Qu'est-ce que Milvus ?
Tout ce que vous devez savoir sur Milvus en moins de 10 minutes.
Qu'est-ce que les embeddings vectoriels ?
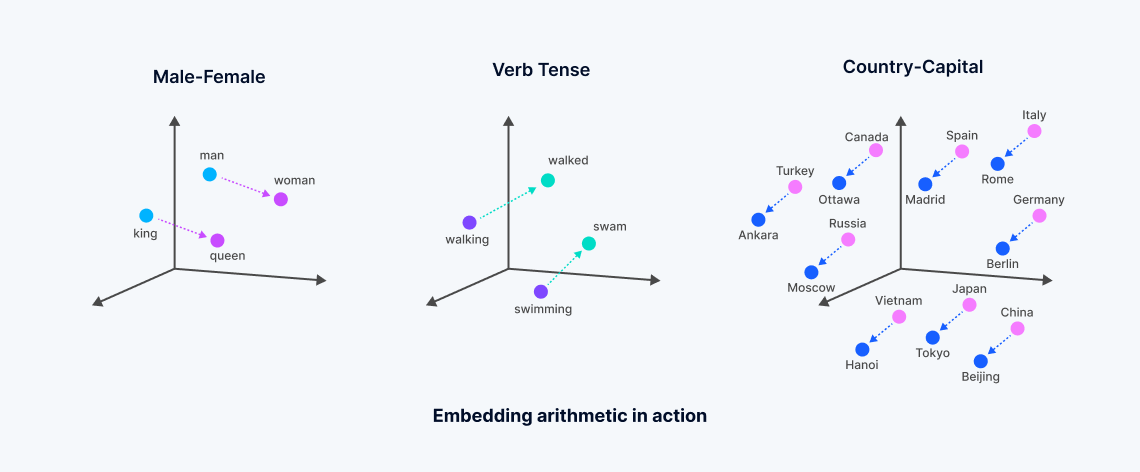
Les embeddings vectoriels sont des représentations numériques dérivées de modèles d'apprentissage automatique, encapsulant la signification sémantique des données non structurées. Ces embeddings sont générés par l'analyse de corrélations complexes au sein des données par des réseaux de neurones ou des architectures de transformateurs, créant un espace vectoriel dense où chaque point correspond à la "signification" des objets de données, tels que les mots dans un document.
Ce processus transforme les données textuelles ou autres données non structurées en vecteurs qui reflètent les similarités sémantiques—les mots ayant des significations apparentées sont positionnés plus près les uns des autres dans cet espace multidimensionnel, facilitant un type de recherche connu sous le nom de "recherche de vecteurs denses". Cela contraste avec la recherche de mots-clés traditionnelle, qui repose sur des correspondances exactes et utilise des vecteurs épars. Le développement des embeddings vectoriels, souvent issus de modèles fondamentaux entraînés de manière intensive par de grandes entreprises technologiques, permet des recherches plus nuancées qui capturent l'essence des données, dépassant les limitations des méthodes de recherche de vecteurs lexicaux ou épars.
À quoi puis-je utiliser les embeddings vectoriels ?
Les embeddings vectoriels peuvent être utilisés dans diverses applications, améliorant l'efficacité et la précision de différentes manières. Voici quelques-uns des cas d'utilisation les plus fréquents :
Recherche d'images, de vidéos ou de fichiers audio similaires
Les embeddings vectoriels permettent de rechercher un contenu multimédia similaire par contenu plutôt que par mots-clés, en utilisant des réseaux de neurones convolutifs (CNN) pour analyser des images, des segments vidéo ou audio. Cela permet des recherches avancées, comme trouver des images basées sur des indices sonores ou des vidéos via des requêtes d'images, en comparant les représentations intégrées stockées dans des bases de données vectorielles.
Accélération de la découverte de médicaments
Dans l'industrie pharmaceutique, les embeddings vectoriels peuvent encoder les structures chimiques de composés, facilitant l'identification de candidats médicamenteux prometteurs en mesurant leur similarité avec des protéines cibles. Cela accélère le processus de découverte de médicaments, économisant du temps et des ressources en se concentrant sur les pistes les plus viables.
Amélioration de la pertinence de la recherche avec la recherche sémantique
En intégrant des documents internes dans des vecteurs, les organisations peuvent utiliser la recherche sémantique pour améliorer la pertinence des résultats de recherche. Cette méthode utilise le concept de Génération Augmentée par Récupération (RAG) pour comprendre l'intention derrière les requêtes, fournissant des réponses à partir des données de l'entreprise via des modèles d'IA comme ChatGPT, réduisant ainsi les résultats non pertinents et les hallucinations de l'IA.
Systèmes de recommandation
Les embeddings vectoriels révolutionnent les systèmes de recommandation en représentant les utilisateurs et les éléments sous forme d'embeddings pour mesurer la similarité. Cette approche permet des recommandations personnalisées basées sur les préférences individuelles, améliorant la satisfaction et l'engagement des utilisateurs avec les plateformes en ligne.
Détection d'anomalies
Dans des domaines tels que la détection de fraudes, la sécurité des réseaux et la surveillance industrielle, les embeddings vectoriels sont essentiels pour identifier des schémas inhabituels. Les points de données représentés sous forme d'embeddings permettent de détecter des anomalies en calculant des distances ou des dissimilarités, facilitant une identification précoce et des mesures préventives contre des problèmes potentiels.
Qu'est-ce qu'une base de données vectorielle ?
Les bases de données vectorielles sont des systèmes spécialisés conçus pour gérer et récupérer des données non structurées via des embeddings vectoriels et des représentations numériques qui capturent l'essence des éléments de données tels que les images, l'audio, les vidéos et le contenu textuel. Contrairement aux bases de données relationnelles traditionnelles qui gèrent des données structurées avec des opérations de recherche précises, les bases de données vectorielles excellent dans les recherches de similarité sémantique en utilisant des techniques telles que l'algorithme du Plus Proche Voisin Approximatif (ANN). Cette capacité est cruciale pour développer des applications dans divers domaines, y compris les systèmes de recommandation, les chatbots et les outils de recherche de contenu multimédia, et pour relever les défis posés par l'IA et les grands modèles linguistiques comme ChatGPT, tels que la compréhension du contexte et des nuances et les hallucinations de l'IA.
L'avènement de bases de données vectorielles comme Milvus transforme les industries en permettant des recherches basées sur le contenu à travers un vaste ensemble de données non structurées, dépassant les contraintes des étiquettes générées par l'homme. Les caractéristiques clés qui distinguent les bases de données vectorielles comprennent :
Évolutivité et adaptabilité pour gérer des volumes de données croissants
Multi-tenancy et isolation des données pour une utilisation efficace des ressources et la confidentialité
Une suite complète d'API pour divers langages de programmation
Interfaces conviviales qui simplifient l'interaction avec des données complexes.
Ces attributs garantissent que les bases de données vectorielles peuvent répondre aux exigences des applications modernes, offrant des outils puissants pour explorer et exploiter les données non structurées de manières que les bases de données traditionnelles ne peuvent pas.
Base de données vectorielle vs. Bibliothèque de recherche vectorielle
Les bibliothèques de recherche vectorielle comme FAISS, ScaNN et HNSW offrent des outils fondamentaux pour construire des systèmes prototypes capables d'effectuer des recherches de similarité efficaces et un clustering de vecteurs denses. Ces bibliothèques, bien que puissantes et open-source, sont principalement conçues pour la récupération vectorielle et offrent une configuration rapide avec des capacités telles que la gestion de grandes collections de vecteurs et la fourniture d'interfaces pour l'évaluation et le réglage des paramètres. Cependant, elles sont limitées en termes d'évolutivité, de multi-tenancy et de modification dynamique des données, les rendant moins adaptées aux ensembles de données plus grands et plus complexes et aux bases d'utilisateurs en croissance.
En revanche, les bases de données vectorielles émergent comme une solution plus complète conçue pour accueillir le stockage et la récupération en temps réel de millions à des milliards de vecteurs. Elles offrent un niveau plus élevé d'abstraction, d'évolutivité, de nativité cloud et de fonctionnalités conviviales qui dépassent les fonctionnalités de base des bibliothèques de recherche vectorielle. Bien que des bibliothèques comme FAISS soient des composants intégraux sur lesquels les bases de données vectorielles peuvent s'appuyer, ces dernières sont des services complets qui simplifient les opérations telles que l'insertion et la gestion des données, les rendant plus alignées avec les exigences des applications dynamiques à grande échelle dans le domaine du traitement des données non structurées.
Bases de données vectorielles vs. Plugins de recherche vectorielle pour les bases de données traditionnelles
Les bases de données vectorielles et les plugins de recherche vectorielle pour les bases de données traditionnelles jouent des rôles distincts dans la gestion des recherches basées sur des vecteurs. Les plugins comme ceux d'Elasticsearch 8.0 offrent des capacités de recherche vectorielle au sein des architectures de bases de données existantes, fonctionnant comme des améliorations plutôt que comme des solutions complètes. Ces plugins manquent d'une approche complète de la gestion des embeddings et de la recherche vectorielle, entraînant des limitations et des performances sous-optimales pour les applications de données non structurées.
Des fonctionnalités clés telles que l'adaptabilité et les API/SDK conviviales, essentielles pour un fonctionnement efficace des bases de données vectorielles, sont notablement absentes dans les plugins de recherche vectorielle. Par exemple, le moteur ANN d'Elasticsearch, bien qu'il supporte le stockage et l'interrogation de base des vecteurs, est limité par son algorithme d'indexation et ses options de métrique de distance, offrant moins de flexibilité par rapport à une base de données vectorielle dédiée comme Milvus. Milvus, conçue dès le départ comme une base de données vectorielle, offre une API plus intuitive, un support plus large pour les méthodes d'indexation et les métriques de distance, ainsi que la possibilité d'interroger de manière similaire à SQL, soulignant sa supériorité dans la gestion et l'interrogation des données non structurées. Cette différence fondamentale explique pourquoi les bases de données vectorielles, avec leurs ensembles de fonctionnalités complets et leur architecture adaptée aux données non structurées, sont préférées aux plugins de recherche vectorielle pour réaliser une recherche et une gestion optimales des embeddings vectoriels.
Comment Milvus se différencie-t-il des autres bases de données vectorielles ?
Milvus se distingue comme une base de données vectorielle avec son architecture évolutive et ses capacités diverses conçues pour accélérer et unifier les expériences de recherche à travers diverses applications. Les points forts des fonctionnalités sont :
Architecture Évolutive et Élastique
Milvus est conçu pour une évolutivité et une élasticité exceptionnelles, s'adaptant aux demandes dynamiques des applications modernes. Il y parvient grâce à une conception orientée service, découplant le stockage, les coordinateurs et les travailleurs, permettant une mise à l'échelle par composant. Cette approche modulaire garantit que différentes tâches de calcul peuvent être mises à l'échelle indépendamment en fonction des charges de travail variables, offrant une allocation et une isolation des ressources à grain fin.
Support d'Index Diversifié
Milvus prend en charge une vaste gamme de plus de 10 types d'index, y compris des types largement utilisés tels que HNSW, IVF, Quantification de Produit et indexation basée sur GPU. Cette diversité permet aux développeurs d'optimiser les recherches en fonction de besoins spécifiques de performance et de précision, garantissant que la base de données peut s'adapter à une large gamme d'applications et de caractéristiques de données. L'expansion continue de ses offres d'index, par exemple l'index GPU, améliore encore l'adaptabilité et l'efficacité de Milvus dans la gestion des tâches de recherche complexes.
Capacités de Recherche Polyvalentes
Milvus offre une large gamme de types de recherche, y compris le Plus Proche Voisin Approximatif (ANN) top-K, l'ANN de plage et la recherche avec filtrage des métadonnées, ainsi que la recherche hybride de vecteurs denses et épars à venir. Cette diversité permet une flexibilité et une précision de requête inégalées, offrant aux développeurs la possibilité de personnaliser les stratégies de récupération des données pour répondre aux besoins spécifiques des applications, optimisant ainsi à la fois la pertinence et l'efficacité des résultats de recherche.
Cohérence Réglable
Milvus offre un modèle de cohérence delta qui permet aux utilisateurs de spécifier une "tolérance à l'obsolescence" pour les données de requête, permettant un équilibre personnalisé entre la performance des requêtes et la fraîcheur des données. Cette flexibilité est cruciale pour les applications nécessitant des résultats à jour sans sacrifier les temps de réponse, supportant efficacement à la fois une cohérence forte et éventuelle selon les besoins de l'application.
Support de Calcul Accéléré par Matériel
Milvus est conçu pour tirer parti de diverses capacités de calcul, telles que AVX512 et Neon pour l'exécution SIMD, ainsi que la quantification, les optimisations sensibles au cache et le support GPU. Cette approche permet une utilisation efficace des forces spécifiques du matériel, garantissant un traitement rapide et une évolutivité rentable. En adaptant l'utilisation des ressources aux besoins uniques des différentes applications, Milvus améliore à la fois la vitesse et l'efficacité de la gestion et des opérations de recherche des données vectorielles.
Comment fonctionne Milvus en résumé ?
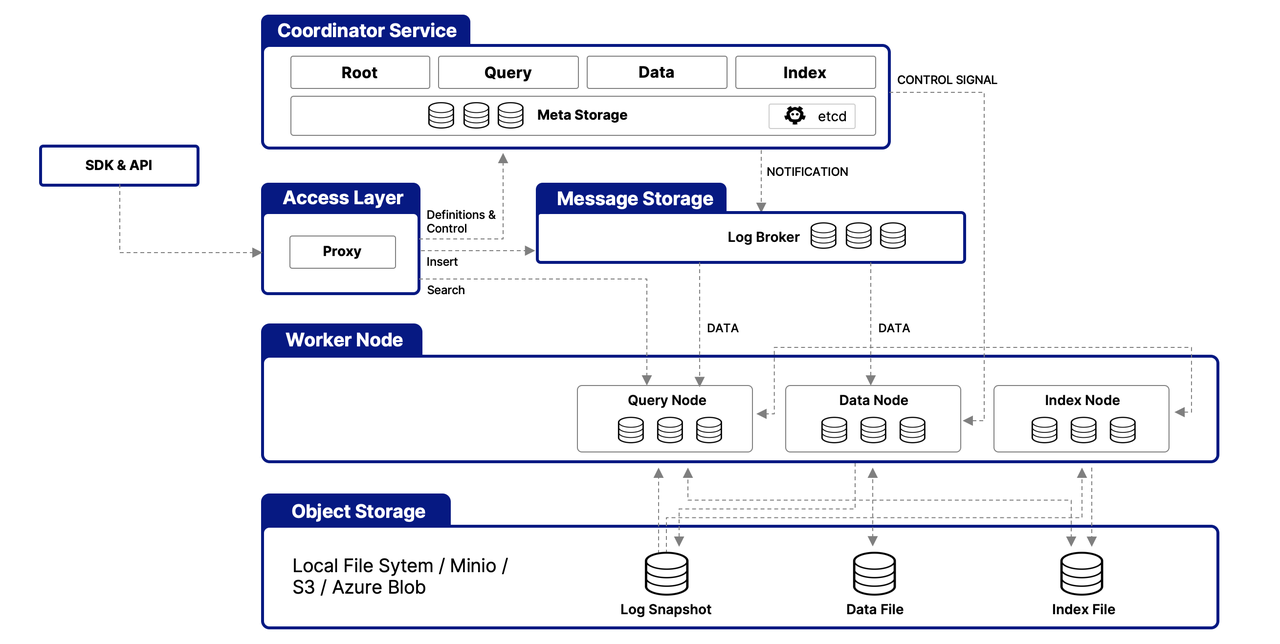
Milvus est structuré autour d'une architecture multicouche conçue pour gérer et traiter efficacement les données vectorielles, garantissant l'évolutivité, l'adaptabilité et l'isolation des données. Voici un aperçu simplifié de son architecture :
Couche d'Accès
Cette couche sert de point de contact initial pour les requêtes externes, utilisant des proxys sans état pour la gestion des connexions clients, la vérification statique et les contrôles dynamiques. Ces proxys gèrent également l'équilibrage de charge et sont essentiels pour la mise en œuvre de la suite d'API complète de Milvus. Une fois que le service en aval traite une requête, la couche d'accès achemine la réponse à l'utilisateur.
Service de Coordination
Agissant comme commande centrale, ce service orchestre l'équilibrage de charge et la gestion des données via quatre coordinateurs, assurant une gestion efficace des données, des requêtes et des index.
The Root Coordinator: managing data-related tasks and global timestamps
The Query Coordinator: overseeing query nodes for search operations
The Data Coordinator: handling data nodes and metadata
The Index Coordinator: maintaining index nodes and metadata
Nœuds de Travail
Responsables de l'exécution réelle des tâches, les nœuds de travail sont des pods évolutifs qui exécutent les commandes des coordinateurs. Ils permettent à Milvus de s'adapter dynamiquement aux demandes changeantes de données, de requêtes et d'indexation, supportant l'évolutivité et l'adaptabilité du système.
Couche de Stockage d'Objets
Fondamentale pour la persistance des données, cette couche se compose de :
Meta store: using etcd for metadata snapshots and system health checks
Log broker: for streaming data persistence and recovery, utilizing Pulsar or RocksDB
Object storage: storing log snapshots, index files, and query results, with support for services like AWS S3, Azure Blob Storage, and MinIO
Où aller à partir d'ici ?
- To get hands-on experience with Milvus, follow the get started guide.
- To understand Milvus in more detail, read the Documentation.
- Browse through the Use Cases to learn how other users in our worldwide community are getting value from Milvus.
Join a local Unstructured Data meetup and our Discord.