Milvus Was Built for Massive-Scale (Think Trillion) Vector Similarity Search
Every day, an incalculable number of business-critical insights are squandered because companies can’t make sense of their own data. Unstructured data, such as text, image, video, and audio, is estimated to account for 80% of all data — but just 1% of it is ever analyzed. Fortunately, artificial intelligence (AI), open-source software, and Moore’s law are making machine-scale analytics more accessible than ever before. Using vector similarity search, it is possible to extract value from massive unstructured datasets. This technique involves converting unstructured data into feature vectors, a machine-friendly numerical data format that can be processed and analyzed in real time.
Vector similarity search has applications spanning e-commerce, security, new drug development, and more. These solutions rely on dynamic datasets containing millions, billions, or even trillions of vectors, and their usefulness often depends on returning near instantaneous results. Milvus is an open-source vector data management solution built from the ground up for efficiently managing and searching large vector datasets. This article covers Milvus’ approach to vector data management, as well as how the platform has been optimized for vector similarity search.
Jump to:
- Milvus Was Built for Massive-Scale (Think Trillion) Vector Similarity Search
- LSM trees keep dynamic data management efficient at massive scales - A segment of 10-dimensional vectors in Milvus.
- Data management is optimized for rapid access and limited fragmentation - An illustration of inserting vectors in Milvus. - Queried data files before the merge. - Queried data files after the merge.
- Similarity searched is accelerated by indexing vector data
- Learn more about Milvus
LSM trees keep dynamic data management efficient at massive scales
To provide efficient dynamic data management, Milvus uses a log-structured merge-tree (LSM tree) data structure. LSM trees are well suited for accessing data that has a high number of inserts and deletes. For detailed information on specific attributes of LSM trees that help ensure high-performance dynamic data management, see the original research published by its inventors. LSM trees are the underlying data structure used by many popular databases, including BigTable, Cassandra, and RocksDB.
Vectors exist as entities in Milvus and are stored in segments. Each segment contains anywhere from one up to ~8 million entities. Each entity has fields for a unique ID and vector inputs, with the latter representing anywhere from 1 to 32768 dimensions.
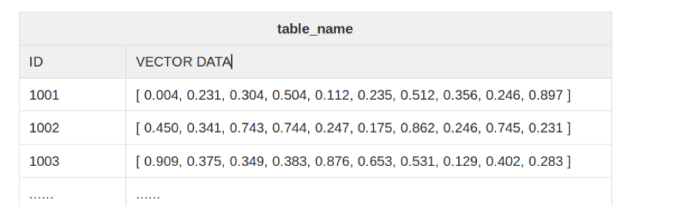 Blog_Milvus Was Built for Massive-Scale (Think Trillion) Vector Similarity Search_2.png
Blog_Milvus Was Built for Massive-Scale (Think Trillion) Vector Similarity Search_2.png
Data management is optimized for rapid access and limited fragmentation
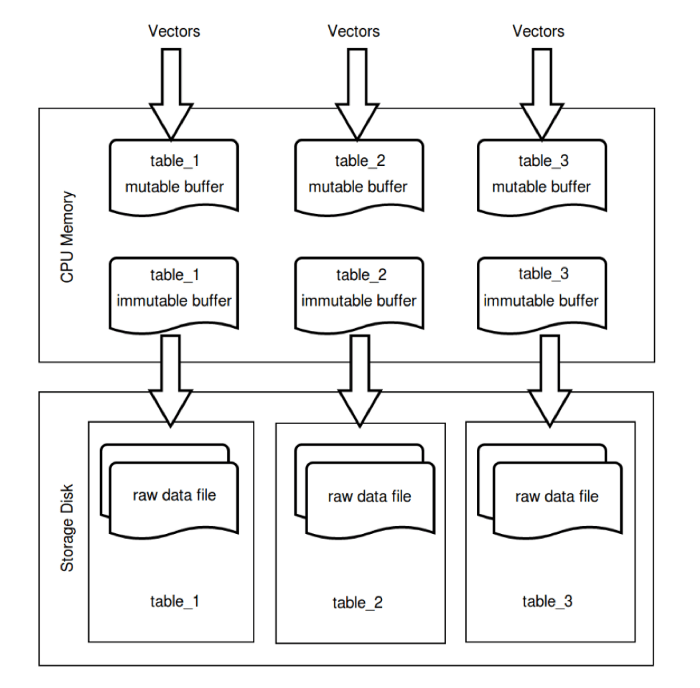
When receiving an insert request, Milvus writes new data to the write ahead log (WAL). After the request is successfully recorded to the log file, the data is written to a mutable buffer. Finally, one of three triggers results in the buffer becoming immutable and flushing to disk:
- Timed intervals: Data is regularly flushed to disk at defined intervals (1 second by default).
- Buffer size: Accumulated data reaches the upper limit for the mutable buffer (128 MB).
- Manual trigger: Data is manually flushed to disk when the client calls the flush function.
 Blog_Milvus Was Built for Massive-Scale (Think Trillion) Vector Similarity Search_3.png
Blog_Milvus Was Built for Massive-Scale (Think Trillion) Vector Similarity Search_3.png
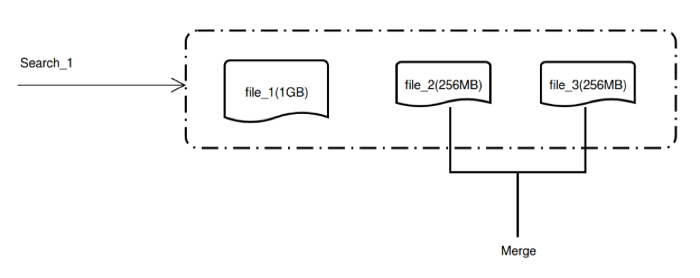
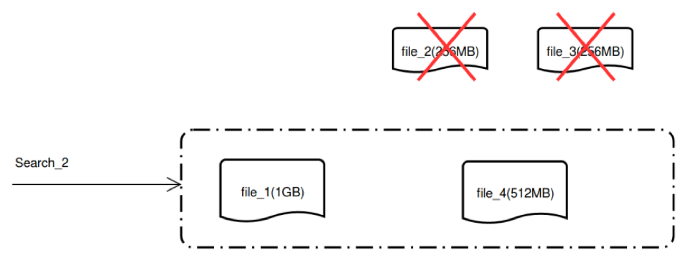
Users can add tens or millions of vectors at a time, generating data files of different sizes as new vectors are inserted. This results in fragmentation that can complicate data management and slow down vector similarity search. To prevent excessive data fragmentation, Milvus constantly merges data segments until the combined file size reaches a user configurable limit (e.g., 1 GB). For example, given an upper limit of 1 GB, inserting 100 million 512-dimensional vectors will result in just ~200 data files.
In incremental computation scenarios where vectors are inserted and searched concurrently, Milvus makes newly inserted vector data immediately available for search before merging it with other data. After data merges, the original data files will be removed and the newly created merged file will be used for search instead.
 Blog_Milvus Was Built for Massive-Scale (Think Trillion) Vector Similarity Search_4.png
Blog_Milvus Was Built for Massive-Scale (Think Trillion) Vector Similarity Search_4.png
 Blog_Milvus Was Built for Massive-Scale (Think Trillion) Vector Similarity Search_5.png
Blog_Milvus Was Built for Massive-Scale (Think Trillion) Vector Similarity Search_5.png
Similarity searched is accelerated by indexing vector data
By default, Milvus relies on brute-force search when querying vector data. Also known as exhaustive search, this approach checks all vector data each time a query is run. With datasets containing millions or billions of multi-dimensional vectors, this process is too slow to be useful in most similarity search scenarios. To help expedite query time, algorithms are used to build a vector index. The indexed data is clustered such that similar vectors are closer together, allowing the similarity search engine to query just a portion of the total data, drastically reducing query times while sacrificing accuracy.
Most of the vector index types supported by Milvus use approximate nearest neighbor (ANN) search algorithms. There are numerous ANN indexes, and each one comes with tradeoffs between performance, accuracy, and storage requirements. Milvus supports quantization-, graph, and tree-based indexes, all of which serve different application scenarios. See Milvus’ technical documentation for more information about building indexes and the specific types of vector indexes it supports.
Index building generates a lot of metadata. For example, indexing 100 million 512-dimensional vectors saved in 200 data files will result in an additional 200 index files. In order to efficiently check file statuses and delete or insert new files, an efficient metadata management system is required. Milvus uses online transactional processing (OLTP), a data processing technique that is well-suited for updating and/or deleting small amounts of data in a database. Milvus uses SQLite or MySQL to manage metadata.
Learn more about Milvus
Milvus is an open-source vector data management platform currently in incubation at LF AI & Data, an umbrella organization of the Linux Foundation. Milvus was made open source in 2019 by Zilliz, the data science software company that initiated the project. More information about Milvus can be found on its website. If you’re interested in vector similarity search, or using AI to unlock the potential of unstructured data, please join our open-source community on GitHub.
- LSM trees keep dynamic data management efficient at massive scales
- Data management is optimized for rapid access and limited fragmentation
- Similarity searched is accelerated by indexing vector data
- Learn more about Milvus
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word


