Spark-Milvus 커넥터 사용 가이드
Spark-Milvus 커넥터(https://github.com/zilliztech/spark-milvus)는 아파치 스파크의 데이터 처리 및 ML 기능과 밀버스의 벡터 데이터 저장 및 검색 기능을 결합하여 아파치 스파크와 밀버스 간의 원활한 통합을 제공합니다. 이러한 통합을 통해 다음과 같은 다양하고 흥미로운 애플리케이션을 구현할 수 있습니다:
- Milvus에 벡터 데이터를 대량으로 효율적으로 로드합니다,
- Milvus와 다른 스토리지 시스템 또는 데이터베이스 간에 데이터 이동,
- Spark MLlib 및 기타 AI 도구를 활용하여 Milvus의 데이터 분석.
빠른 시작
준비
Spark-Milvus 커넥터는 Scala 및 Python 프로그래밍 언어를 지원합니다. 사용자는 Pyspark 또는 Spark-shell과 함께 사용할 수 있습니다. 이 데모를 실행하려면 다음 단계에 따라 Spark-Milvus 커넥터 종속성을 포함하는 Spark 환경을 설정하세요:
Apache Spark 설치(버전 >= 3.3.0)
공식 문서를 참조하여 Apache Spark를 설치할 수 있습니다.
spark-milvus jar 파일을 다운로드합니다.
wget https://github.com/zilliztech/spark-milvus/raw/1.0.0-SNAPSHOT/output/spark-milvus-1.0.0-SNAPSHOT.jar종속성 중 하나로 spark-milvus jar를 사용하여 Spark 런타임을 시작합니다.
Spark-Milvus 커넥터로 Spark 런타임을 시작하려면 다운로드한 spark-milvus를 명령에 종속 요소로 추가합니다.
pyspark
./bin/pyspark --jars spark-milvus-1.0.0-SNAPSHOT.jarspark-shell
./bin/spark-shell --jars spark-milvus-1.0.0-SNAPSHOT.jar
데모
이 데모에서는 벡터 데이터가 포함된 샘플 Spark 데이터 프레임을 생성하고 Spark-Milvus 커넥터를 통해 Milvus에 씁니다. 스키마와 지정된 옵션에 따라 Milvus에 컬렉션이 자동으로 생성됩니다.
from pyspark.sql import SparkSession
columns = ["id", "text", "vec"]
data = [(1, "a", [1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0]),
(2, "b", [1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0]),
(3, "c", [1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0]),
(4, "d", [1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0])]
sample_df = spark.sparkContext.parallelize(data).toDF(columns)
sample_df.write \
.mode("append") \
.option("milvus.host", "localhost") \
.option("milvus.port", "19530") \
.option("milvus.collection.name", "hello_spark_milvus") \
.option("milvus.collection.vectorField", "vec") \
.option("milvus.collection.vectorDim", "8") \
.option("milvus.collection.primaryKeyField", "id") \
.format("milvus") \
.save()
import org.apache.spark.sql.{SaveMode, SparkSession}
object Hello extends App {
val spark = SparkSession.builder().master("local[*]")
.appName("HelloSparkMilvus")
.getOrCreate()
import spark.implicits._
// Create DataFrame
val sampleDF = Seq(
(1, "a", Seq(1.0,2.0,3.0,4.0,5.0)),
(2, "b", Seq(1.0,2.0,3.0,4.0,5.0)),
(3, "c", Seq(1.0,2.0,3.0,4.0,5.0)),
(4, "d", Seq(1.0,2.0,3.0,4.0,5.0))
).toDF("id", "text", "vec")
// set milvus options
val milvusOptions = Map(
"milvus.host" -> "localhost" -> uri,
"milvus.port" -> "19530",
"milvus.collection.name" -> "hello_spark_milvus",
"milvus.collection.vectorField" -> "vec",
"milvus.collection.vectorDim" -> "5",
"milvus.collection.primaryKeyField", "id"
)
sampleDF.write.format("milvus")
.options(milvusOptions)
.mode(SaveMode.Append)
.save()
}
위 코드를 실행한 후, 밀버스에서 삽입된 데이터를 SDK 또는 Attu(밀버스 대시보드)를 통해 확인할 수 있습니다. 4개의 엔티티가 이미 삽입된 hello_spark_milvus 라는 이름의 컬렉션을 확인할 수 있습니다.
기능 및 개념
Milvus 옵션
빠른 시작 섹션에서는 Milvus로 작업하는 동안 설정 옵션을 표시했습니다. 이러한 옵션은 Milvus 옵션으로 추상화되어 있습니다. 이 옵션은 Milvus에 대한 연결을 생성하고 다른 Milvus 동작을 제어하는 데 사용됩니다. 모든 옵션이 필수인 것은 아닙니다.
| 옵션 키 | 기본값 | 설명 |
|---|---|---|
milvus.host | localhost | Milvus 서버 호스트. 자세한 내용은 Milvus 연결 관리를 참조하세요. |
milvus.port | 19530 | Milvus 서버 포트. 자세한 내용은 Milvus 연결 관리를 참조하십시오. |
milvus.username | root | Milvus 서버의 사용자명. 자세한 내용은 Milvus 연결 관리를 참조하십시오. |
milvus.password | Milvus | Milvus 서버의 비밀번호. 자세한 내용은 Milvus 연결 관리를 참조하십시오. |
milvus.uri | -- | Milvus 서버 URI. 자세한 내용은 Milvus 연결 관리를 참조하십시오. |
milvus.token | -- | Milvus 서버 토큰. 자세한 내용은 Milvus 연결 관리를 참조하십시오. |
milvus.database.name | default | 읽거나 쓸 Milvus 데이터베이스의 이름입니다. |
milvus.collection.name | hello_milvus | 읽거나 쓸 Milvus 컬렉션의 이름입니다. |
milvus.collection.primaryKeyField | None | 컬렉션의 기본 키 필드 이름입니다. 컬렉션이 존재하지 않는 경우 필수입니다. |
milvus.collection.vectorField | None | 컬렉션의 벡터 필드 이름입니다. 컬렉션이 존재하지 않는 경우 필수입니다. |
milvus.collection.vectorDim | None | 컬렉션에 있는 벡터 필드의 차원입니다. 컬렉션이 존재하지 않는 경우 필수입니다. |
milvus.collection.autoID | false | 컬렉션이 존재하지 않는 경우 이 옵션은 엔티티의 ID를 자동으로 생성할지 여부를 지정합니다. 자세한 내용은 create_collection을 참조하세요. |
milvus.bucket | a-bucket | Milvus 스토리지의 버킷 이름입니다. 이 이름은 milvus.yaml의 minio.bucketName 와 동일해야 합니다. |
milvus.rootpath | files | Milvus 스토리지의 루트 경로. milvus.yaml의 minio.rootpath 와 동일해야 합니다. |
milvus.fs | s3a:// | Milvus 스토리지의 파일 시스템. s3a:// 값은 오픈 소스 Spark에 적용됩니다. 데이터브릭스에는 s3:// 을 사용합니다. |
milvus.storage.endpoint | localhost:9000 | Milvus 스토리지의 엔드포인트. 이는 milvus.yaml의 minio.address:minio.port 과 동일해야 합니다. |
milvus.storage.user | minioadmin | Milvus 스토리지의 사용자. milvus.yaml의 minio.accessKeyID 와 동일해야 합니다. |
milvus.storage.password | minioadmin | Milvus 스토리지의 비밀번호. milvus.yaml의 minio.secretAccessKey 와 동일해야 합니다. |
milvus.storage.useSSL | false | Milvus 스토리지에 SSL을 사용할지 여부입니다. 이 값은 milvus.yaml의 minio.useSSL 과 동일해야 합니다. |
Milvus 데이터 형식
Spark-Milvus 커넥터는 다음 Milvus 데이터 형식의 데이터 읽기 및 쓰기를 지원합니다:
milvus: Spark DataFrame에서 Milvus 엔티티로 원활하게 변환하기 위한 Milvus 데이터 형식입니다.milvusbinlog: Milvus 빌트인 빈로그 데이터를 읽기 위한 Milvus 데이터 형식.mjson: Milvus에 데이터를 대량 삽입하기 위한 Milvus JSON 형식입니다.
밀버스
빠른 시작에서는 Milvus 클러스터에 샘플 데이터를 쓰기 위해 milvus 형식을 사용합니다. 밀버스 형식은 밀버스 컬렉션에 Spark 데이터프레임 데이터를 원활하게 쓸 수 있도록 지원하는 새로운 데이터 형식입니다. 이는 Milvus SDK의 Insert API에 대한 일괄 호출을 통해 이루어집니다. Milvus에 컬렉션이 없는 경우, 데이터프레임의 스키마를 기반으로 새 컬렉션이 생성됩니다. 단, 자동 생성된 컬렉션은 컬렉션 스키마의 모든 기능을 지원하지 않을 수 있습니다. 따라서 먼저 SDK를 통해 컬렉션을 생성한 후, spark-milvus를 사용하여 작성하는 것을 권장합니다. 자세한 내용은 데모를 참조하세요.
밀버스빈로그
새로운 데이터 형식인 milvusbinlog는 Milvus에 내장된 binlog 데이터를 읽기 위한 것입니다. 빈로그는 쪽모이 세공을 기반으로 하는 Milvus의 내부 데이터 저장 형식입니다. 안타깝게도 일반 쪽모이 세공 라이브러리에서는 읽을 수 없기 때문에 Spark 작업에서 읽을 수 있도록 이 새로운 데이터 형식을 구현했습니다. 밀버스 내부 저장소 세부 정보에 익숙하지 않은 경우 milvusbinlog를 직접 사용하는 것은 권장하지 않습니다. 다음 섹션에서 소개할 MilvusUtils 함수를 사용하는 것이 좋습니다.
val df = spark.read
.format("milvusbinlog")
.load(path)
.withColumnRenamed("val", "embedding")
mjson
Milvus는 대용량 데이터 세트로 작업할 때 쓰기 성능을 향상시키기 위해 Bulkinsert 기능을 제공합니다. 그러나 Milvus에서 사용하는 JSON 형식은 Spark의 기본 JSON 출력 형식과 약간 다릅니다. 이 문제를 해결하기 위해 Milvus 요구 사항을 충족하는 데이터를 생성하기 위해 mjson 데이터 형식을 도입했습니다. 다음은 JSON-lines와 mjson의 차이점을 보여주는 예제입니다:
JSON-lines:
{"book_id": 101, "word_count": 13, "book_intro": [1.1, 1.2]} {"book_id": 102, "word_count": 25, "book_intro": [2.1, 2.2]} {"book_id": 103, "word_count": 7, "book_intro": [3.1, 3.2]} {"book_id": 104, "word_count": 12, "book_intro": [4.1, 4.2]} {"book_id": 105, "word_count": 34, "book_intro": [5.1, 5.2]}mjson(Milvus Bulkinsert에 필요):
{ "rows":[ {"book_id": 101, "word_count": 13, "book_intro": [1.1, 1.2]}, {"book_id": 102, "word_count": 25, "book_intro": [2.1, 2.2]}, {"book_id": 103, "word_count": 7, "book_intro": [3.1, 3.2]}, {"book_id": 104, "word_count": 12, "book_intro": [4.1, 4.2]}, {"book_id": 105, "word_count": 34, "book_intro": [5.1, 5.2]} ] }
이 기능은 향후 개선될 예정입니다. 사용 중인 Milvus 버전이 Parquet 형식의 bulkinsert를 지원하는 v2.3.7 이상인 경우 spark-milvus 연동에서 Parquet 형식을 사용하는 것이 좋습니다. 깃허브의 데모를 참조하세요.
MilvusUtils
MilvusUtils에는 몇 가지 유용한 유틸리티 함수가 포함되어 있습니다. 현재는 Scala에서만 지원됩니다. 더 많은 사용 예제는 고급 사용법 섹션에 있습니다.
MilvusUtils.readMilvusCollection
MilvusUtils.readMilvusCollection은 전체 Milvus 컬렉션을 Spark 데이터 프레임에 로드하기 위한 간단한 인터페이스입니다. Milvus SDK 호출, 밀버스빈로그 읽기 및 일반적인 유니온/조인 작업을 포함한 다양한 작업을 래핑합니다.
val collectionDF = MilvusUtils.readMilvusCollection(spark, milvusOptions)
MilvusUtils.bulkInsertFromSpark
MilvusUtils.bulkInsertFromSpark는 Spark 출력 파일을 Milvus로 대량으로 가져올 수 있는 편리한 방법을 제공합니다. Milvus SDK의 Bullkinsert API를 래핑합니다.
df.write.format("parquet").save(outputPath)
MilvusUtils.bulkInsertFromSpark(spark, milvusOptions, outputPath, "parquet")
고급 사용법
이 섹션에서는 데이터 분석 및 마이그레이션을 위한 Spark-Milvus 커넥터의 고급 사용 예제를 찾을 수 있습니다. 더 많은 데모는 예제를 참조하세요.
MySQL -> 임베딩 -> Milvus
이 데모에서는 다음을 수행합니다.
- Spark-MySQL 커넥터를 통해 MySQL에서 데이터를 읽습니다,
- 임베딩 생성(Word2Vec을 예로 사용), 그리고
- 임베딩된 데이터를 Milvus에 쓰기.
Spark-MySQL 커넥터를 활성화하려면 Spark 환경에 다음 종속성을 추가해야 합니다:
spark-shell --jars spark-milvus-1.0.0-SNAPSHOT.jar,mysql-connector-j-x.x.x.jar
import org.apache.spark.ml.feature.{Tokenizer, Word2Vec}
import org.apache.spark.sql.functions.udf
import org.apache.spark.sql.{SaveMode, SparkSession}
import zilliztech.spark.milvus.MilvusOptions._
import org.apache.spark.ml.linalg.Vector
object Mysql2MilvusDemo extends App {
val spark = SparkSession.builder().master("local[*]")
.appName("Mysql2MilvusDemo")
.getOrCreate()
import spark.implicits._
// Create DataFrame
val sampleDF = Seq(
(1, "Milvus was created in 2019 with a singular goal: store, index, and manage massive embedding vectors generated by deep neural networks and other machine learning (ML) models."),
(2, "As a database specifically designed to handle queries over input vectors, it is capable of indexing vectors on a trillion scale. "),
(3, "Unlike existing relational databases which mainly deal with structured data following a pre-defined pattern, Milvus is designed from the bottom-up to handle embedding vectors converted from unstructured data."),
(4, "As the Internet grew and evolved, unstructured data became more and more common, including emails, papers, IoT sensor data, Facebook photos, protein structures, and much more.")
).toDF("id", "text")
// Write to MySQL Table
sampleDF.write
.mode(SaveMode.Append)
.format("jdbc")
.option("driver","com.mysql.cj.jdbc.Driver")
.option("url", "jdbc:mysql://localhost:3306/test")
.option("dbtable", "demo")
.option("user", "root")
.option("password", "123456")
.save()
// Read from MySQL Table
val dfMysql = spark.read
.format("jdbc")
.option("driver","com.mysql.cj.jdbc.Driver")
.option("url", "jdbc:mysql://localhost:3306/test")
.option("dbtable", "demo")
.option("user", "root")
.option("password", "123456")
.load()
val tokenizer = new Tokenizer().setInputCol("text").setOutputCol("tokens")
val tokenizedDf = tokenizer.transform(dfMysql)
// Learn a mapping from words to Vectors.
val word2Vec = new Word2Vec()
.setInputCol("tokens")
.setOutputCol("vectors")
.setVectorSize(128)
.setMinCount(0)
val model = word2Vec.fit(tokenizedDf)
val result = model.transform(tokenizedDf)
val vectorToArrayUDF = udf((v: Vector) => v.toArray)
// Apply the UDF to the DataFrame
val resultDF = result.withColumn("embedding", vectorToArrayUDF($"vectors"))
val milvusDf = resultDF.drop("tokens").drop("vectors")
milvusDf.write.format("milvus")
.option(MILVUS_HOST, "localhost")
.option(MILVUS_PORT, "19530")
.option(MILVUS_COLLECTION_NAME, "text_embedding")
.option(MILVUS_COLLECTION_VECTOR_FIELD, "embedding")
.option(MILVUS_COLLECTION_VECTOR_DIM, "128")
.option(MILVUS_COLLECTION_PRIMARY_KEY, "id")
.mode(SaveMode.Append)
.save()
}
Milvus -> Transform -> Milvus
이 데모에서는 다음을 수행합니다.
- Milvus 컬렉션에서 데이터를 읽습니다,
- 변환을 적용하고(PCA를 예로 사용), 그리고
- 변환된 데이터를 Bulkinsert API를 통해 다른 Milvus에 기록합니다.
PCA 모델은 머신 러닝에서 흔히 사용되는 임베딩 벡터의 차원을 줄이는 변환 모델입니다. 변환 단계에 필터링, 조인, 정규화 등 다른 처리 작업을 추가할 수 있습니다.
import org.apache.spark.ml.feature.PCA
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.udf
import org.apache.spark.sql.util.CaseInsensitiveStringMap
import zilliztech.spark.milvus.{MilvusOptions, MilvusUtils}
import scala.collection.JavaConverters._
object TransformDemo extends App {
val sparkConf = new SparkConf().setMaster("local")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
val host = "localhost"
val port = 19530
val user = "root"
val password = "Milvus"
val fs = "s3a://"
val bucketName = "a-bucket"
val rootPath = "files"
val minioAK = "minioadmin"
val minioSK = "minioadmin"
val minioEndpoint = "localhost:9000"
val collectionName = "hello_spark_milvus1"
val targetCollectionName = "hello_spark_milvus2"
val properties = Map(
MilvusOptions.MILVUS_HOST -> host,
MilvusOptions.MILVUS_PORT -> port.toString,
MilvusOptions.MILVUS_COLLECTION_NAME -> collectionName,
MilvusOptions.MILVUS_BUCKET -> bucketName,
MilvusOptions.MILVUS_ROOTPATH -> rootPath,
MilvusOptions.MILVUS_FS -> fs,
MilvusOptions.MILVUS_STORAGE_ENDPOINT -> minioEndpoint,
MilvusOptions.MILVUS_STORAGE_USER -> minioAK,
MilvusOptions.MILVUS_STORAGE_PASSWORD -> minioSK,
)
// 1, configurations
val milvusOptions = new MilvusOptions(new CaseInsensitiveStringMap(properties.asJava))
// 2, batch read milvus collection data to dataframe
// Schema: dim of `embeddings` is 8
// +-+------------+------------+------------------+
// | | field name | field type | other attributes |
// +-+------------+------------+------------------+
// |1| "pk" | Int64 | is_primary=True |
// | | | | auto_id=False |
// +-+------------+------------+------------------+
// |2| "random" | Double | |
// +-+------------+------------+------------------+
// |3|"embeddings"| FloatVector| dim=8 |
// +-+------------+------------+------------------+
val arrayToVectorUDF = udf((arr: Seq[Double]) => Vectors.dense(arr.toArray[Double]))
val collectionDF = MilvusUtils.readMilvusCollection(spark, milvusOptions)
.withColumn("embeddings_vec", arrayToVectorUDF($"embeddings"))
.drop("embeddings")
// 3. Use PCA to reduce dim of vector
val dim = 4
val pca = new PCA()
.setInputCol("embeddings_vec")
.setOutputCol("pca_vec")
.setK(dim)
.fit(collectionDF)
val vectorToArrayUDF = udf((v: Vector) => v.toArray)
// embeddings dim number reduce to 4
// +-+------------+------------+------------------+
// | | field name | field type | other attributes |
// +-+------------+------------+------------------+
// |1| "pk" | Int64 | is_primary=True |
// | | | | auto_id=False |
// +-+------------+------------+------------------+
// |2| "random" | Double | |
// +-+------------+------------+------------------+
// |3|"embeddings"| FloatVector| dim=4 |
// +-+------------+------------+------------------+
val pcaDf = pca.transform(collectionDF)
.withColumn("embeddings", vectorToArrayUDF($"pca_vec"))
.select("pk", "random", "embeddings")
// 4. Write PCAed data to S3
val outputPath = "s3a://a-bucket/result"
pcaDf.write
.mode("overwrite")
.format("parquet")
.save(outputPath)
// 5. Config MilvusOptions of target table
val targetProperties = Map(
MilvusOptions.MILVUS_HOST -> host,
MilvusOptions.MILVUS_PORT -> port.toString,
MilvusOptions.MILVUS_COLLECTION_NAME -> targetCollectionName,
MilvusOptions.MILVUS_BUCKET -> bucketName,
MilvusOptions.MILVUS_ROOTPATH -> rootPath,
MilvusOptions.MILVUS_FS -> fs,
MilvusOptions.MILVUS_STORAGE_ENDPOINT -> minioEndpoint,
MilvusOptions.MILVUS_STORAGE_USER -> minioAK,
MilvusOptions.MILVUS_STORAGE_PASSWORD -> minioSK,
)
val targetMilvusOptions = new MilvusOptions(new CaseInsensitiveStringMap(targetProperties.asJava))
// 6. Bulkinsert Spark output files into milvus
MilvusUtils.bulkInsertFromSpark(spark, targetMilvusOptions, outputPath, "parquet")
}
데이터브릭 -> 질리즈 클라우드
Zilliz Cloud(관리형 Milvus 서비스)를 사용하는 경우, 편리한 데이터 가져오기 API를 활용할 수 있습니다. 질리즈 클라우드는 스파크, 데이터브릭스 등 다양한 데이터 소스에서 데이터를 효율적으로 옮길 수 있는 종합적인 도구와 설명서를 제공합니다. S3 버킷을 중개자로 설정하고 질리즈 클라우드 계정에 액세스 권한을 열기만 하면 됩니다. 질리즈 클라우드의 데이터 가져오기 API가 S3 버킷의 전체 데이터를 자동으로 질리즈 클라우드 클러스터로 불러옵니다.
준비 과정
데이터브릭스 클러스터에 jar 파일을 추가하여 Spark 런타임을 로드합니다.
다양한 방법으로 라이브러리를 설치할 수 있습니다. 이 스크린샷은 로컬에서 클러스터로 jar를 업로드하는 방법을 보여줍니다. 자세한 내용은 Databricks 설명서에서 클러스터 라이브러리를 참조하세요.
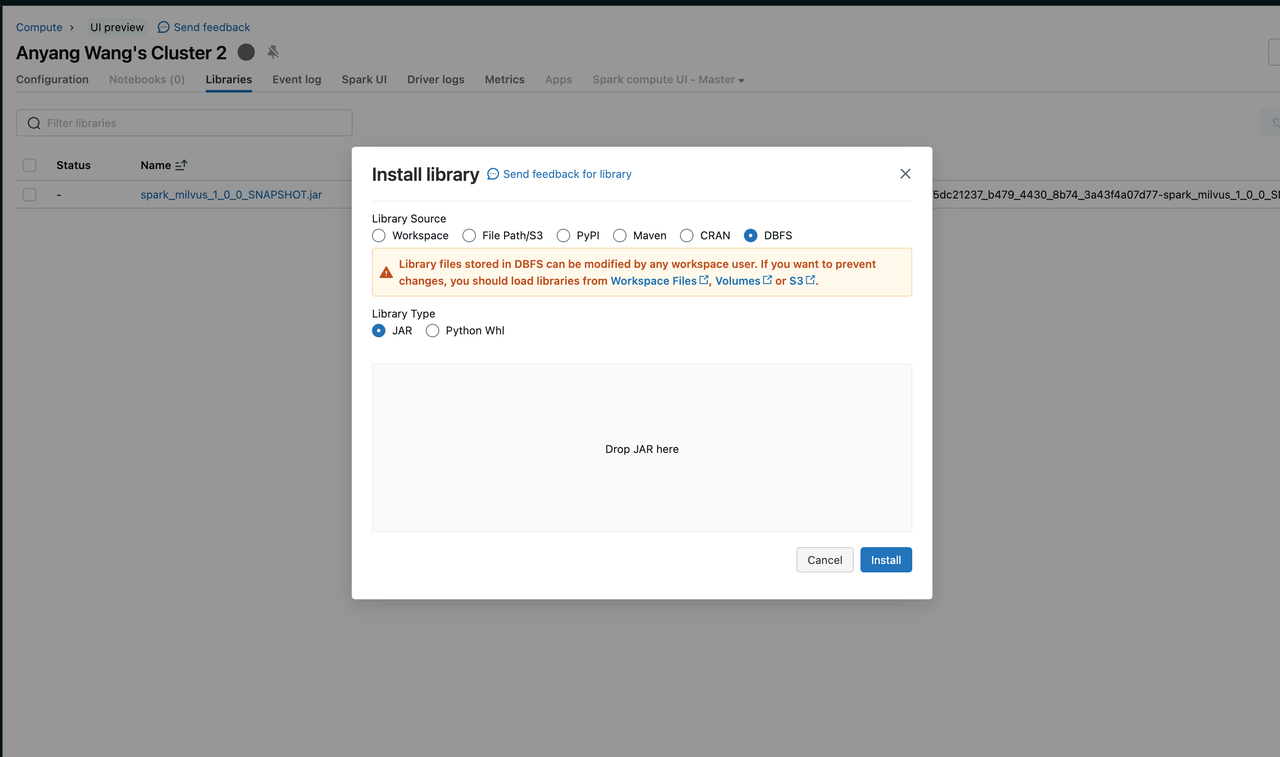 데이터브릭스 라이브러리 설치
데이터브릭스 라이브러리 설치 S3 버킷을 생성하고 이를 Databricks 클러스터의 외부 저장 위치로 구성합니다.
불킨서트는 데이터를 임시 버킷에 저장해야 질리즈 클라우드에서 일괄적으로 데이터를 가져올 수 있습니다. S3 버킷을 생성하여 데이터브릭의 외부 위치로 설정할 수 있습니다. 자세한 내용은 외부 위치를 참고하세요.
데이터브릭스 자격 증명을 보호합니다.
자세한 내용은 데이터브릭스에서 자격증명 안전하게 관리하기 블로그의 안내를 참조하세요.
데모
다음은 일괄 데이터 마이그레이션 프로세스를 보여주는 코드 스니펫입니다. 위의 Milvus 예제와 마찬가지로 자격 증명과 S3 버킷 주소만 바꾸면 됩니다.
// Write the data in batch into the Milvus bucket storage.
val outputPath = "s3://my-temp-bucket/result"
df.write
.mode("overwrite")
.format("mjson")
.save(outputPath)
// Specify Milvus options.
val targetProperties = Map(
MilvusOptions.MILVUS_URI -> zilliz_uri,
MilvusOptions.MILVUS_TOKEN -> zilliz_token,
MilvusOptions.MILVUS_COLLECTION_NAME -> targetCollectionName,
MilvusOptions.MILVUS_BUCKET -> bucketName,
MilvusOptions.MILVUS_ROOTPATH -> rootPath,
MilvusOptions.MILVUS_FS -> fs,
MilvusOptions.MILVUS_STORAGE_ENDPOINT -> minioEndpoint,
MilvusOptions.MILVUS_STORAGE_USER -> minioAK,
MilvusOptions.MILVUS_STORAGE_PASSWORD -> minioSK,
)
val targetMilvusOptions = new MilvusOptions(new CaseInsensitiveStringMap(targetProperties.asJava))
// Bulk insert Spark output files into Milvus
MilvusUtils.bulkInsertFromSpark(spark, targetMilvusOptions, outputPath, "mjson")
실습
Spark-Milvus 커넥터를 빠르게 시작할 수 있도록 Milvus와 Zilliz Cloud를 사용한 스트리밍 및 일괄 데이터 전송 프로세스를 모두 안내하는 노트북을 준비했습니다.