Cos'è Milvus?
Tutto quello che devi sapere su Milvus in meno di 10 minuti.
Cosa sono gli embedding vettoriali?
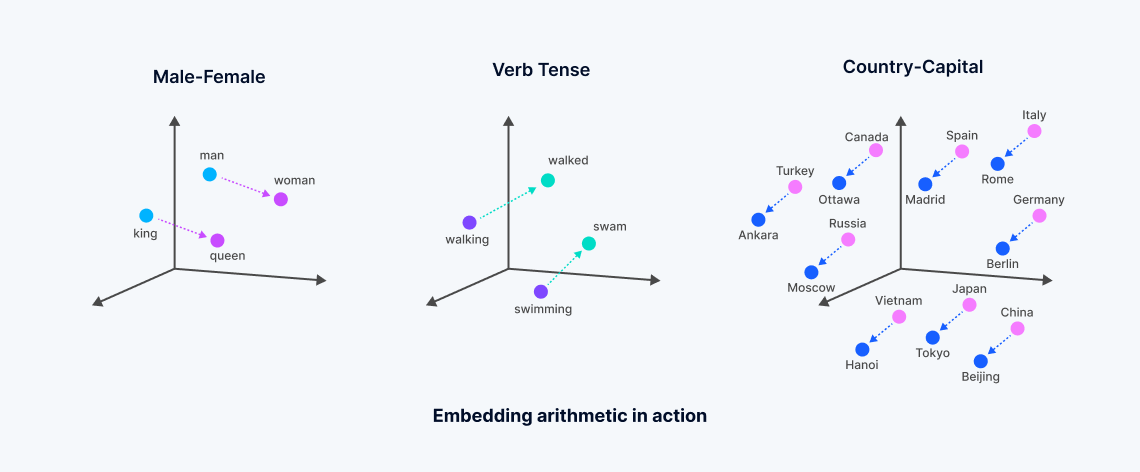
Gli embedding vettoriali sono rappresentazioni numeriche derivate da modelli di machine learning, che racchiudono il significato semantico dei dati non strutturati. Questi embedding sono generati attraverso l'analisi di correlazioni complesse all'interno dei dati da parte di reti neurali o architetture trasformative, creando uno spazio vettoriale denso in cui ogni punto corrisponde al "significato" degli oggetti dati, come le parole in un documento.
Questo processo trasforma i dati testuali o altri dati non strutturati in vettori che riflettono somiglianze semantiche—parole con significati correlati sono posizionate più vicine in questo spazio multidimensionale, facilitando un tipo di ricerca noto come "ricerca vettoriale densa". Questo contrasta con la ricerca per parole chiave tradizionale, che si basa su corrispondenze esatte e utilizza vettori sparsi. Lo sviluppo degli embedding vettoriali, spesso derivati da modelli fondamentali addestrati estensivamente da grandi aziende tecnologiche, permette ricerche più sfumate che catturano l'essenza dei dati, superando i limiti dei metodi di ricerca lessicale o vettoriale sparsa.
A cosa posso utilizzare gli embedding vettoriali?
Gli embedding vettoriali possono essere utilizzati in varie applicazioni, migliorando l'efficienza e la precisione in vari modi. Ecco alcuni dei casi d'uso più frequenti:
Trovare immagini, video o file audio simili
Gli embedding vettoriali permettono di cercare contenuti multimediali simili per contenuto piuttosto che solo per parole chiave, utilizzando Reti Neurali Convoluzionali (CNN) per analizzare immagini, fotogrammi video o segmenti audio. Questo permette ricerche avanzate, come trovare immagini basate su indizi sonori o video attraverso query di immagini, confrontando le rappresentazioni embedded memorizzate nei database vettoriali.
Accelerare la scoperta di farmaci
Nell'industria farmaceutica, gli embedding vettoriali possono codificare le strutture chimiche dei composti, facilitando l'identificazione di candidati farmaci promettenti misurando la loro somiglianza con proteine target. Questo accelera il processo di scoperta dei farmaci, risparmiando tempo e risorse concentrandosi sui lead più promettenti.
Potenziare la pertinenza della ricerca con la ricerca semantica
Embeddando i documenti interni in vettori, le organizzazioni possono sfruttare la ricerca semantica per migliorare la pertinenza dei risultati di ricerca. Questo metodo utilizza il concetto di Retrieval Augmented Generation (RAG) per comprendere l'intento dietro le query, fornendo risposte dai dati dell'azienda attraverso modelli AI come ChatGPT, riducendo così i risultati irrilevanti e le allucinazioni AI.
Sistemi di raccomandazione
Gli embedding vettoriali rivoluzionano i sistemi di raccomandazione rappresentando utenti e oggetti come embedding per misurare la somiglianza. Questo approccio permette raccomandazioni personalizzate basate su preferenze individuali, migliorando la soddisfazione e l'impegno degli utenti con le piattaforme online.
Rilevamento delle anomalie
In campi come il rilevamento delle frodi, la sicurezza delle reti e il monitoraggio industriale, gli embedding vettoriali sono strumentali nell'identificare pattern insoliti. I punti dati rappresentati come embedding permettono di rilevare anomalie calcolando distanze o dissimilarità, facilitando l'identificazione precoce e le misure preventive contro potenziali problemi.
Cosa sono i database vettoriali?
I database vettoriali sono sistemi specializzati progettati per gestire e recuperare dati non strutturati attraverso embedding vettoriali e rappresentazioni numeriche che catturano l'essenza degli elementi dati come immagini, audio, video e contenuti testuali. A differenza dei database relazionali tradizionali che gestiscono dati strutturati con operazioni di ricerca precise, i database vettoriali eccellono nelle ricerche di somiglianza semantica utilizzando tecniche come l'algoritmo Approximate Nearest Neighbor (ANN). Questa capacità è cruciale per lo sviluppo di applicazioni in vari domini, inclusi sistemi di raccomandazione, chatbot e strumenti di ricerca di contenuti multimediali, e per affrontare le sfide poste dall'AI e dai grandi modelli linguistici come ChatGPT, come comprendere il contesto e le sfumature e l'allucinazione AI.
L'avvento di database vettoriali come Milvus sta trasformando le industrie permettendo ricerche basate su contenuti su una vasta gamma di dati non strutturati, superando i limiti delle etichette generate dall'uomo. Le caratteristiche chiave che distinguono i database vettoriali includono
Scalabilità e adattabilità per gestire volumi di dati in crescita
Multi-tenancy e isolamento dei dati per un uso efficiente delle risorse e la privacy
Una suite completa di API per diversi linguaggi di programmazione
Interfacce user-friendly che semplificano l'interazione con dati complessi.
Questi attributi garantiscono che i database vettoriali possano soddisfare le esigenze delle applicazioni moderne, offrendo potenti strumenti per esplorare e sfruttare i dati non strutturati in modi che i database tradizionali non possono.
Database Vettoriale vs. Libreria di Ricerca Vettoriale
Le librerie di ricerca vettoriale come FAISS, ScaNN e HNSW offrono strumenti fondamentali per costruire sistemi prototipo capaci di eseguire ricerche di somiglianza efficienti e clustering vettoriale denso. Queste librerie, sebbene potenti e open-source, sono progettate principalmente per il recupero vettoriale e offrono un setup rapido con capacità come la gestione di grandi collezioni di vettori e la fornitura di interfacce per la valutazione e la regolazione dei parametri. Tuttavia, sono carenti in termini di scalabilità, multi-tenancy e modifica dinamica dei dati, rendendole meno adatte per dataset più grandi e complessi e per basi utenti in crescita.
Al contrario, i database vettoriali emergono come una soluzione più completa progettata per accogliere lo stoccaggio e il recupero in tempo reale di milioni a miliardi di vettori. Forniscono un livello più alto di astrazione, scalabilità, natività cloud e caratteristiche user-friendly che superano le funzionalità di base delle librerie di ricerca vettoriale. Sebbene librerie come FAISS siano componenti integrali su cui i database vettoriali possono costruire, questi ultimi sono servizi completi che semplificano operazioni come l'inserimento e la gestione dei dati, rendendoli più allineati con le esigenze di applicazioni su larga scala e dinamiche nel campo dell'elaborazione dei dati non strutturati.
Database Vettoriali vs. Plugin di ricerca vettoriale per database tradizionali
I database vettoriali e i plugin di ricerca vettoriale per database tradizionali svolgono ruoli distinti nella gestione delle ricerche basate su vettori. Plugin come quelli in Elasticsearch 8.0 offrono capacità di ricerca vettoriale all'interno delle architetture di database esistenti, funzionando come miglioramenti piuttosto che soluzioni complete. Questi plugin mancano di un approccio full-stack alla gestione degli embedding e alla ricerca vettoriale, risultando in limitazioni e prestazioni subottimali per le applicazioni di dati non strutturati.
Caratteristiche chiave come la regolabilità e API/SDK user-friendly, essenziali per un'operazione efficace del database vettoriale, sono notevolmente assenti nei plugin di ricerca vettoriale. Ad esempio, il motore ANN di Elasticsearch, pur supportando lo stoccaggio e la query di base dei vettori, è limitato dal suo algoritmo di indicizzazione e dalle opzioni di metrica di distanza, offrendo meno flessibilità rispetto a un database vettoriale dedicato come Milvus. Milvus, progettato fin dall'inizio come database vettoriale, offre un'API più intuitiva, un supporto più ampio per i metodi di indicizzazione e le metriche di distanza, e la potenzialità per query simili a SQL, evidenziando la sua superiorità nella gestione e query dei dati non strutturati. Questa differenza fondamentale sottolinea perché i database vettoriali, con i loro set di caratteristiche complete e l'architettura adattata per i dati non strutturati, sono preferiti rispetto ai plugin di ricerca vettoriale per ottenere una ricerca e gestione ottimale degli embedding vettoriali.
Come si differenzia Milvus dagli altri database vettoriali?
Milvus si distingue come database vettoriale con la sua architettura scalabile e le sue diverse capacità progettate per accelerare e unificare le esperienze di ricerca in varie applicazioni. Le caratteristiche chiave sono:
Architettura Scalabile ed Elastica
Milvus è progettato per una scalabilità e un'elasticità eccezionali, adattandosi alle esigenze dinamiche delle applicazioni moderne. Ciò viene ottenuto attraverso un design orientato ai servizi, decoupling storage, coordinatori e worker, permettendo il ridimensionamento componente per componente. Questo approccio modulare garantisce che diversi compiti computazionali possano scalare indipendentemente in base ai carichi di lavoro variabili, fornendo un'allocazione e un isolamento delle risorse a grana fine.
Supporto per Indici Diversi
Milvus supporta una vasta gamma di oltre 10 tipi di indici, inclusi quelli ampiamente utilizzati come HNSW, IVF, Product Quantization e indicizzazione basata su GPU. Questa varietà permette agli sviluppatori di ottimizzare le ricerche in base a requisiti specifici di prestazioni e precisione, garantendo che il database possa adattarsi a una vasta gamma di applicazioni e caratteristiche dei dati. L'espansione continua delle sue offerte di indici, ad esempio l'indice GPU, migliora ulteriormente l'adattabilità e l'efficacia di Milvus nella gestione di compiti di ricerca complessi.
Capacità di Ricerca Versatili
Milvus offre una vasta gamma di tipi di ricerca, inclusi top-K Approximate Nearest Neighbor (ANN), Range ANN e ricerca con filtraggio dei metadati, e la prossima ricerca ibrida di vettori densi e sparsi. Questa diversità permette una flessibilità e una precisione delle query senza pari, concedendo agli sviluppatori la capacità di personalizzare le strategie di recupero dei dati per soddisfare le esigenze specifiche delle applicazioni, ottimizzando così sia la pertinenza che l'efficienza dei risultati di ricerca.
Consistenza Regolabile
Milvus offre un modello di consistenza delta che permette agli utenti di specificare una "tolleranza di obsolescenza" per i dati di query, permettendo un bilanciamento su misura tra prestazioni di query e freschezza dei dati. Questa flessibilità è cruciale per le applicazioni che richiedono risultati aggiornati senza sacrificare i tempi di risposta, supportando efficacemente sia la consistenza forte che quella eventuale in base alle esigenze dell'applicazione.
Supporto per Calcolo Accelerato Hardware
Milvus è progettato per sfruttare vari tipi di capacità di calcolo, come AVX512 e Neon per l'esecuzione SIMD, insieme a quantizzazione, ottimizzazioni cache-aware e supporto GPU. Questo approccio permette un utilizzo efficiente delle specifiche forze hardware, garantendo un'elaborazione rapida e una scalabilità costo-efficace. Adattando l'uso delle risorse alle esigenze uniche delle diverse applicazioni, Milvus migliora sia la velocità che l'efficienza delle operazioni di gestione e ricerca dei dati vettoriali.
Come funziona Milvus in sintesi?
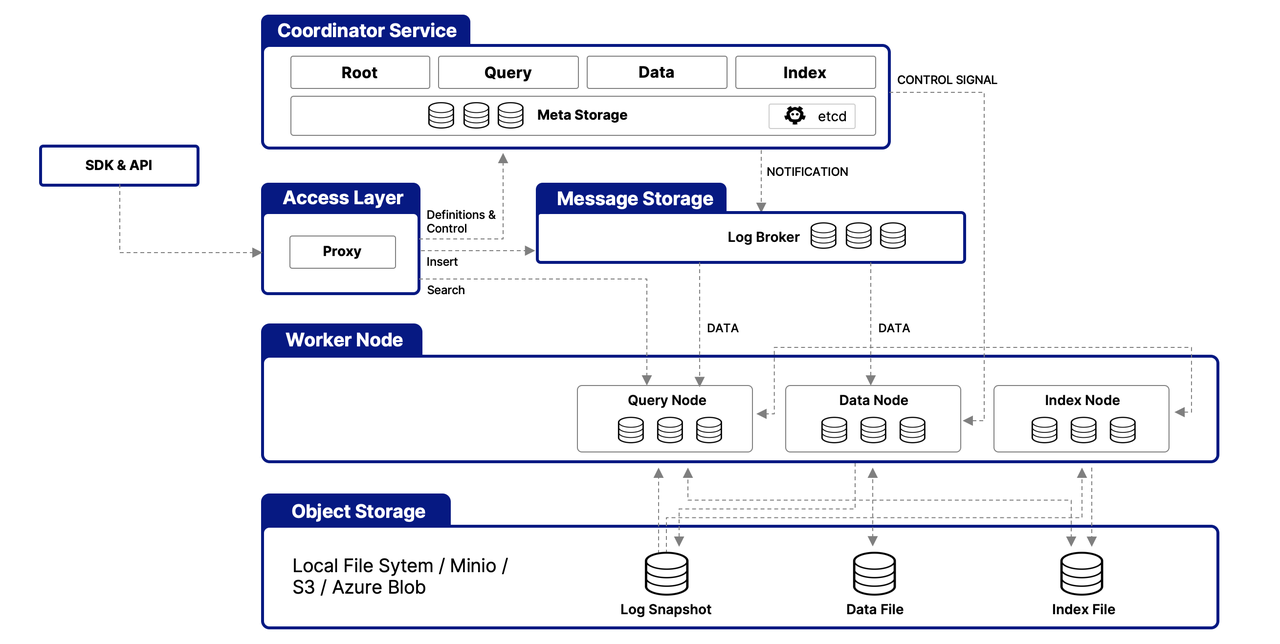
Milvus è strutturato intorno a un'architettura a più livelli progettata per gestire ed elaborare efficacemente i dati vettoriali, garantendo scalabilità, regolabilità e isolamento dei dati. Ecco una panoramica semplificata della sua architettura:
Livello di Accesso
Questo livello funge da punto di contatto iniziale per le richieste esterne, utilizzando proxy senza stato per la gestione delle connessioni client, verifica statica e controlli dinamici. Questi proxy gestiscono anche il bilanciamento del carico e sono fondamentali per implementare la suite completa di API di Milvus. Una volta che il servizio a valle elabora una richiesta, il livello di accesso instrada la risposta indietro all'utente.
Servizio Coordinatore
Agendo come comando centrale, questo servizio orchestra il bilanciamento del carico e la gestione dei dati attraverso quattro coordinatori, che garantiscono una gestione efficiente dei dati, delle query e degli indici.
The Root Coordinator: managing data-related tasks and global timestamps
The Query Coordinator: overseeing query nodes for search operations
The Data Coordinator: handling data nodes and metadata
The Index Coordinator: maintaining index nodes and metadata
Nodi Worker
Responsabili dell'effettiva esecuzione dei compiti, i nodi worker sono pod scalabili che eseguono comandi dai coordinatori. Permettono a Milvus di adattarsi dinamicamente ai cambiamenti nei dati, nelle query e nelle esigenze di indicizzazione, supportando la scalabilità e la regolabilità del sistema.
Livello di Archiviazione Oggetti
Fondamentale per la persistenza dei dati, questo livello consiste in
Meta store: using etcd for metadata snapshots and system health checks
Log broker: for streaming data persistence and recovery, utilizing Pulsar or RocksDB
Object storage: storing log snapshots, index files, and query results, with support for services like AWS S3, Azure Blob Storage, and MinIO
Dove andare da qui?
- To get hands-on experience with Milvus, follow the get started guide.
- To understand Milvus in more detail, read the Documentation.
- Browse through the Use Cases to learn how other users in our worldwide community are getting value from Milvus.
Join a local Unstructured Data meetup and our Discord.