Processing Technologies
Sound is an information dense data type. Although it may feel antiquated in the era of video content, audio remains a primary information source for many people. Despite long-term decline in listeners, 83% of Americans ages 12 or older listened to terrestrial (AM/FM) radio in a given week in 2020 (down from 89% in 2019). Conversely, online audio has seen a steady rise in listeners over the past two decades, with 62% of Americans reportedly listening to some form of it on a weekly basis according to the same Pew Research Center study.
As a wave, sound includes four properties: frequency, amplitude, wave form, and duration. In musical terminology, these are called pitch, dynamic, tone, and duration. Sounds also help humans and other animals perceive and understand our environment, providing context clues for the location and movement of objects in our surroundings.
As an information carrier, audio can be classified into three categories:
- Speech: A communication medium composed of words and grammar. With speech recognition algorithms, speech can be converted to text.
- Music: Vocal and/or instrumental sounds combined to produce a composition comprised of melody, harmony, rhythm, and timbre. Music can be represented by a score.
- Waveform: A digital audio signal obtained by digitizing analog sounds. Waveforms can represent speech, music, and natural or synthesized sounds.
Audio retrieval can be used to search and monitor online media in real-time to crack down on infringement of intellectual property rights. It also assumes an important role in the classification and statistical analysis of audio data.
Processing Technologies
Speech, music, and other generic sounds each have unique characteristics and demand different processing methods. Typically, audio is separated into groups that contain speech and groups that do not:
- Speech audio is processed by automatic speech recognition.
- Non-speech audio, including musical audio, sound effects, and digitized speech signals, are processed using audio retrieval systems.
This article focuses on how to use an audio retrieval system to process non-speech audio data. Speech recognition is not covered in this article
Audio feature extraction
Feature extraction is the most important technology in audio retrieval systems as it enables audio similarity search. Methods for extracting audio features are divided into two categories:
- Traditional audio feature extraction models such as Gaussian mixture models (GMMs) and hidden Markov models (HMMs);
- Deep learning-based audio feature extraction models such as recurrent neural networks (RNNs), long short-term memory (LSTM) networks, encoding-decoding frameworks, attention mechanisms, etc.
Deep learning-based models have an error rate that is an order of magnitude lower than traditional models, and therefore are gaining momentum as core technology in the field of audio signal processing.
Audio data is usually represented by the extracted audio features. The retrieval process searches and compares these features and attributes rather than the audio data itself. Therefore, the effectiveness of audio similarity retrieval largely depends on the feature extraction quality.
In this article, large-scale pre-trained audio neural networks for audio pattern recognition (PANNs) are used to extract feature vectors for its mean average accuracy (mAP) of 0.439 (Hershey et al., 2017).
After extracting the feature vectors of the audio data, we can implement high-performance feature vector analysis using Milvus.
Vector similarity search
Milvus is a cloud-native, open-source vector database built to manage embedding vectors generated by machine learning models and neural networks. It is widely used in scenarios such as computer vision, natural language processing, computational chemistry, personalized recommender systems, and more.
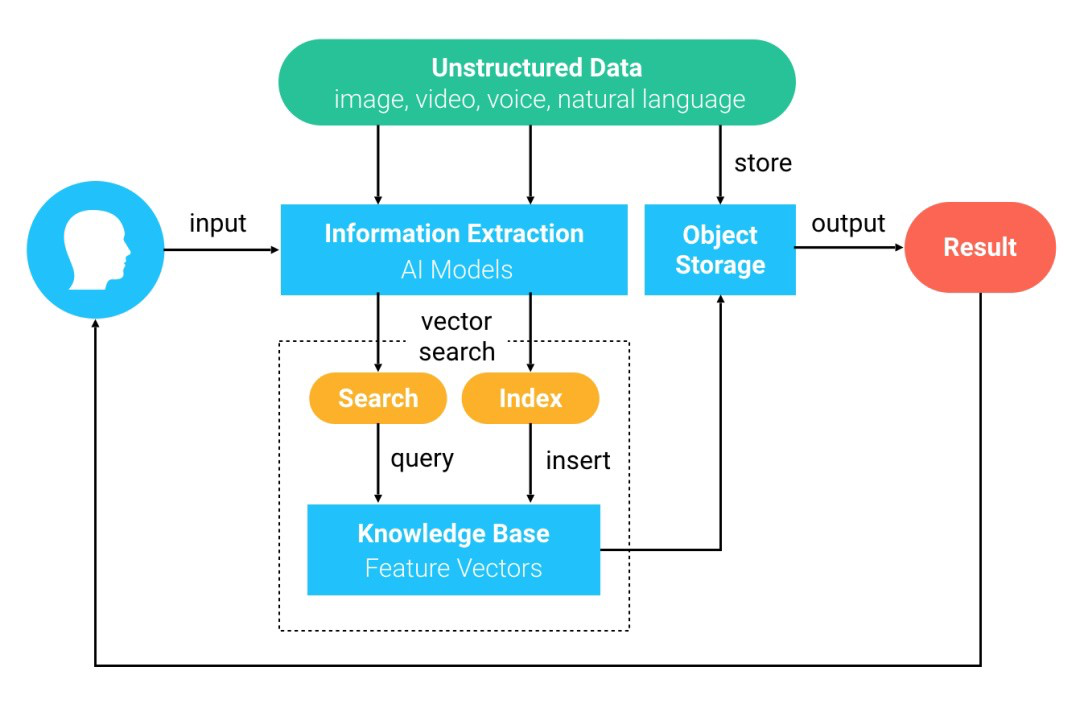
The following diagram depicts the general similarity search process using Milvus:
 how-does-milvus-work.png
how-does-milvus-work.png
- Unstructured data are converted to feature vectors by deep learning models and inserted into Milvus.
- Milvus stores and indexes these feature vectors.
- Upon request, Milvus searches and returns vectors most similar to the query vector.
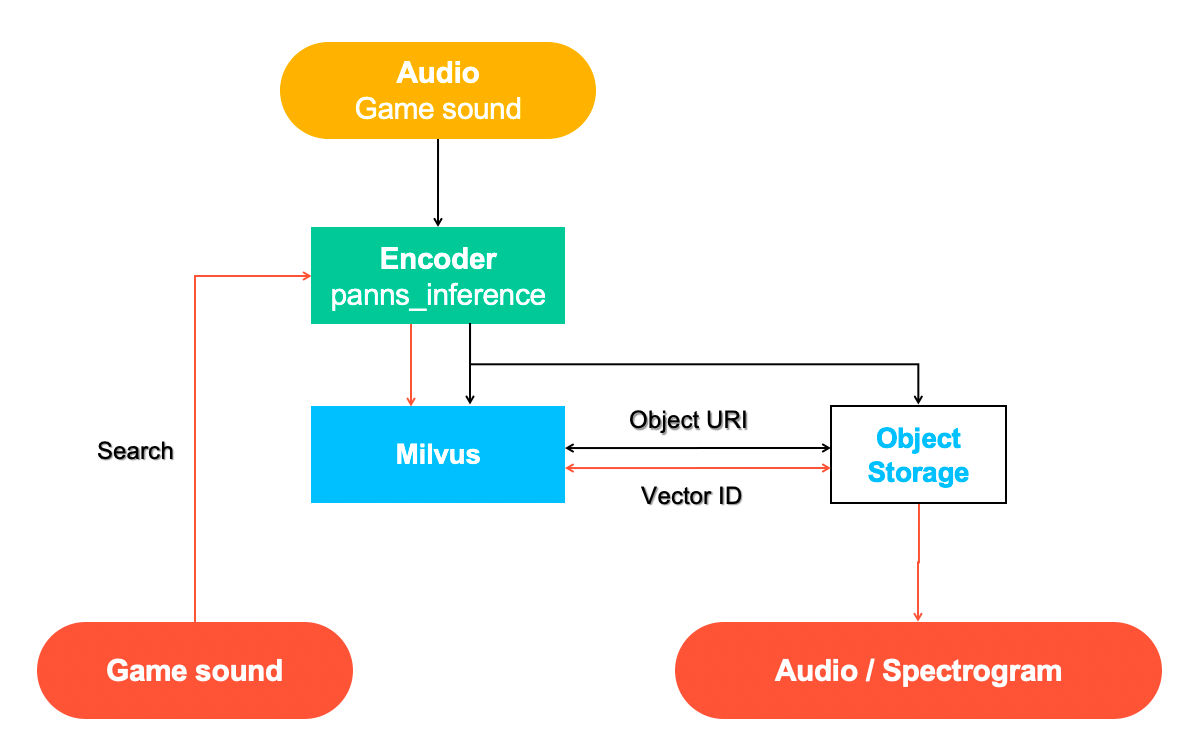
System overview
The audio retrieval system mainly consists of two parts: insert (black line) and search(red line).
 audio-retrieval-system.png
audio-retrieval-system.png
The sample dataset used in this project contains open-source game sounds, and the code is detailed in the Milvus bootcamp.
Step 1: Insert data
Below is the example code for generating audio embeddings with the pre-trained PANNs-inference model and inserting them into Milvus, which assigns a unique ID to each vector embedding.
1 wav_name, vectors_audio = get_audio_embedding(audio_path)
2 if vectors_audio:
3 embeddings.append(vectors_audio)
4 wav_names.append(wav_name)
5 ids_milvus = insert_vectors(milvus_client, table_name, embeddings)
6
Then the returned ids_milvus are stored along with other relevant information (e.g. wav_name) for the audio data held in a MySQL database for subsequent processing.
1 get_ids_correlation(ids_milvus, wav_name)
2 load_data_to_mysql(conn, cursor, table_name)
3
Step 2: Audio search
Milvus calculates the inner product distance between the pre-stored feature vectors and the input feature vectors, extracted from the query audio data using the PANNs-inference model, and returns the ids_milvus of similar feature vectors, which correspond to the audio data searched.
1 _, vectors_audio = get_audio_embedding(audio_filename)
2 results = search_vectors(milvus_client, table_name, [vectors_audio], METRIC_TYPE, TOP_K)
3 ids_milvus = [x.id for x in results[0]]
4 audio_name = search_by_milvus_ids(conn, cursor, ids_milvus, table_name)
5
API reference and demo
API
This audio retrieval system is built with open-source code. Its main features are audio data insertion and deletion. All APIs can be viewed by typing 127.0.0.1:
Demo
We host a live demo of the Milvus-based audio retrieval system online that you can try out with your own audio data.
 audio-search-demo.png
audio-search-demo.png
Conclusion
Living in the era of big data, people find their lives abound with all sorts of information. To make better sense of it, traditional text retrieval no long cuts it. Today’s information retrieval technology is in urgent need of the retrieval of various unstructured data types, such as videos, images, and audio.
Unstructured data, which is difficult for computers to process, can be converted into feature vectors using deep learning models. This converted data can easily be processed by machines, enabling us to analyze unstructured data in ways our predecessors were never able to. Milvus, an open-source vector database, can efficiently process the feature vectors extracted by AI models and provides a variety of common vector similarity calculations.
References
Hershey, S., Chaudhuri, S., Ellis, D.P., Gemmeke, J.F., Jansen, A., Moore, R.C., Plakal, M., Platt, D., Saurous, R.A., Seybold, B. and Slaney, M., 2017, March. CNN architectures for large-scale audio classification. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 131-135, 2017
Don’t be a stranger
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



