Consistência
Este tópico introduz os quatro níveis de consistência no Milvus e os seus cenários mais adequados. O mecanismo por trás da garantia de consistência no Milvus também é abordado neste tópico.
Visão geral
A consistência em uma base de dados distribuída refere-se especificamente à propriedade que garante que cada nó ou réplica tenha a mesma visão dos dados ao escrever ou ler dados num determinado momento.
Milvus suporta quatro níveis de consistência: forte, staleness limitado, sessão e eventualmente. O nível de consistência padrão no Milvus é bounded staleness. É possível ajustar facilmente o nível de consistência ao realizar uma pesquisa de vetor único, uma pesquisa híbrida ou uma consulta para melhor se adequar à sua aplicação.
Níveis de consistência
Tal como definido pelo teorema PACELC, uma base de dados distribuída tem de fazer um compromisso entre consistência, disponibilidade e latência. Uma consistência elevada implica uma precisão elevada, mas também uma latência de pesquisa elevada, enquanto uma consistência baixa conduz a uma velocidade de pesquisa rápida, mas a uma certa perda de visibilidade dos dados. Por conseguinte, diferentes níveis de consistência adequam-se a diferentes cenários.
De seguida, explicamos as diferenças entre os quatro níveis de consistência suportados pelo Milvus e os cenários a que cada um se adequa.
Forte
Strong é o nível de consistência mais elevado e mais rigoroso. Garante que os utilizadores podem ler a versão mais recente dos dados.
 Consistência forte
Consistência forte
De acordo com o teorema PACELC, se o nível de consistência for definido como forte, a latência aumentará. Por conseguinte, recomendamos que escolha uma consistência forte durante os testes funcionais para garantir a exatidão dos resultados dos testes. A consistência forte também é mais adequada para aplicações que exigem rigorosamente a consistência dos dados à custa da velocidade de pesquisa. Um exemplo pode ser um sistema financeiro em linha que lida com pagamentos de encomendas e faturação.
Estabilidade limitada
A obsolescência limitada, como o próprio nome sugere, permite a inconsistência dos dados durante um determinado período de tempo. No entanto, geralmente, os dados são sempre globalmente consistentes fora desse período de tempo.
 Consistência da estanquidade limitada
Consistência da estanquidade limitada
A consistência limitada é adequada para cenários que necessitam de controlar a latência da pesquisa e podem aceitar a invisibilidade esporádica dos dados. Por exemplo, nos sistemas de recomendação, como os motores de recomendação de vídeo, a invisibilidade dos dados tem, por vezes, um pequeno impacto na taxa de recuperação global, mas pode aumentar significativamente o desempenho do sistema de recomendação.
Sessão
A sessão garante que todas as escritas de dados podem ser imediatamente percepcionadas em leituras durante a mesma sessão. Por outras palavras, quando se escrevem dados através de um cliente, os dados recém-inseridos tornam-se instantaneamente pesquisáveis.
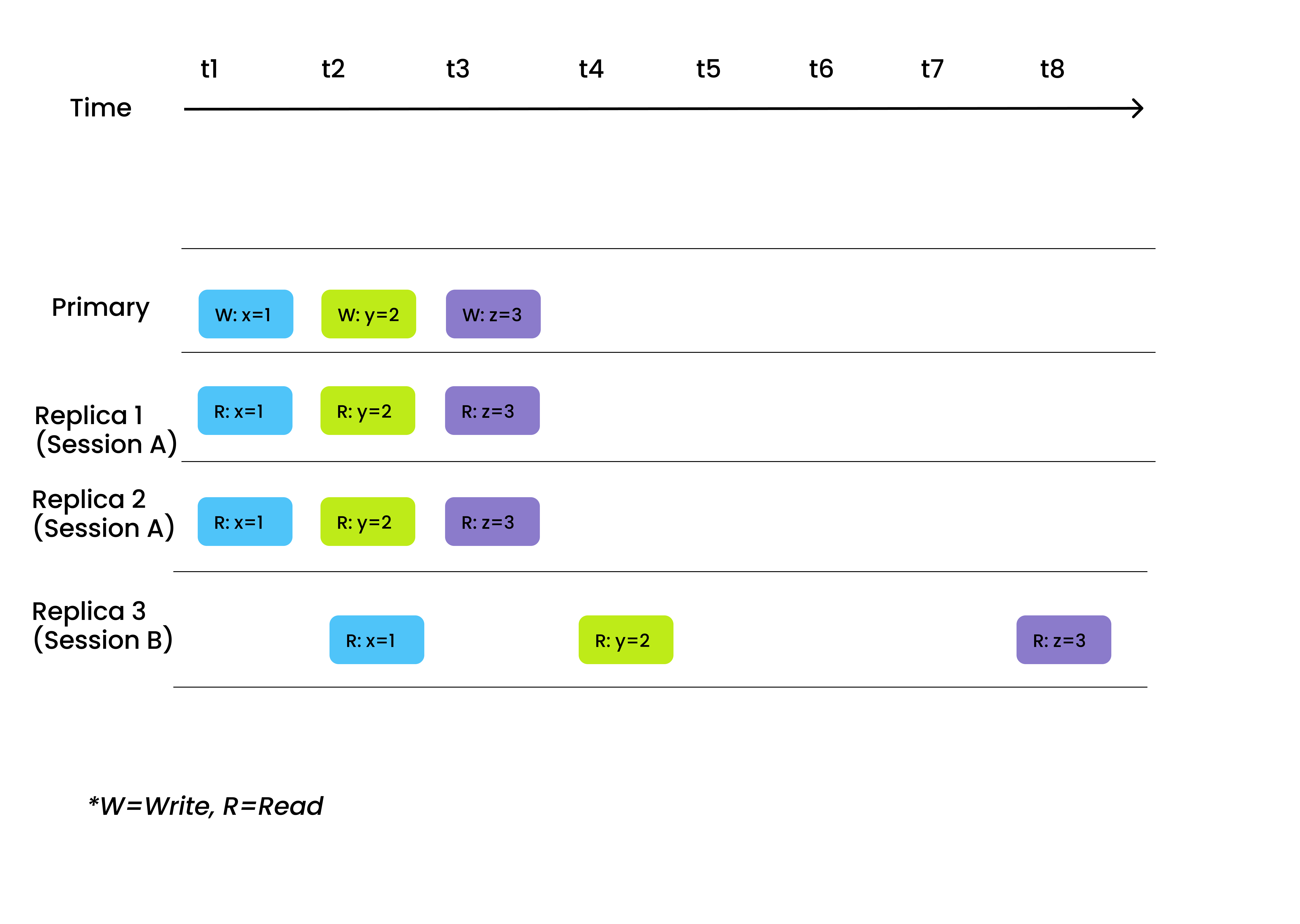 Consistência da sessão
Consistência da sessão
Recomendamos que escolha a sessão como nível de consistência para os cenários em que a exigência de consistência dos dados na mesma sessão é elevada. Um exemplo pode ser a eliminação dos dados de uma entrada de livro do sistema da biblioteca e, após confirmação da eliminação e atualização da página (uma sessão diferente), o livro já não deve estar visível nos resultados da pesquisa.
Eventualmente
Não existe uma ordem garantida de leituras e escritas, e as réplicas acabam por convergir para o mesmo estado, uma vez que não são efectuadas mais operações de escrita. Sob a consistência de "eventualmente", as réplicas começam a trabalhar nos pedidos de leitura com os valores actualizados mais recentes. Eventualmente consistente é o nível mais fraco entre os quatro.
 Consistência eventual
Consistência eventual
No entanto, de acordo com o teorema PACELC, a latência da pesquisa pode ser tremendamente reduzida com o sacrifício da consistência. Por conseguinte, a consistência eventual é mais adequada para cenários que não exigem muita consistência dos dados, mas requerem um desempenho de pesquisa extremamente rápido. Um exemplo pode ser a recuperação de críticas e classificações de produtos da Amazon com o nível de eventualmente consistente.
Carimbo de data/hora de garantia
O Milvus permite diferentes níveis de consistência através da introdução do carimbo de data/hora de garantia (GuaranteeTs).
Um GuaranteeTs serve para informar os nós de consulta que um pedido de pesquisa ou consulta não será efectuado até que todos os dados antes do GuaranteeTs possam ser vistos pelos nós de consulta. Ao especificar o nível de consistência, o nível de consistência será mapeado para um valor específico de GuaranteeTs. Diferentes valores de GuaranteeTs correspondem a diferentes níveis de consistência:
Forte: GuaranteeTs é definido como idêntico ao carimbo de data/hora mais recente do sistema, e os nós de consulta aguardam até que todos os dados antes do carimbo de data/hora mais recente do sistema possam ser vistos, antes de processar a solicitação de pesquisa ou consulta.
Staleness limitado: O GuaranteeTs é definido como relativamente menor do que o carimbo de data/hora mais recente do sistema, e os nós de consulta pesquisam numa vista de dados tolerável e menos actualizada.
Sessão: O cliente utiliza o carimbo de data/hora da última operação de escrita como GuaranteeTs, para que cada cliente possa, pelo menos, recuperar os dados inseridos pelo mesmo cliente.
Eventualmente: GuaranteeTs é definido para um valor muito pequeno para saltar a verificação de consistência. Os nós de consulta pesquisam imediatamente na visualização de dados existente.
Veja Como funciona o GuaranteeTs para mais informações sobre o mecanismo por trás da garantia de diferentes níveis de consistência no Milvus.
O que vem a seguir
- Saiba como ajustar o nível de consistência quando: