¿Qué es Milvus?
Todo lo que necesitas saber sobre Milvus en menos de 10 minutos.
¿Qué son los embeddings de vectores?
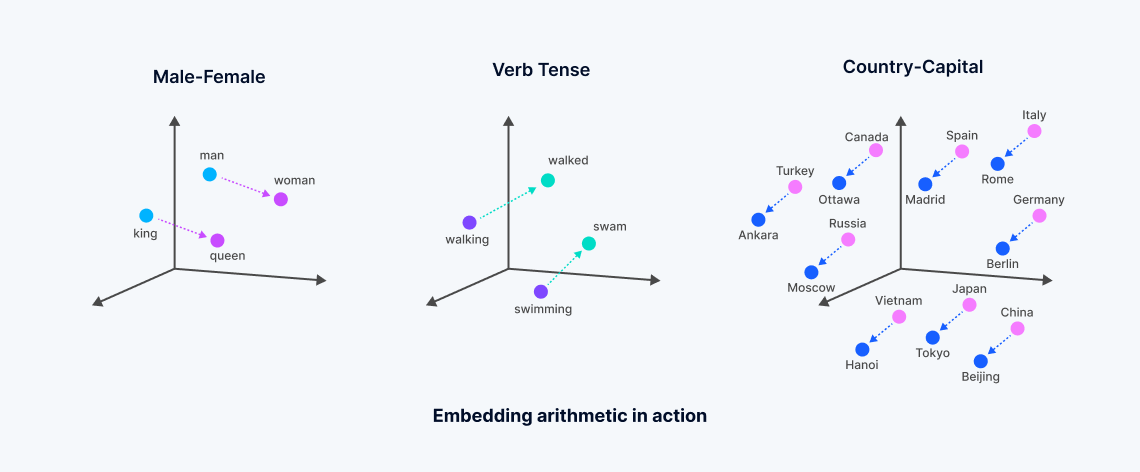
Los embeddings de vectores son representaciones numéricas derivadas de modelos de aprendizaje automático, que encapsulan el significado semántico de datos no estructurados. Estos embeddings se generan a través del análisis de correlaciones complejas dentro de los datos por redes neuronales o arquitecturas transformadoras, creando un espacio vectorial denso donde cada punto corresponde al "significado" de los objetos de datos, como palabras en un documento.
Este proceso transforma datos textuales u otros datos no estructurados en vectores que reflejan similitudes semánticas; las palabras con significados relacionados se posicionan más cerca en este espacio multidimensional, facilitando un tipo de búsqueda conocida como "búsqueda de vectores densos". Esto contrasta con la búsqueda tradicional de palabras clave, que se basa en coincidencias exactas y utiliza vectores dispersos. El desarrollo de embeddings de vectores, a menudo derivados de modelos fundamentales entrenados extensivamente por grandes empresas tecnológicas, permite búsquedas más matizadas que capturan la esencia de los datos, superando las limitaciones de los métodos de búsqueda de vectores dispersos o léxicos.
¿Para qué puedo usar los embeddings de vectores?
Los embeddings de vectores pueden ser utilizados en diversas aplicaciones, mejorando la eficiencia y precisión de varias maneras. Aquí están algunos de los casos de uso más frecuentes:
Encontrar Imágenes, Videos o Archivos de Audio Similares
Los embeddings de vectores permiten buscar contenido multimedia similar por contenido en lugar de solo palabras clave, utilizando Redes Neuronales Convolucionales (CNN) para analizar imágenes, fotogramas de video o segmentos de audio. Esto permite búsquedas avanzadas, como encontrar imágenes basadas en pistas de sonido o videos a través de consultas de imágenes, comparando las representaciones incrustadas almacenadas en bases de datos de vectores.
Acelerar el Descubrimiento de Medicamentos
En la industria farmacéutica, los embeddings de vectores pueden codificar estructuras químicas de compuestos, facilitando la identificación de candidatos prometedores para medicamentos al medir su similitud con proteínas objetivo. Esto acelera el proceso de descubrimiento de medicamentos, ahorrando tiempo y recursos al enfocarse en las pistas más viables.
Mejorar la Relevancia de la Búsqueda con Búsqueda Semántica
Al incrustar documentos internos en vectores, las organizaciones pueden aprovechar la búsqueda semántica para mejorar la relevancia de los resultados de búsqueda. Este método utiliza el concepto de Generación Aumentada por Recuperación (RAG) para comprender la intención detrás de las consultas, proporcionando respuestas a partir de los datos de una empresa a través de modelos de IA como ChatGPT, reduciendo así resultados irrelevantes y alucinaciones de IA.
Sistemas de Recomendación
Los embeddings de vectores revolucionan los sistemas de recomendación al representar usuarios e ítems como embeddings para medir la similitud. Este enfoque permite recomendaciones personalizadas basadas en preferencias individuales, mejorando la satisfacción y el compromiso del usuario con las plataformas en línea.
Detección de Anomalías
En campos como la detección de fraudes, la seguridad de la red y el monitoreo industrial, los embeddings de vectores son instrumentales para identificar patrones inusuales. Los puntos de datos representados como embeddings permiten detectar anomalías calculando distancias o disimilitudes, facilitando la identificación temprana y medidas preventivas contra posibles problemas.
¿Qué son las bases de datos vectoriales?
Las bases de datos de vectores son sistemas especializados diseñados para gestionar y recuperar datos no estructurados a través de embeddings de vectores y representaciones numéricas que capturan la esencia de los elementos de datos como imágenes, audio, videos y contenido textual. A diferencia de las bases de datos relacionales tradicionales que manejan datos estructurados con operaciones de búsqueda precisas, las bases de datos de vectores sobresalen en búsquedas de similitud semántica utilizando técnicas como el algoritmo de Vecino Más Cercano Aproximado (ANN). Esta capacidad es crucial para desarrollar aplicaciones en diversos dominios, incluyendo sistemas de recomendación, chatbots y herramientas de búsqueda de contenido multimedia, y para abordar los desafíos planteados por la IA y los grandes modelos de lenguaje como ChatGPT, como comprender el contexto y las sutilezas y la alucinación de la IA.
La aparición de bases de datos de vectores como Milvus está transformando industrias al permitir búsquedas basadas en contenido en una amplia gama de datos no estructurados, superando las limitaciones de las etiquetas generadas por humanos. Las características clave que distinguen a las bases de datos de vectores incluyen
Escalabilidad y ajustabilidad para manejar volúmenes de datos crecientes
Multitenencia y aislamiento de datos para un uso eficiente de los recursos y la privacidad
Una suite completa de APIs para diversos lenguajes de programación
Interfaces fáciles de usar que simplifican la interacción con datos complejos.
Estos atributos aseguran que las bases de datos de vectores puedan satisfacer las demandas de las aplicaciones modernas, ofreciendo herramientas poderosas para explorar y aprovechar datos no estructurados de maneras que las bases de datos tradicionales no pueden.
Base de Datos de Vectores vs. Biblioteca de Búsqueda de Vectores
Las bibliotecas de búsqueda de vectores como FAISS, ScaNN y HNSW ofrecen herramientas fundamentales para construir sistemas prototipo capaces de realizar búsquedas de similitud eficientes y agrupamiento de vectores densos. Estas bibliotecas, aunque potentes y de código abierto, están diseñadas principalmente para la recuperación de vectores y ofrecen una configuración rápida con capacidades como manejar grandes colecciones de vectores y proporcionar interfaces para evaluación y ajuste de parámetros. Sin embargo, carecen de escalabilidad, multitenencia y modificación dinámica de datos, lo que las hace menos adecuadas para conjuntos de datos más grandes y complejos y bases de usuarios en crecimiento.
En contraste, las bases de datos de vectores emergen como una solución más completa diseñada para acomodar el almacenamiento y la recuperación en tiempo real de millones a miles de millones de vectores. Proporcionan un nivel más alto de abstracción, escalabilidad, natividad en la nube y características fáciles de usar que superan las funcionalidades básicas de las bibliotecas de búsqueda de vectores. Si bien las bibliotecas como FAISS son componentes integrales sobre los cuales las bases de datos de vectores pueden construirse, estas últimas son servicios completos que simplifican operaciones como la inserción y gestión de datos, alineándose más con las demandas de aplicaciones dinámicas y a gran escala en el ámbito del procesamiento de datos no estructurados.
Bases de Datos de Vectores vs. Plugins de Búsqueda de Vectores para Bases de Datos Tradicionales
Las bases de datos de vectores y los plugins de búsqueda de vectores para bases de datos tradicionales cumplen roles distintos en el manejo de búsquedas basadas en vectores. Los plugins como los de Elasticsearch 8.0 ofrecen capacidades de búsqueda de vectores dentro de las arquitecturas de bases de datos existentes, funcionando como mejoras en lugar de soluciones completas. Estos plugins carecen de un enfoque de pila completa para la gestión de embeddings y la búsqueda de vectores, resultando en limitaciones y un rendimiento subóptimo para aplicaciones de datos no estructurados.
Características clave como la ajustabilidad y APIs/SDKs fáciles de usar, esenciales para la operación efectiva de la base de datos de vectores, están notablemente ausentes en los plugins de búsqueda de vectores. Por ejemplo, el motor ANN de Elasticsearch, aunque soporta almacenamiento y consulta básica de vectores, está limitado por su algoritmo de indexación y opciones de métricas de distancia, ofreciendo menos flexibilidad en comparación con una base de datos de vectores dedicada como Milvus. Milvus, diseñada desde cero como una base de datos de vectores, proporciona una API más intuitiva, un soporte más amplio para métodos de indexación y métricas de distancia, y el potencial para consultas tipo SQL, destacando su superioridad en la gestión y consulta de datos no estructurados. Esta diferencia fundamental subraya por qué las bases de datos de vectores, con sus conjuntos de características completos y arquitectura adaptada para datos no estructurados, son preferidas sobre los plugins de búsqueda de vectores para lograr una búsqueda y gestión óptima de embeddings de vectores.
¿Cómo se diferencia Milvus de otras bases de datos de vectores?
Milvus se destaca como una base de datos de vectores con su arquitectura escalable y diversas capacidades diseñadas para acelerar y unificar experiencias de búsqueda en diversas aplicaciones. Las características clave incluyen:
Arquitectura Escalable y Elástica
Milvus está diseñada para una escalabilidad y elasticidad excepcionales, adaptándose a las demandas dinámicas de las aplicaciones modernas. Lo logra a través de un diseño orientado a servicios, desacoplando el almacenamiento, los coordinadores y los trabajadores, permitiendo una escalabilidad por componentes. Este enfoque modular asegura que diferentes tareas computacionales puedan escalar de manera independiente según las cargas de trabajo variables, proporcionando una asignación de recursos detallada y aislamiento.
Soporte de Índice Diverso
Milvus soporta una amplia variedad de más de 10 tipos de índices, incluyendo los ampliamente utilizados como HNSW, IVF, Cuantización de Productos y indexación basada en GPU. Esta variedad permite a los desarrolladores optimizar las búsquedas según requisitos específicos de rendimiento y precisión, asegurando que la base de datos pueda adaptarse a una amplia gama de aplicaciones y características de datos. La expansión continua de sus ofertas de índices, por ejemplo, el índice GPU, mejora aún más la adaptabilidad y efectividad de Milvus en el manejo de tareas de búsqueda complejas.
Capacidades de Búsqueda Versátiles
Milvus ofrece una amplia gama de tipos de búsqueda, incluyendo Top-K Vecino Más Cercano Aproximado (ANN), ANN de Rango y búsqueda con filtrado de metadatos, y la próxima búsqueda híbrida de vectores densos y dispersos. Esta diversidad permite una flexibilidad y precisión de consulta sin igual, otorgando a los desarrolladores la capacidad de personalizar estrategias de recuperación de datos para satisfacer demandas específicas de aplicaciones, optimizando así tanto la relevancia como la eficiencia de los resultados de búsqueda.
Consistencia Ajustable
Milvus ofrece un modelo de consistencia delta que permite a los usuarios especificar una "tolerancia a la antigüedad" para los datos de consulta, permitiendo un equilibrio personalizado entre el rendimiento de la consulta y la frescura de los datos. Esta flexibilidad es crucial para aplicaciones que requieren resultados actualizados sin sacrificar tiempos de respuesta, respaldando tanto la consistencia fuerte como eventual según las necesidades de la aplicación.
Soporte de Computación Acelerada por Hardware
Milvus está diseñado para aprovechar diversos tipos de capacidades de computación, como AVX512 y Neon para ejecución SIMD, junto con cuantización, optimizaciones conscientes de caché y soporte de GPU. Este enfoque permite una utilización eficiente de las fortalezas específicas del hardware, asegurando un procesamiento rápido y una escalabilidad rentable. Al adaptar el uso de recursos a las demandas únicas de diferentes aplicaciones, Milvus mejora tanto la velocidad como la eficiencia de la gestión y las operaciones de búsqueda de datos de vectores.
¿Cómo funciona Milvus en resumen?
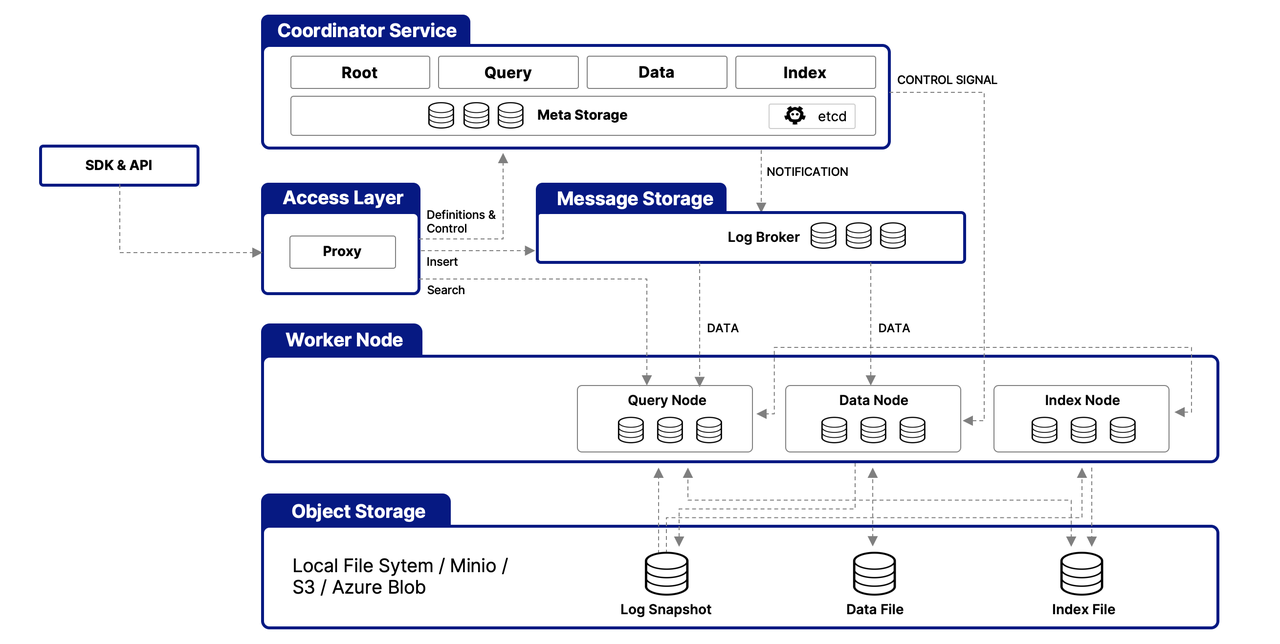
Milvus está estructurado alrededor de una arquitectura multicapa diseñada para manejar y procesar datos de vectores de manera eficiente, asegurando escalabilidad, ajustabilidad y aislamiento de datos. Aquí tienes una visión general simplificada de su arquitectura:
Capa de Acceso
Esta capa sirve como el punto de contacto inicial para solicitudes externas, utilizando proxies sin estado para la gestión de conexiones de clientes, verificación estática y verificaciones dinámicas. Estos proxies también manejan el balanceo de carga y son clave para implementar la suite completa de APIs de Milvus. Una vez que el servicio downstream procesa una solicitud, la capa de acceso enruta la respuesta de vuelta al usuario.
Servicio Coordinador
Actuando como el comando central, este servicio orquesta el balanceo de carga y la gestión de datos a través de cuatro coordinadores, que aseguran una gestión eficiente de datos, consultas e índices.
The Root Coordinator: managing data-related tasks and global timestamps
The Query Coordinator: overseeing query nodes for search operations
The Data Coordinator: handling data nodes and metadata
The Index Coordinator: maintaining index nodes and metadata
Nodos Trabajadores
Responsables de la ejecución real de tareas, los nodos trabajadores son pods escalables que llevan a cabo comandos de los coordinadores. Permiten que Milvus se adapte dinámicamente a las cambiantes demandas de datos, consultas e indexación, apoyando la escalabilidad y ajustabilidad del sistema.
Capa de Almacenamiento de Objetos
Fundamental para la persistencia de datos, esta capa consiste en
Meta store: using etcd for metadata snapshots and system health checks
Log broker: for streaming data persistence and recovery, utilizing Pulsar or RocksDB
Object storage: storing log snapshots, index files, and query results, with support for services like AWS S3, Azure Blob Storage, and MinIO
¿A dónde ir desde aquí?
- To get hands-on experience with Milvus, follow the get started guide.
- To understand Milvus in more detail, read the Documentation.
- Browse through the Use Cases to learn how other users in our worldwide community are getting value from Milvus.
Join a local Unstructured Data meetup and our Discord.