聚類壓縮
聚類壓縮的目的是在大型資料集中改善搜尋效能並降低成本。本指南將協助您瞭解聚類壓縮以及此功能如何改善搜尋效能。
概述
Milvus 將傳入的實體儲存於集合中的區段,並在區段已滿時封閉該區段。如果發生這種情況,就會創建一個新的區段來容納額外的實體。因此,實體會任意地分佈在區段中。這種分佈方式需要 Milvus 搜尋多個區段,以找出與指定查詢向量最近的鄰居。
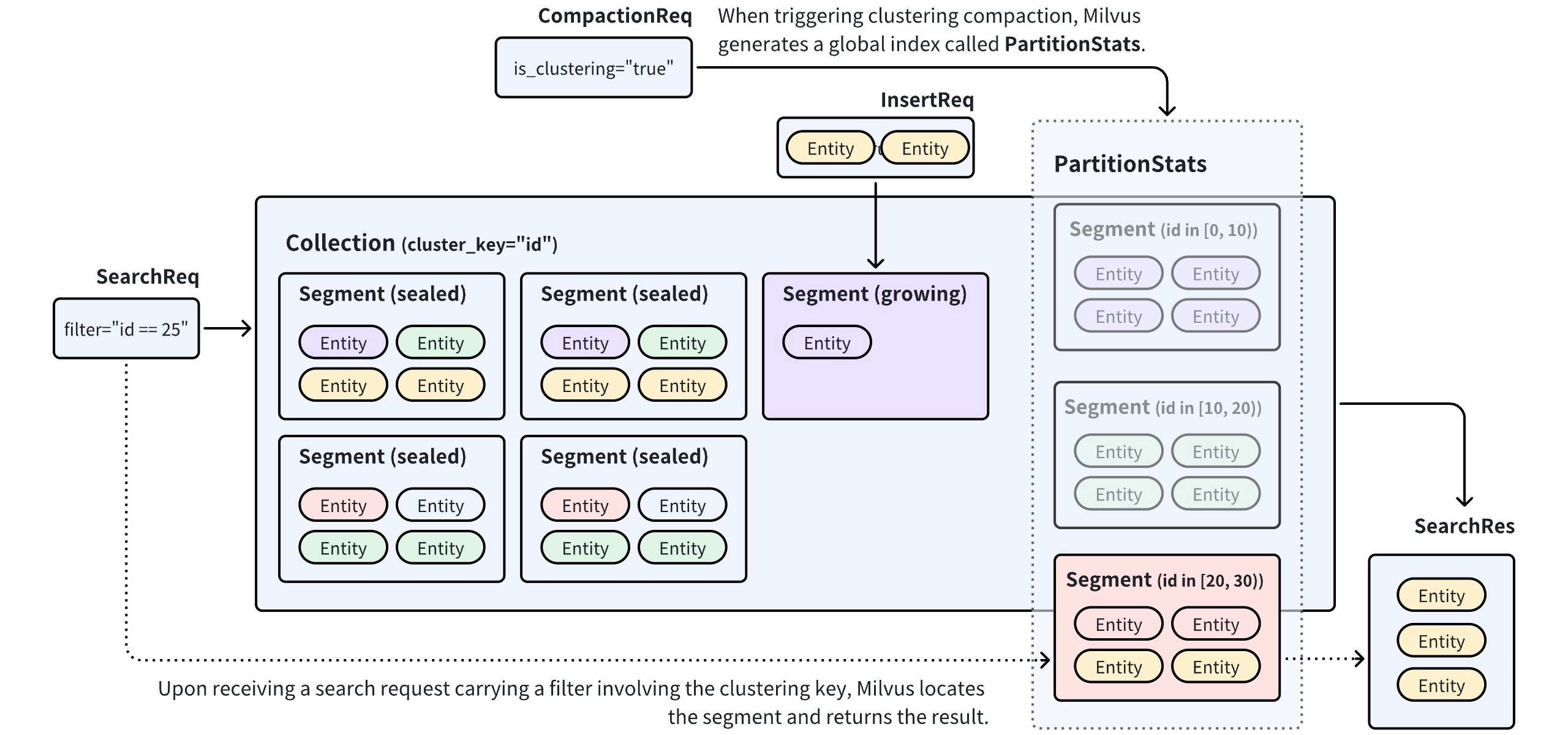 無聚類壓縮
無聚類壓縮
如果 Milvus 可以根據特定欄位中的值,將實體分佈在區段中,搜尋範圍就可以限制在一個區段內,進而改善搜尋效能。
聚類壓縮 (Clustering Compaction) 是 Milvus 的一項功能,可根據標量欄位中的值,在集合中的段之間重新分配實體。要啟用此功能,您首先需要選擇標量欄位作為聚類關鍵。這可讓 Milvus 在實體的聚類關鍵值在特定範圍內時,將實體重新分配到段中。當您觸發聚類壓縮時,Milvus 會產生/更新稱為PartitionStats 的全局索引,它會記錄段與聚類關鍵值之間的映射關係。
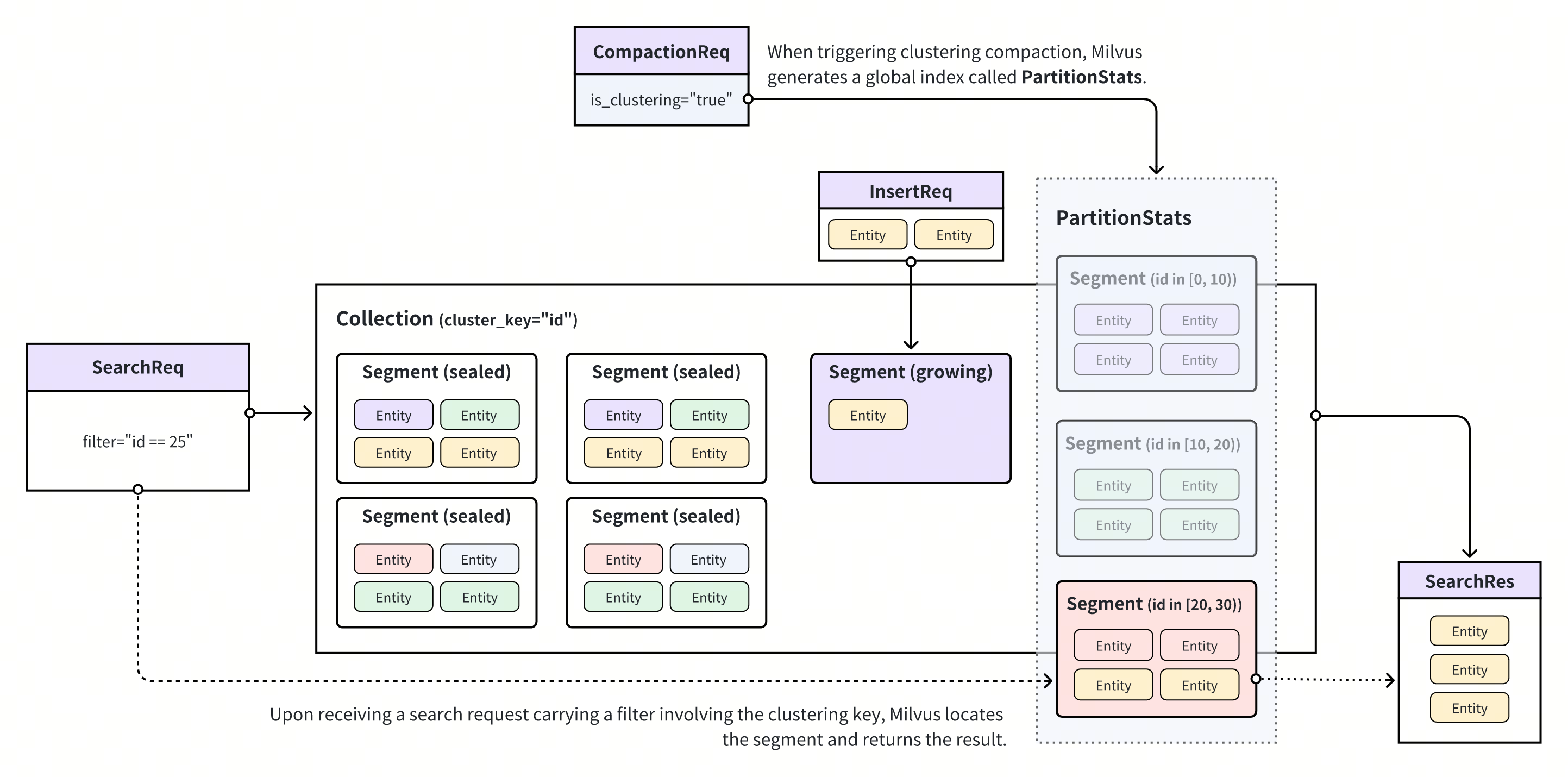 使用聚類壓縮
使用聚類壓縮
使用PartitionStats作為參考,Milvus 可以在接收到帶有聚類關鍵值的搜尋/查詢請求時,修剪不相關的資料,並將搜尋範圍限制在與該值對應的區段內,從而改善搜尋效能。有關效能改善的詳細資訊,請參閱基準測試。
使用聚類壓縮
Milvus 的聚類壓縮功能是高度可配置的。您可以選擇手動觸發,或設定為由 Milvus 每隔一段時間自動觸發。要啟用叢集壓縮,請執行下列步驟:
全局設定
您需要修改您的 Milvus 配置文件,如下所示。
dataCoord:
compaction:
clustering:
enable: true
autoEnable: false
triggerInterval: 600
minInterval: 3600
maxInterval: 259200
newDataSizeThreshold: 512m
timeout: 7200
queryNode:
enableSegmentPrune: true
datanode:
clusteringCompaction:
memoryBufferRatio: 0.1
workPoolSize: 8
common:
usePartitionKeyAsClusteringKey: true
dataCoord.compaction.clustering設定項目 說明 預設值 enable指定是否啟用叢集壓縮。
如果您需要為每個具有叢集索引鍵的集合啟用此功能,請將此設定為true。falseautoEnable指定是否啟用自動觸發壓縮。
將此設定為true表示 Milvus 會在指定的間隔壓縮具有叢集鍵的集合。falsetriggerInterval指定 Milvus 開始聚類壓縮的時間間隔,以毫秒為單位。
此參數僅在autoEnable設為true時有效。- minInterval以秒為單位指定最小間隔。
此參數僅在autoEnable設為true時有效。
將此設定為大於 triggerInterval 的整數,有助於避免在短時間內重複壓縮。- maxInterval指定最大間隔 (以秒為單位)。
此參數僅在autoEnable設為true時有效。
一旦 Milvus 偵測到一個集合沒有被叢集壓縮的時間超過這個值,它就會強制叢集壓縮。- newDataSizeThreshold指定觸發聚類壓縮的上限臨界值。
此參數僅在autoEnable設為true時有效。
一旦 Milvus 偵測到資料集中的資料量超過此值,就會啟動聚類壓縮程序。- timeout指定叢集壓縮的逾時長度。
如果集群壓縮的執行時間超過此值,則壓縮失敗。- queryNode設定項目 設定項目 預設值 enableSegmentPrune指定 Milvus 是否在收到搜尋/查詢請求時,參考 PartitionStats 來修剪資料。
將此設定為true可讓 Milvus 在搜尋/查詢請求期間修剪區段中的不相關資料。falsedataNode.clusteringCompaction設定項目 說明 預設值 memoryBufferRatio指定群集壓縮任務的記憶體緩衝比率。
當資料大小超過使用此比率計算的已分配緩衝區大小時,Milvus 會清除資料。- workPoolSize指定叢集壓縮任務的工作人員池大小。 - common設定項目 設定項目 預設值 usePartitionKeyAsClusteringKey指定是否使用集合中的分割區金鑰作為群集金鑰。
將此設定為true表示將分割區金鑰用作叢集金鑰。
您可以在集合中透過明確設定叢集索引鍵來覆寫此設定。false
要將上述變更套用到您的 Milvus 叢集,請遵循「使用 Helm 設定 Milvus」和「使用 Milvus Operators 設定 Milvus」中的步驟。
叢集設定
若要在特定的集合中進行群集壓縮,您應該從集合中選擇一個標量欄位作為群集鍵。
default_fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="key", dtype=DataType.INT64, is_clustering_key=True),
FieldSchema(name="var", dtype=DataType.VARCHAR, max_length=1000, is_primary=False),
FieldSchema(name="embeddings", dtype=DataType.FLOAT_VECTOR, dim=dim)
]
default_schema = CollectionSchema(
fields=default_fields,
description="test clustering-key collection"
)
coll1 = Collection(name="clustering_test", schema=default_schema)
您可以使用下列資料類型的標量欄位作為聚類關鍵:Int8,Int16,Int32,Int64,Float,Double, 以及VarChar 。
觸發聚類壓縮
如果您啟用了自動聚類壓縮,Milvus 會在指定的間隔自動觸發壓縮。另外,您也可以手動觸發壓縮,如下所示:
coll1.compact(is_clustering=True)
coll1.get_compaction_state(is_clustering=True)
coll1.wait_for_compaction_completed(is_clustering=True)
基準測試
資料量與查詢模式的結合,決定了叢集壓縮所能帶來的效能改善。一項內部基準測試證明,叢集壓縮可將每秒查詢次數 (QPS) 提升 25 倍。
該基準測試是在一個包含來自 2,000 萬個、768 維 LAION 資料集中的實體的集合上進行的,其中的關鍵欄位被指定為聚類關鍵。在集合中觸發聚類壓縮後,會發送並發搜尋,直到 CPU 使用量達到高水位為止。
| 搜尋篩選 | 剪除比率 | 延遲 (ms) | QPS (要求/秒) | ||||
|---|---|---|---|---|---|---|---|
| 平均值 | 最小值 | 最大值 | 中位數 | TP99 | |||
| 無 | 0% | 1685 | 672 | 2294 | 1710 | 2291 | 17.75 |
| 按鍵 > 200 且按鍵 < 800 | 40.2% | 1045 | 47 | 1828 | 1085 | 1617 | 28.38 |
| 鍵 > 200 且鍵 < 600 | 59.8% | 829 | 45 | 1483 | 882 | 1303 | 35.78 |
| 關鍵 > 200 且關鍵 < 400 | 79.5% | 550 | 100 | 985 | 584 | 898 | 54.00 |
| key == 1000 | 99% | 68 | 24 | 1273 | 70 | 246 | 431.41 |
隨著搜尋篩選器中的搜尋範圍縮小,剪枝比率也會增加。這表示在搜尋過程中,會跳過更多的實體。比較第一行和最後一行的統計資料時,您可以看到沒有進行聚類壓縮的搜尋需要掃描整個集合。另一方面,使用特定關鍵進行聚類壓縮的搜尋可達到 25 倍的改善。
最佳實務
以下是一些有效使用聚類壓縮的提示:
在資料量較大的資料集中啟用此功能。 搜尋效能會隨著資料集中的資料量增加而提升。對於超過 100 萬個實體的資料集,啟用此功能是個不錯的選擇。
選擇適當的聚類關鍵:您可以使用常被用來作為篩選條件的標量欄位作為聚類關鍵。對於包含來自多個租戶資料的集合,您可以使用區別一個租戶與另一個租戶的欄位作為簇集索引鍵。
使用分割區金鑰作為叢集金鑰。如果您想對 Milvus 實例中的所有集合啟用此功能,或者在使用分割區金鑰的大型集合中仍然面臨性能問題,則可以將
common.usePartitionKeyAsClusteringKey設為 true。這樣做之後,當您選擇一個集合中的標量欄位作為分割鍵時,就會有一個群集鍵和一個分割鍵。請注意,此設定不會阻止您選擇其他標量欄位作為叢集索引鍵。明確指定的簇集索引鍵總是優先。