Milvus Is an Open-Source Scalable Vector Database
Searching data using easily defined criteria, for example querying a movie database by actor, director, genre, or release date, is simple. A relational database is well equipped for these types of basic searches using a query language such as SQL. But when searches involve complex objects and more abstract queries, such as searching a video streaming library using natural language or a video clip, simple similarity metrics like matching words in a title or description are no longer sufficient.
Artificial intelligence (AI) has made computers significantly more capable of understanding the semantics of language, as well as helping people make sense of massive, difficult to analyze unstructured datasets (e.g., audio, video, documents, and social media data). AI makes it possible for Netflix to create sophisticated content recommendation engines, Google users to search the web by image, and pharmaceutical companies to discover new drugs.
The challenge of searching large unstructured datasets
These feats of technology are accomplished by using AI algorithms to convert dense unstructured data into vectors, a numerical data format that is easily read by machines. Next, additional algorithms are used to calculate the similarity between vectors for a given search. The large size of unstructured datasets makes searching them in their entirety far too time consuming for most machine learning applications. To overcome this, approximate nearest neighbor (ANN) algorithms are used to cluster similar vectors together, then only search the portion of the dataset most likely to contain similar vectors to the target search vector.
This results in drastically faster (though slightly less accurate) similarity search, and is key to building useful AI tools. Thanks to vast public resources, it has never been easier or cheaper to build machine learning applications. However, AI-powered vector similarity search often requires interlacing different tools that vary in number and complexity depending on specific project requirements. Milvus is an open-source AI search engine that aims to simplify the process of building machine learning applications by providing robust functionality under a unified platform.
What is Milvus?
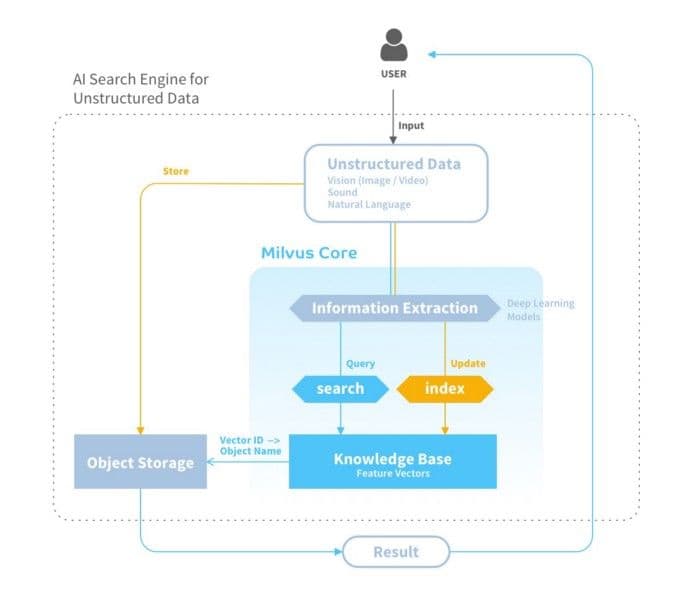
Milvus is an open-source data management platform built specifically for massive-scale vector data and streamlining machine learning operations (MLOps). Powered by Facebook AI Similarity Search (Faiss), Non-Metric Space Library (NMSLIB), and Annoy, Milvus brings a variety of powerful tools together in one place while extending their standalone functionality. The system was purpose built for storing, processing, and analyzing large vector datasets, and can be used to build AI applications spanning computer vision, recommendation engines, and much more.
 Blog_Milvus Is an Open-Source Scalable AI Search Engine_1.jpg
Blog_Milvus Is an Open-Source Scalable AI Search Engine_1.jpg
Milvus was made to power vector similarity search
Milvus was designed for flexibility, allowing developers to optimize the platform for their specific use case. Support for CPU/GPU-only and heterogeneous computing makes it possible to accelerate data processing and optimize resource requirements for any scenario. Data is stored in Milvus on a distributed architecture, making it trivial to scale data volumes. With support for various AI models, programming languages (e.g., C++, Java, and Python), and processor types (e.g., x86, ARM, GPU, TPU, and FPGA), Milvus offers high compatibility with a wide variety of hardware and software.
For more information about Milvus, check out the following resources:
- Explore Milvus’ technical documentation and learn more about the platform’s inner workings.
- Learn how to launch Milvus, build applications, and more using Milvus tutorials.
- Make contributions to the project and engage with Milvus’ open-source community on GitHub.
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



