Item-based Collaborative Filtering for Music Recommender System
Wanyin App is an AI-based music sharing community with an intention to encourage music sharing and make music composition easier for music enthusiasts.
Wanyin’s library contains a massive amount of music uploaded by users. The primary task is to sort out the music of interest based on users’ previous behavior. We evaluated two classic models: user-based collaborative filtering (User-based CF) and item-based collaborative filtering (Item-based CF), as the potential recommender system models.
- User-based CF uses similarity statistics to obtain neighboring users with similar preferences or interests. With the retrieved set of nearest neighbors, the system can predict the interest of the target user and generate recommendations.
- Introduced by Amazon, item-based CF, or item-to-item (I2I) CF, is a well-known collaborative filtering model for recommender systems. It calculates similarities between items instead of users, based on the assumption that items of interest must be similar to the items of high scores.
User-based CF may lead to prohibitively longer time for calculation when the user number passes a certain point. Taking the characteristics of our product into consideration, we decided to go with I2I CF to implement the music recommender system. Given that we do not possess much metadata about the songs, we have to deal with the songs per se, extracting feature vectors (embeddings) from them. Our approach is to convert these songs into mel-frequency cepstrum (MFC), design a convolutional neural network (CNN) to extract the songs’ feature embeddings, and then make music recommendations through embedding similarity search.
🔎 Select an embedding similarity search engine
Now that we have feature vectors, the remaining issue is how to retrieve from the large volume of vectors the ones that are similar to the target vector. When it comes to embeddings search engine, we were weighing between Faiss and Milvus. I noticed Milvus when I was going through GitHub’s trending repositories in November, 2019. I took a look at the project and it appealed to me with its abstract APIs. (It was on v0.5.x by then and v0.10.2 by now.)
We prefer Milvus to Faiss. On the one hand, we have used Faiss before, and hence would like to try something new. One the other hand, compared to Milvus, Faiss is more of an underlying library, therefore not quite convenient to use. As we learned more about Milvus, we finally decided to adopt Milvus for its two main features:
- Milvus is very easy to use. All you need to do is to pull its Docker image and update the parameters based on your own scenario.
- It supports more indexes and has detailed supporting documentation.
In a nutshell, Milvus is very friendly to users and the documentation is quite detailed. If you come across any problem, you can usually find solutions in the documentation; otherwise, you can always get support from the Milvus community.
Milvus cluster service ☸️ ⏩
After deciding to use Milvus as the feature vector search engine, we configured a standalone node in a development (DEV) environment. It had been running well for a few days, so we planned to run tests in a factory acceptance test (FAT) environment. If a standalone node crashed in production, the entire service would become unavailable. Thus, we need to deploy a highly available search service.
Milvus provides both Mishards, a cluster sharding middleware, and Milvus-Helm for configuration. The process of deploying a Milvus cluster service is simple. We only need to update some parameters and pack them for deployment in Kubernetes. The diagram below from Milvus’ documentation shows how Mishards works:
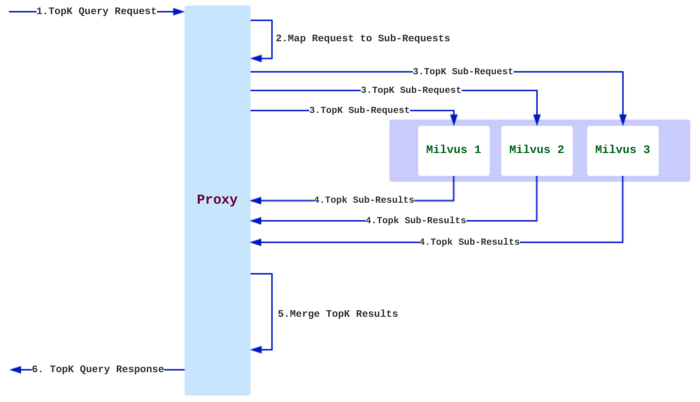 1-how-mishards-works-in-milvus-documentation.png
1-how-mishards-works-in-milvus-documentation.png
Mishards cascades a request from upstream down to its sub-modules splitting the upstream request, and then collects and returns the results of the sub-services to upstream. The overall architecture of the Mishards-based cluster solution is shown below:
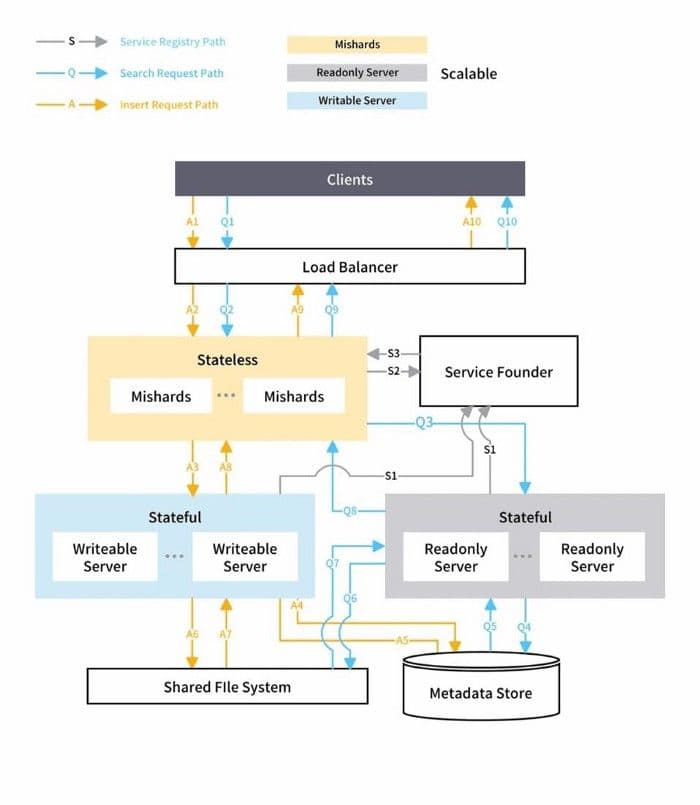 2-mishards-based-cluster-solution-architecture.jpg
2-mishards-based-cluster-solution-architecture.jpg
The official documentation provides a clear introduction of Mishards. You can refer to Mishards if you are interested.
In our music recommender system, we deployed one writable node, two read-only nodes, and one Mishards middleware instance in Kubernetes, using Milvus-Helm. After the service had been running stably in a FAT environment for a while, we deployed it in production. It has been stable so far.
🎧 I2I music recommendation 🎶
As mentioned above, we built Wanyin’s I2I music recommender system using the extracted embeddings of the existing songs. First, we separated the vocal and the BGM (track separation) of a new song uploaded by the user and extracted the BGM embeddings as the feature representation of the song. This also helps sort out cover versions of original songs. Next, we stored these embeddings in Milvus, searched for similar songs based on the songs that the user listened to, and then sorted and rearranged the retrieved songs to generate music recommendations. The implementation process is shown below:
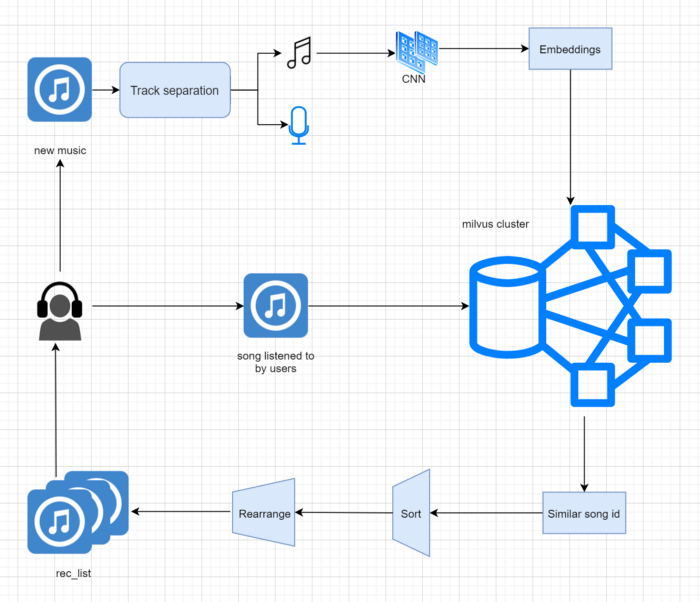 3-music-recommender-system-implementation.png
3-music-recommender-system-implementation.png
🚫 Duplicate song filter
Another scenario in which we use Milvus is duplicate song filtering. Some users upload the same song or clip several times, and these duplicate songs may appear in their recommendation list. This means that it would affect user experience to generate recommendations without pre-processing. Therefore, we need to find out the duplicate songs and ensure that they do not appear on the same list through pre-processing.
Another scenario in which we use Milvus is duplicate song filtering. Some users upload the same song or clip several times, and these duplicate songs may appear in their recommendation list. This means that it would affect user experience to generate recommendations without pre-processing. Therefore, we need to find out the duplicate songs and ensure that they do not appear on the same list through pre-processing.
Same with the previous scenario, we implemented duplicate song filtering by means of searching for similar feature vectors. First, we separated the vocal and the BGM and retrieved a number of similar songs using Milvus. In order to filter duplicate songs accurately, we extracted the audio fingerprints of the target song and the similar songs (with technologies such as Echoprint, Chromaprint, etc.), calculated the similarity between the audio fingerprint of the target song with each of the similar songs’ fingerprints. If the similarity goes beyond the threshold, we define a song as a duplicate of the target song. The process of audio fingerprint matching makes the filtering of duplicate songs more accurate, but it is also time-consuming. Therefore, when it comes to filtering songs in a massive music library, we use Milvus to filter our candidate duplicate songs as a preliminary step.
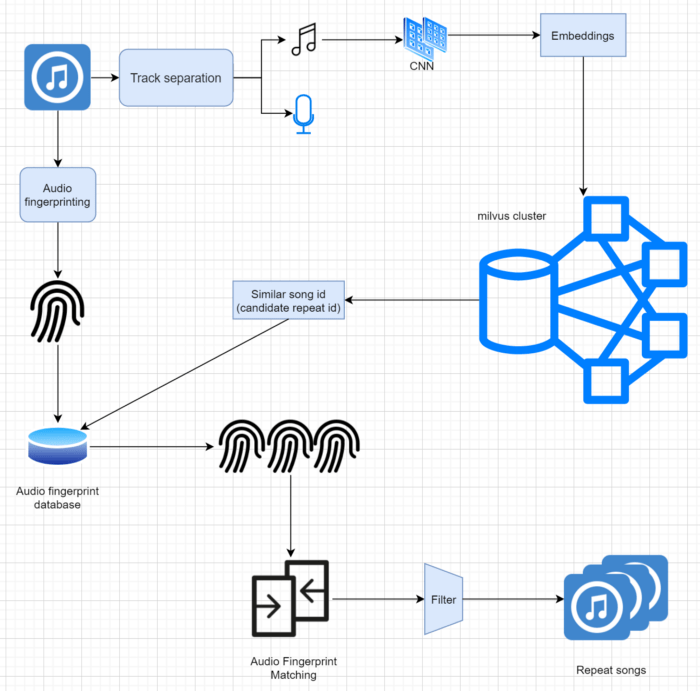 4-using-milvus-filter-songs-music-recommender-duplicates.png
4-using-milvus-filter-songs-music-recommender-duplicates.png
To implement the I2I recommender system for Wanyin’s massive music library, our approach is to extract the embeddings of songs as their feature, recall similar embeddings to the embedding of the target song, and then sort and rearrange the results to generate recommendation lists for the user. To achieve real-time recommendation, we choose Milvus over Faiss as our feature vector similarity search engine, since Milvus proves to be more user-friendly and sophisticated. By the same token, we have also applied Milvus to our duplicate song filter, which improves user experience and efficiency.
You can download Wanyin App 🎶 and try it out. (Note: might not be available on all app stores.)
📝 Authors:
Jason, Algorithm Engineer at Stepbeats Shiyu Chen, Data Engineer at Zilliz
📚 References:
Mishards Docs: https://milvus.io/docs/v0.10.2/mishards.md Mishards: https://github.com/milvus-io/milvus/tree/master/shards Milvus-Helm: https://github.com/milvus-io/milvus-helm/tree/master/charts/milvus
🤗 Don’t be a stranger, follow us on Twitter or join us on Slack!👇🏻
- 🔎 Select an embedding similarity search engine
- Milvus cluster service ☸️ ⏩
- 🎧 I2I music recommendation 🎶
- 🚫 Duplicate song filter
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



