のないクエリの柔軟性と精度が実現され、開発者は特定のアプリケーション要件に応じてデータ取得戦略をカスタマイズし、検索結果の関連性と効率の両方を最適化できます。
調整可能な整合性
Milvusは、デルタ整合性モデルを提供し、ユーザーがクエリデータの「古さの許容度」を指定できるようにし、クエリパフォーマンスとデータの新しさの間の調整されたバランスを実現します。この柔軟性は、最新の結果を必要とするアプリケーションにとって重要であり、応答時間を犠牲にすることなく、アプリケーションの要件に応じて強力な整合性と最終的な整合性の両方をサポートします。
ハードウェアアクセラレーションコンピュートサポート
Milvusは、AVX512やNeonなどのSIMD実行のためのハードウェア機能を活用するように設計されており、量子化、キャッシュ認識の最適化、およびGPUサポートを伴います。このアプローチにより、特定のハードウェアの強みを効率的に活用し、迅速な処理とコスト効率の良いスケーラビリティを実現します。異なるアプリケーションのユニークな要件に応じてリソース使用を最適化することで、Milvusはベクトルデータの管理と検索操作の速度と効率を向上させます。
Milvusはどのように機能するのですか?
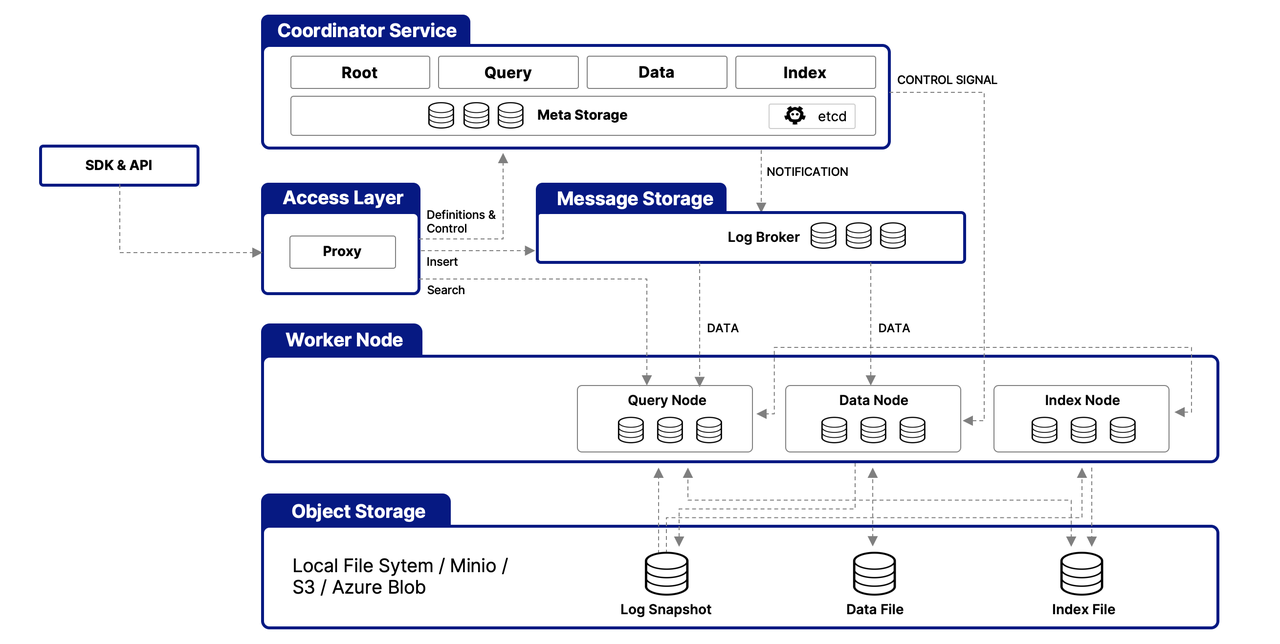
Milvusは、ベクトルデータを効率的に処理し、スケーラビリティ、調整可能性、データ分離を確保するために設計された多層アーキテクチャを中心に構築されています。以下はそのアーキテクチャの簡略化された概要です:
アクセス層
この層は、外部リクエストの最初の接点として機能し、ステートレスプロキシを使用してクライアント接続管理、静的検証、動的チェックを行います。これらのプロキシは、負荷分散も処理し、Milvusの包括的なAPIスイートの実装に不可欠です。ダウンストリームサービスがリクエストを処理した後、アクセス層は応答をユーザーにルーティングします。
コーディネーターサービス
中央コマンドとして機能し、負荷分散とデータ管理を4つのコーディネーターを通じて調整します。これにより、データ、クエリ、インデックスの効率的な管理が可能になります。
The Root Coordinator: managing data-related tasks and global timestamps
The Query Coordinator: overseeing query nodes for search operations
The Data Coordinator: handling data nodes and metadata
The Index Coordinator: maintaining index nodes and metadata
ワーカーノード
実際のタスクの実行を担当し、スケーラブルなポッドでコーディネーターからのコマンドを実行します。これにより、Milvusは変化するデータ、クエリ、インデックスの要件に動的に対応し、システムのスケーラビリティと調整可能性をサポートします。
オブジェクトストレージ層
データ永続化のための基盤であり、以下の要素で構成されています。
Meta store: using etcd for metadata snapshots and system health checks
Log broker: for streaming data persistence and recovery, utilizing Pulsar or RocksDB
Object storage: storing log snapshots, index files, and query results, with support for services like AWS S3, Azure Blob Storage, and MinIO
これからどこへ行きますか?
- To get hands-on experience with Milvus, follow the get started guide.
- To understand Milvus in more detail, read the Documentation.
- Browse through the Use Cases to learn how other users in our worldwide community are getting value from Milvus.
Join a local Unstructured Data meetup and our Discord.