Apa itu Milvus?
Semua yang perlu Anda ketahui tentang Milvus dalam waktu kurang dari 10 menit.
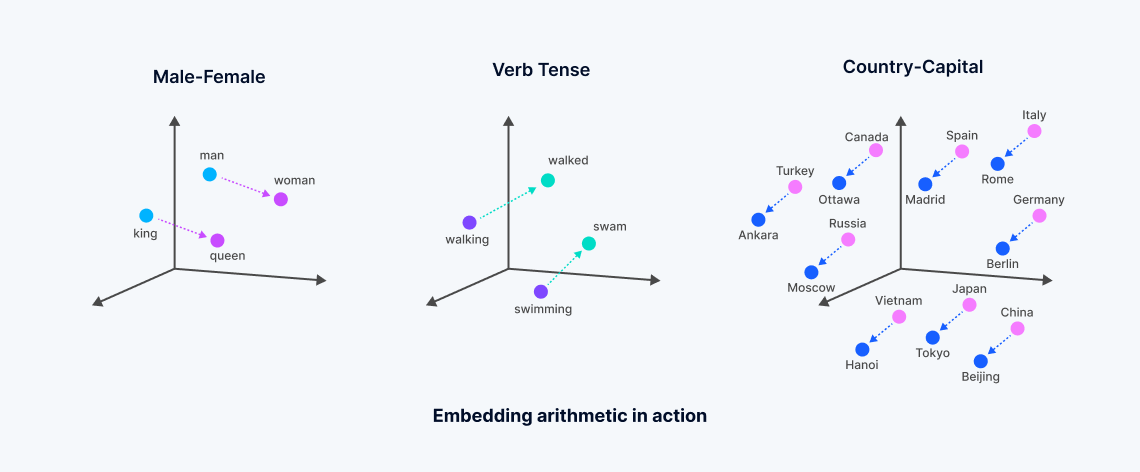
Apa itu embedding vektor?
Embedding vektor adalah representasi numerik yang dihasilkan dari model pembelajaran mesin, mengapsulkan makna semantik dari data tak terstruktur. Embedding ini dihasilkan melalui analisis korelasi kompleks dalam data oleh jaringan saraf atau arsitektur transformer, membuat ruang vektor padat di mana setiap titik sesuai dengan "makna" objek data, seperti kata dalam dokumen.
Proses ini mengubah data teks atau data tak terstruktur lainnya menjadi vektor yang mencerminkan kemiripan semantik—kata dengan makna yang terkait lebih dekat satu sama lain dalam ruang multidimensi ini, memfasilitasi jenis pencarian yang dikenal sebagai "pencarian vektor padat". Ini berbeda dengan pencarian kata kunci tradisional, yang bergantung pada kecocokan yang tepat dan menggunakan vektor jarang. Pengembangan embedding vektor, seringkali berasal dari model dasar yang dilatih secara ekstensif oleh perusahaan teknologi besar, memungkinkan pencarian yang lebih halus yang menangkap esensi data, melampaui batasan metode pencarian vektor leksikal atau jarang.
Apa yang dapat saya lakukan dengan embedding vektor?
Embedding vektor dapat digunakan di berbagai aplikasi, meningkatkan efisiensi dan akurasi dengan berbagai cara. Berikut adalah beberapa kasus penggunaan yang paling sering:
Menemukan Gambar, Video, atau File Audio yang Mirip
Embedding vektor memungkinkan pencarian konten multimedia yang mirip berdasarkan konten daripada hanya kata kunci, menggunakan Jaringan Saraf Konvolusi (CNN) untuk menganalisis gambar, bingkai video, atau segmen audio. Ini memungkinkan pencarian maju, seperti menemukan gambar berdasarkan petunjuk suara atau video melalui kueri gambar, dengan membandingkan representasi tersembunyi yang disimpan dalam basis data vektor.
Mempercepat Penemuan Obat
Dalam industri farmasi, embedding vektor dapat mengkodekan struktur kimia senyawa, memfasilitasi identifikasi kandidat obat yang menjanjikan dengan mengukur kemiripannya dengan protein target. Ini mempercepat proses penemuan obat, menghemat waktu dan sumber daya dengan fokus pada petunjuk yang paling layak.
Meningkatkan Relevansi Pencarian dengan Pencarian Semantik
Dengan memasukkan dokumen internal ke dalam vektor, organisasi dapat memanfaatkan pencarian semantik untuk meningkatkan relevansi hasil pencarian. Metode ini menggunakan konsep Generasi yang Diperkaya Retrieval (RAG) untuk memahami maksud di balik kueri, memberikan jawaban dari data perusahaan melalui model AI seperti ChatGPT, sehingga mengurangi hasil yang tidak relevan dan halusinasi AI.
Sistem Rekomendasi
Embedding vektor merevolusi sistem rekomendasi dengan mewakili pengguna dan item sebagai embedding untuk mengukur kemiripan. Pendekatan ini memungkinkan rekomendasi yang dipersonalisasi berdasarkan preferensi individu, meningkatkan kepuasan dan keterlibatan pengguna dengan platform online.
Deteksi Anomali
Dalam bidang seperti deteksi penipuan, keamanan jaringan, dan pemantauan industri, embedding vektor sangat penting dalam mengidentifikasi pola yang tidak biasa. Titik data yang direpresentasikan sebagai embedding memungkinkan deteksi anomali dengan menghitung jarak atau perbedaan, memfasilitasi identifikasi dan tindakan pencegahan dini terhadap masalah potensial.
Apa yang dimaksud dengan basis data vektor?
Basis data vektor adalah sistem khusus yang dirancang untuk mengelola dan mengambil kembali data tak terstruktur melalui embedding vektor dan representasi numerik yang menangkap esensi item data seperti gambar, audio, video, dan konten teks. Berbeda dengan basis data relasional tradisional yang menangani data terstruktur dengan operasi pencarian yang presisi, basis data vektor unggul dalam pencarian kemiripan semantik menggunakan algoritma Tetangga Terdekat Aproksimasi (ANN). Kemampuan ini sangat penting untuk mengembangkan aplikasi di berbagai domain, termasuk sistem rekomendasi, chatbot, dan alat pencarian konten multimedia, serta untuk menangani tantangan yang diajukan oleh AI dan model bahasa besar seperti ChatGPT, seperti memahami konteks dan nuansa serta halusinasi AI.
Kemunculan basis data vektor seperti Milvus mengubah industri dengan memungkinkan pencarian berbasis konten di sekala besar data tak terstruktur, melampaui batasan label yang dihasilkan manusia. Fitur kunci yang membedakan basis data vektor termasuk
Skalabilitas dan keterkaitan untuk menangani volume data yang terus bertambah
Multi-tenancy dan isolasi data untuk penggunaan sumber daya yang efisien dan privasi
Sebuah suite API komprehensif untuk berbagai bahasa pemrograman
Antarmuka yang ramah pengguna yang menyederhanakan interaksi dengan data kompleks.
Atribut ini memastikan bahwa basis data vektor dapat memenuhi tuntutan aplikasi modern, menawarkan alat yang kuat untuk menjelajahi dan memanfaatkan data tak terstruktur dengan cara yang tidak dapat dilakukan oleh basis data tradisional.
Basis Data Vektor vs. Perpustakaan Pencarian Vektor
Perpustakaan pencarian vektor seperti FAISS, ScaNN, dan HNSW menawarkan alat dasar untuk membangun sistem prototipe yang mampu melakukan pencarian kemiripan yang efisien dan pengelompokan vektor padat. Meskipun kuat dan sumber terbuka, perpustakaan ini dirancang khusus untuk pengambilan vektor dan menawarkan pengaturan cepat dengan kemampuan seperti menangani koleksi vektor besar dan menyediakan antarmuka untuk evaluasi dan penyetelan parameter. Namun, mereka kurang dalam hal skalabilitas, multi-tenancy, dan modifikasi data dinamis, membuat mereka kurang cocok untuk kumpulan data yang lebih besar dan kompleks serta basis pengguna yang terus berkembang.
Sebaliknya, basis data vektor muncul sebagai solusi yang lebih komprehensif yang dirancang untuk menampung dan pengambilan kembali vektor dari ratusan juta hingga milyaran vektor secara real-time. Mereka menawarkan tingkat abstraksi, skalabilitas, dan kekayaan sumber daya yang lebih tinggi yang melampaui fungsionalitas dasar perpustakaan pencarian vektor. Meskipun perpustakaan seperti FAISS adalah komponen integral yang basis data vektor dapat membangun, yang terakhir adalah layanan lengkap yang menyederhanakan operasi seperti penyisipan dan pengelolaan data, membuat mereka lebih sesuai dengan tuntutan aplikasi dinamis skala besar dalam ranah pemrosesan data tak terstruktur.
Basis Data Vektor vs. Plugin Pencarian Vektor untuk Basis Data Tradisional
Basis data vektor dan plugin pencarian vektor untuk basis data tradisional memainkan peran yang berbeda dalam menangani pencarian berbasis vektor. Plugin seperti yang ada di Elasticsearch 8.0 menawarkan kemampuan pencarian vektor di dalam arsitektur basis data yang ada, berfungsi sebagai peningkatan daripada solusi komprehensif. Plugin ini kurang dalam pendekatan penuh stak untuk manajemen embedding dan pencarian vektor, menghasilkan batasan dan kinerja suboptimal untuk aplikasi data tak terstruktur.
Fitur kunci seperti keterkaitan dan API/SDK yang ramah pengguna, yang esensial untuk operasi basis data vektor yang efektif, sangat tidak ada dalam plugin pencarian vektor. Misalnya, mesin ANN Elasticsearch, meskipun mendukung penyimpanan dan pengkuerian vektor dasar, terbatas oleh algoritma indeks dan opsi metrik jaraknya, menawarkan fleksibilitas yang lebih rendah dibandingkan dengan basis data vektor khusus seperti Milvus. Milvus, yang dirancang dari awal sebagai basis data vektor, menyediakan API yang lebih intuitif, dukungan yang lebih luas untuk metode indeks dan metrik jarak, serta potensi untuk pengkuerian seperti SQL, menonjolkan keunggulannya dalam mengelola dan mengkueri data tak terstruktur. Perbedaan dasar ini menjelaskan mengapa basis data vektor, dengan set fitur komprehensif dan arsitektur yang disesuaikan untuk data tak terstruktur, lebih disukai daripada plugin pencarian vektor untuk mencapai pencarian dan pengelolaan optimal embedding vektor.
Bagaimana Milvus berbeda dengan basis data vektor lainnya?
Milvus menonjol sebagai basis data vektor dengan arsitektur skalabel dan kemampuan beragam yang dirancang untuk mempercepat dan menyatukan pengalaman pencarian di berbagai aplikasi. Titik sorot fitur kunci adalah:
Arsitektur Skalabel dan Elastis
Milvus dirancang untuk skalabilitas dan elastisitas yang luar biasa, mengakomodasi tuntutan dinamis aplikasi modern. Ini dicapai melalui desain yang berorientasi pada layanan, memisahkan penyimpanan, koordinator, dan pekerja, memungkinkan penskalaan berdasarkan komponen. Pendekatan modular ini memastikan bahwa tugas komputasi yang berbeda dapat discale secara independen sesuai dengan beban kerja yang berbeda, menyediakan alokasi dan isolasi sumber daya yang halus.
Dukungan Indeks yang Beragam
Milvus mendukung sejumlah besar lebih dari 10 jenis indeks, termasuk yang sering digunakan seperti HNSW, IVF, Kuantisasi Produk, dan indeks berbasis GPU. Kebagian ini memungkinkan pengembang untuk mengoptimalkan pencarian sesuai dengan persyaratan kinerja dan akurasi khusus, memastikan bahwa basis data dapat menyesuaikan berbagai aplikasi dan karakteristik data. Ekspansi berterusan dari tawaran indeksnya, misalnya indeks GPU, lebih meningkatkan kemampuan adaptasi dan efektivitas Milvus dalam menangani tugas pencarian yang kompleks.
Kemampuan Pencarian yang Lentur
Milvus menawarkan berbagai jenis pencarian, termasuk ANN K Teratas (Approximate Nearest Neighbor), ANN Rentang, dan pencarian dengan penyaringan metadata, serta pencarian vektor padat dan jarang campuran yang akan datang. Keberagaman ini memungkinkan fleksibilitas dan presisi kueri yang tidak tertandingi, memberikan pengembang kemampuan untuk menyesuaikan strategi pengambilan data untuk memenuhi tuntutan aplikasi khusus, sehingga mengoptimalkan kedua relevansi dan efisiensi hasil pencarian.
Konsistensi yang Dapat Disetel
Milvus menawarkan model konsistensi delta yang memungkinkan pengguna untuk menentukan "toleransi kekunoan" untuk data kueri, mengaktifkan keseimbangan yang disesuaikan antara kinerja kueri dan kebaruan data. Fleksibilitas ini sangat penting untuk aplikasi yang membutuhkan hasil yang terkini tanpa mengorbankan waktu respons, secara efektif mendukung kedua konsistensi kuat dan eventual sesuai dengan kebutuhan aplikasi.
Dukungan Komputasi yang Dipercepat Perangkat Keras
Milvus dirancang untuk memanfaatkan berbagai jenis kemampuan komputasi, seperti AVX512 dan Neon untuk eksekusi SIMD, bersama dengan kuantisasi, optimasi yang sadar akan cache, dan dukungan GPU. Pendekatan ini memungkinkan pemanfaatan yang efisien dari kekuatan perangkat keras khusus, memastikan pemrosesan yang cepat dan skalabilitas yang efisien secara biaya. Dengan menyesuaikan penggunaan sumber daya dengan tuntutan khusus dari berbagai aplikasi, Milvus meningkatkan kedua kecepatan dan efisiensi manajemen dan operasi pencarian data vektor.
Bagaimana Milvus bekerja secara ringkas?
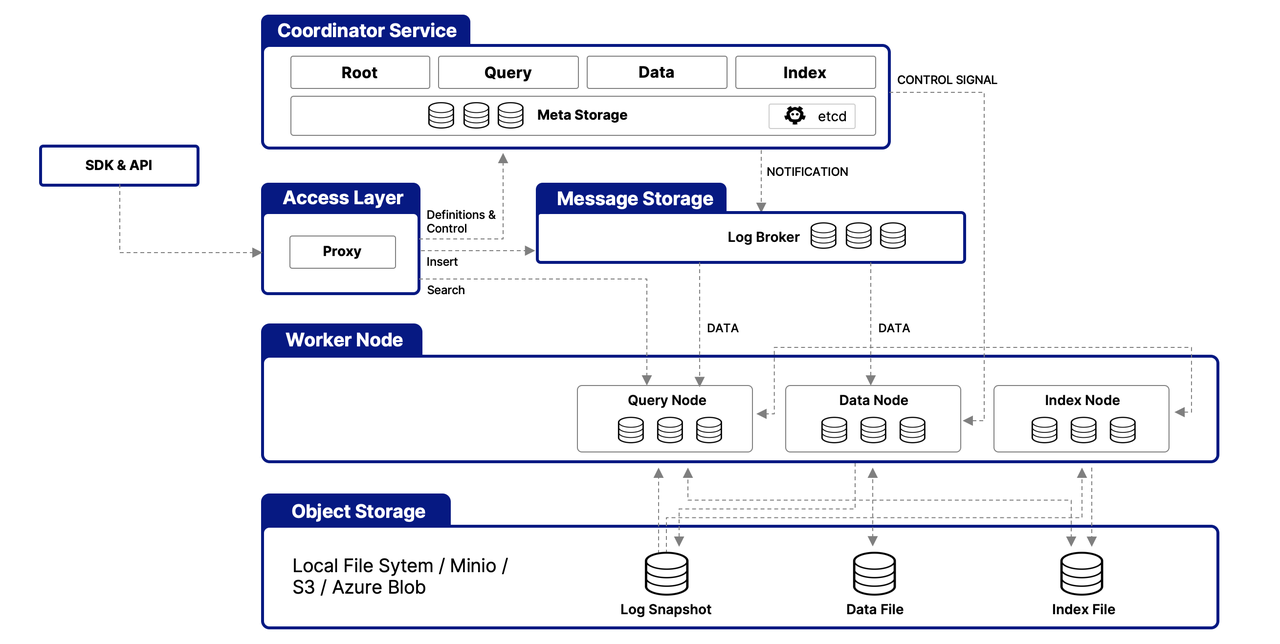
Milvus dirancang di sekitar arsitektur multilapisan untuk menangani dan memproses data vektor secara efisien, memastikan skalabilitas, keterkaitan, dan isolasi data. Berikut adalah gambaran sederhana dari arsitekturnya:
Lapisan Akses
Lapisan ini berfungsi sebagai titik kontak awal untuk permintaan eksternal, menggunakan proksi tanpa status untuk manajemen koneksi klien, verifikasi statis, dan pemeriksaan dinamis. Proksi ini juga menangani pengimbangan beban dan sangat penting dalam menerapkan suite API komprehensif Milvus. Setelah layanan hilir mengolah permintaan, lapisan akses mengarahkan respons kembali ke pengguna.
Layanan Koordinator
Berfungsi sebagai komando pusat, layanan ini mengorchestrasi pengimbangan beban dan manajemen data melalui empat koordinator, yang memastikan manajemen data, kueri, dan indeks yang efisien.
The Root Coordinator: managing data-related tasks and global timestamps
The Query Coordinator: overseeing query nodes for search operations
The Data Coordinator: handling data nodes and metadata
The Index Coordinator: maintaining index nodes and metadata
Node Pekerja
Bertanggung jawab atas eksekusi aktual tugas, node pekerja adalah pod yang dapat discale yang melaksanakan perintah dari koordinator. Mereka memungkinkan Milvus untuk menyesuaikan secara dinamis terhadap permintaan data, kueri, dan indeks yang berubah, mendukung skalabilitas dan keterkaitan sistem.
Lapisan Penyimpanan Objek
Fundamental untuk kekekalan data, lapisan ini terdiri dari
Meta store: using etcd for metadata snapshots and system health checks
Log broker: for streaming data persistence and recovery, utilizing Pulsar or RocksDB
Object storage: storing log snapshots, index files, and query results, with support for services like AWS S3, Azure Blob Storage, and MinIO
Ke mana dari sini?
- To get hands-on experience with Milvus, follow the get started guide.
- To understand Milvus in more detail, read the Documentation.
- Browse through the Use Cases to learn how other users in our worldwide community are getting value from Milvus.
Join a local Unstructured Data meetup and our Discord.