Conversational Memory in LangChain

LangChain is a robust framework for building LLM applications. However, with that power comes quite a bit of complexity. LangChain provides many ways to prompt an LLM and essential features like conversational memory. Conversational memory offers context for the LLM to remember your chat.
In this post, we look at how to use conversational memory with LangChain and Milvus. To follow along, you need to pip install four libraries and an OpenAI API key. The four libraries you need can be installed by running pip install langchain milvus pymilvus python-dotenv. Or executing the first block in the CoLab Notebook for this article.
In this post, we’ll learn about:
- Conversational Memory with LangChain
- Setting Up Conversation Context
- Prompting the Conversational Memory with LangChain
- LangChain Conversational Memory Summary
Conversational Memory with LangChain
In the default state, you interact with an LLM through single prompts. Adding memory for context, or “conversational memory” means you no longer have to send everything through one prompt. LangChain offers the ability to store the conversation you’ve already had with an LLM to retrieve that information later.
To set up persistent conversational memory with a vector store, we need six modules from LangChain. First, we must get the OpenAIEmbeddings and the OpenAI LLM. We also need VectorStoreRetrieverMemory and the LangChain version of Milvus to use a vector store backend. Then we need ConversationChain and PromptTemplate to save our conversation and query it.
The os, dotenv, and openai libraries are mainly for operational purposes. We use them to load and use the OpenAI API key. The final setup step is to spin up a local Milvus Lite instance. We do this through using the default_server from the Milvus Python package.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.memory import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate
from langchain.vectorstores import Milvus
embeddings = OpenAIEmbeddings()
import os
from dotenv import load_dotenv
import openai
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
from milvus import default_server
default_server.start()
Setting Up Conversation Context
Now that we have all our prerequisites set up, we can proceed to create our conversational memory. Our first step is to create a connection to the Milvus server using LangChain. Next, we use an empty dictionary to create our LangChain Milvus collection. In addition, we pass in the embeddings we created above and the connection details for the Milvus Lite server.
To use the vector database for conversational memory, we need to instantiate it as a retriever. We only retrieve the top 1 result for this case, setting k=1. The last conversational memory setup step is using the VectorStoreRetrieverMemory object as our conversational memory through the retriever and vector database connection we just set up.
To use our conversational memory, it has to have some context in it. So let’s give the memory some context. For this example, we give five pieces of information. Let’s store my favorite snack (chocolate), sport (swimming), beer (Guinness), dessert (cheesecake), and musician (Taylor Swift). Each entry is saved to the memory through the save_context function.
vectordb = Milvus.from_documents(
{},
embeddings,
connection_args={"host": "127.0.0.1", "port": default_server.listen_port})
retriever = Milvus.as_retriever(vectordb, search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever)
about_me = [
{"input": "My favorite snack is chocolate",
"output": "Nice"},
{"input": "My favorite sport is swimming",
"output": "Cool"},
{"input": "My favorite beer is Guinness",
"output": "Great"},
{"input": "My favorite dessert is cheesecake",
"output": "Good to know"},
{"input": "My favorite musician is Taylor Swift",
"output": "Same"}
]
for example in about_me:
memory.save_context({"input": example["input"]}, {"output": example["output"]})
Prompting the Conversational Memory with LangChain
It’s time to look at how we can use our conversational memory. Let’s start by connecting to the OpenAI LLM through LangChain. We use a temperature of 0 to indicate that we don’t want our LLM to be creative.
Next, we create a template. We tell the LLM that it is engaged in a friendly conversation with a human and inserts two variables. The history variable provides the context from the conversational memory. The input variable provides the current input. We use the PromptTemplate object to insert these variables.
We use the ConversationChain object to combine our prompt, LLM, and memory. Now we are ready to check the memory of our conversation by giving it some prompts. We start by telling the LLM that our name is Gary, the main rival in the Pokemon series (everything else in the conversational memory is a fact about me).
llm = OpenAI(temperature=0) # Can be any valid LLM
_DEFAULT_TEMPLATE = """The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Relevant pieces of previous conversation:
{history}
(You do not need to use these pieces of information if not relevant)
Current conversation:
Human: {input}
AI:"""
PROMPT = PromptTemplate(
input_variables=["history", "input"], template=_DEFAULT_TEMPLATE
)
conversation_with_summary = ConversationChain(
llm=llm,
prompt=PROMPT,
memory=memory,
verbose=True
)
conversation_with_summary.predict(input="Hi, my name is Gary, what's up?")
The image below shows what an expected response from the LLM could look like. In this example, it has responded by saying its name is “AI”.
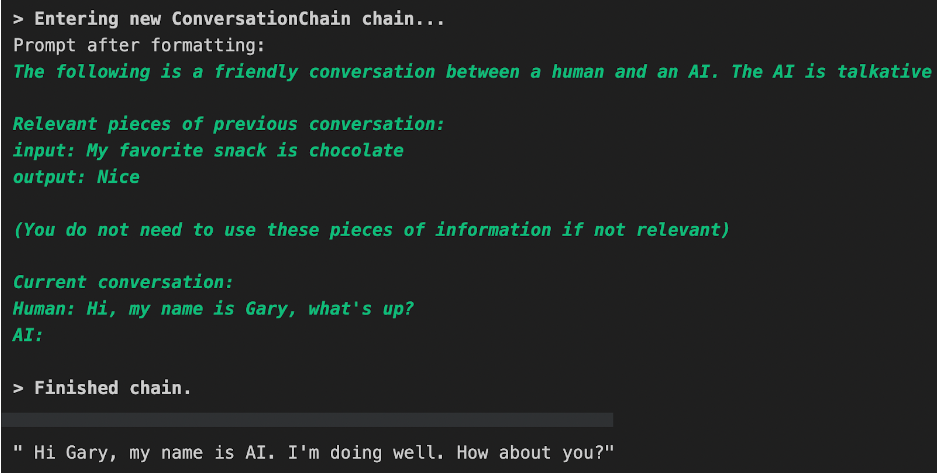
Now let’s test out the memory so far. We use the ConversationChain object we created earlier and query for my favorite musician.
conversation_with_summary.predict(input="who is my favorite musician?")
The image below shows an expected response from the Conversation Chain. Since we used the verbose option, it also shows us the relevant conversation. We can see that it returns that my favorite artist is Taylor Swift, as expected.
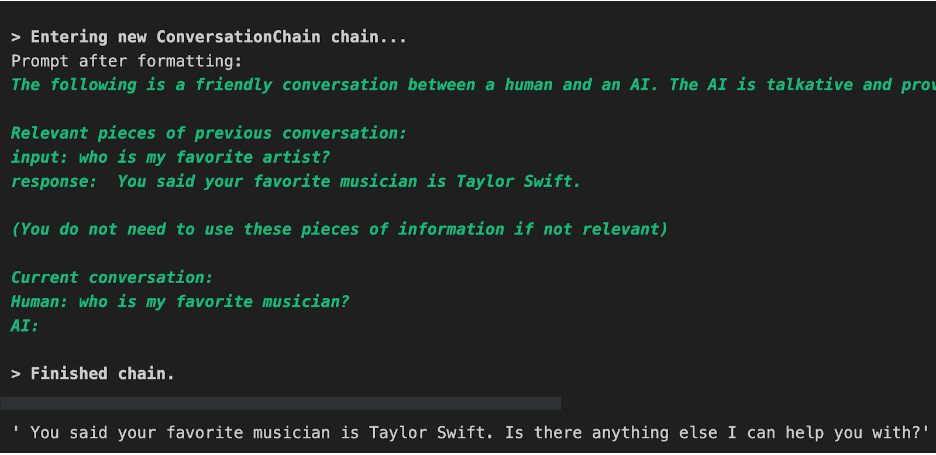
Next, let’s check for my favorite dessert - cheesecake.
conversation_with_summary.predict(input="Whats my favorite dessert?")
When we query for my favorite dessert, we can see that the Conversation Chain once again picks the correct information from Milvus. It finds that my favorite dessert is cheesecake, as I told it earlier.
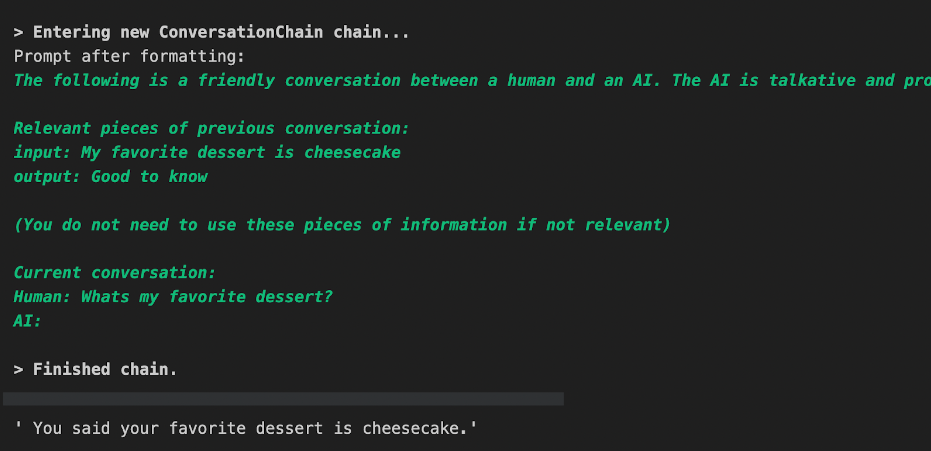
Now that we’ve confirmed that we can query for the information we gave earlier, let’s check for one more thing - the information we provided at the beginning of our conversation. We started our conversation by telling the AI that our name was Gary.
conversation_with_summary.predict(input="What's my name?")
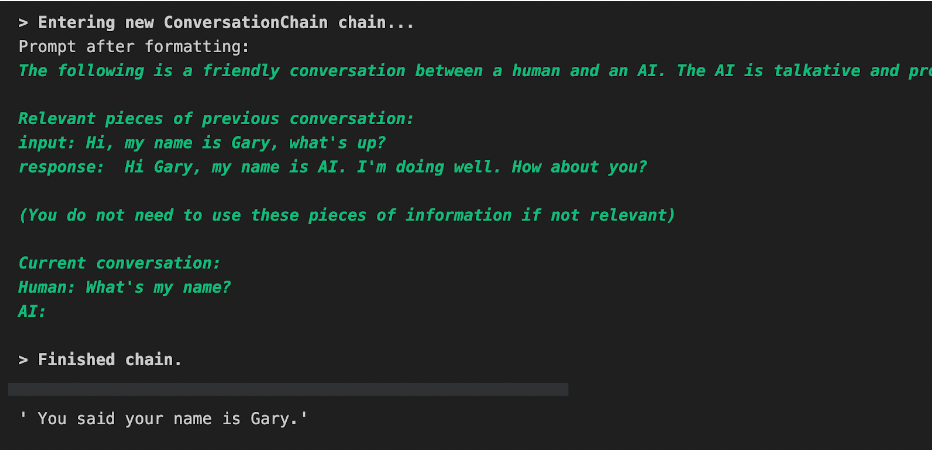
Our final check yields that the conversation chain stored the bit about our name in our vector store conversational memory. It returns that we said our name is Gary.
LangChain Conversational Memory Summary
In this tutorial, we learned how to use conversational memory in LangChain. LangChain offers access to vector store backends like Milvus for persistent conversational memory. We can use conversational memory by injecting history into our prompts and saving historical context in the ConversationChain object.
For this example tutorial, we gave the Conversation Chain five facts about me and pretended to be the main rival in Pokemon, Gary. Then, we pinged the Conversation Chain with questions about the a priori knowledge we stored - my favorite musician and dessert. It answered both of these questions correctly and surfaced the relevant entries. Finally, we asked it about our name as given at the beginning of the conversation, and it correctly returned that we said our name was “Gary.”
- Conversational Memory with LangChain
- Setting Up Conversation Context
- Prompting the Conversational Memory with LangChain
- LangChain Conversational Memory Summary
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



