Tiered Storage OverviewCompatible with Milvus 2.6.4+
In Milvus, the traditional full-load mode requires each QueryNode to load all data fields and indexes of a segment at initialization, even data that may never be accessed. This ensures immediate data availability but often leads to wasted resources, including high memory usage, heavy disk activity, and significant I/O overhead, especially when handling large-scale datasets.
Tiered Storage addresses this challenge by decoupling data caching from segment loading. Instead of loading all data at once, Milvus introduces a caching layer that distinguishes between hot data (cached locally) and cold data (stored remotely). The QueryNode now loads only lightweight metadata initially and dynamically pulls or evicts field data on demand. This significantly reduces load time, optimizes local resource utilization, and enables QueryNodes to process datasets that far exceed their physical memory or disk capacity.
Consider enabling Tiered Storage in scenarios such as:
Collections that exceed the available memory or NVMe capacity of a single QueryNode
Analytical or batch workloads where faster loading is more important than the first-query latency
Mixed workloads that can tolerate occasional cache misses for less frequently accessed data
Metadata includes schema, index definitions, chunk maps, row counts, and references to remote objects. This type of data is small, always cached, and never evicted.
For more details on segments and chunks, refer to Segment.
How it works
Tiered Storage changes how QueryNode manages segment data. Instead of caching every field and index at load time, QueryNode now loads metadata only and uses a caching layer to fetch and evict data dynamically.
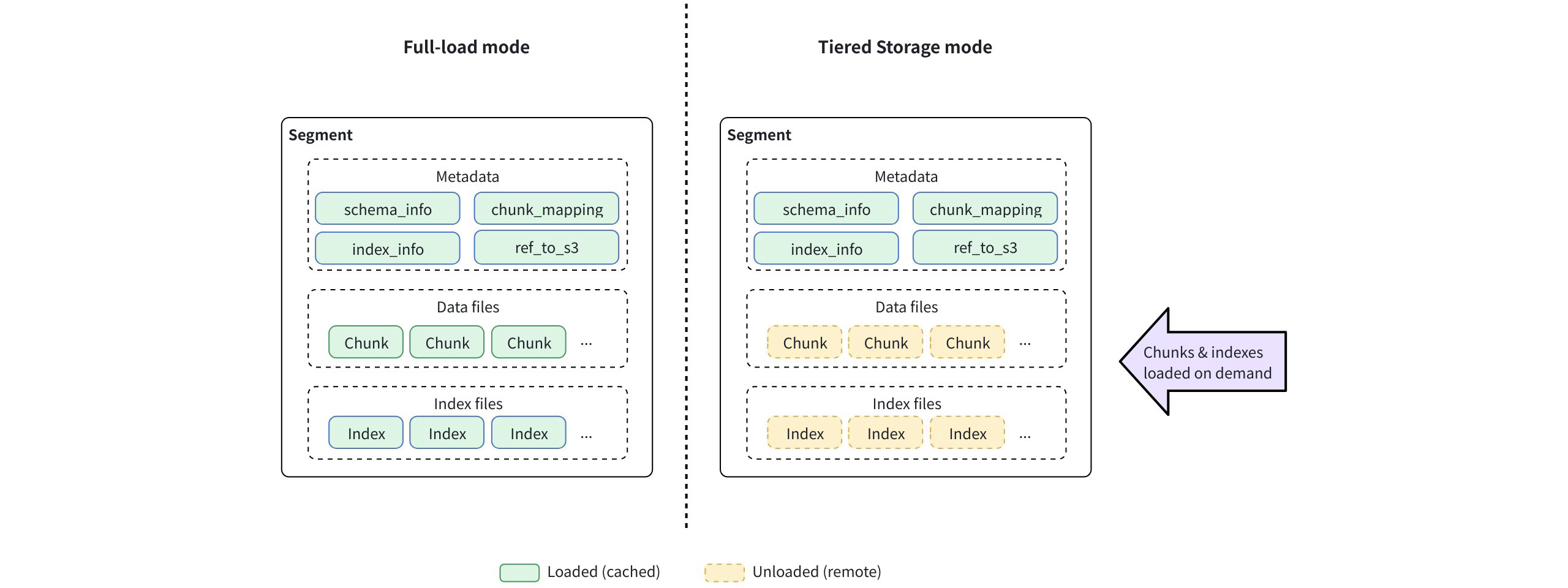
Full-load mode vs. Tiered Storage mode
While both full-load and Tiered Storage modes handle the same data, they differ in when and how QueryNode caches these components.
Full-load mode: At load time, QueryNode caches full collection data, including metadata, field data, and indexes, from object storage.
Tiered Storage mode: At load time, QueryNode caches metadata only. Field data is pulled on demand at chunk granularity. Index files remain remote until the first query needs them; then the entire per-segment index is fetched and cached.
The diagram below shows these differences.
 Full Load Mode Vs Tiered Storage Mode
Full Load Mode Vs Tiered Storage Mode
QueryNode loading workflow
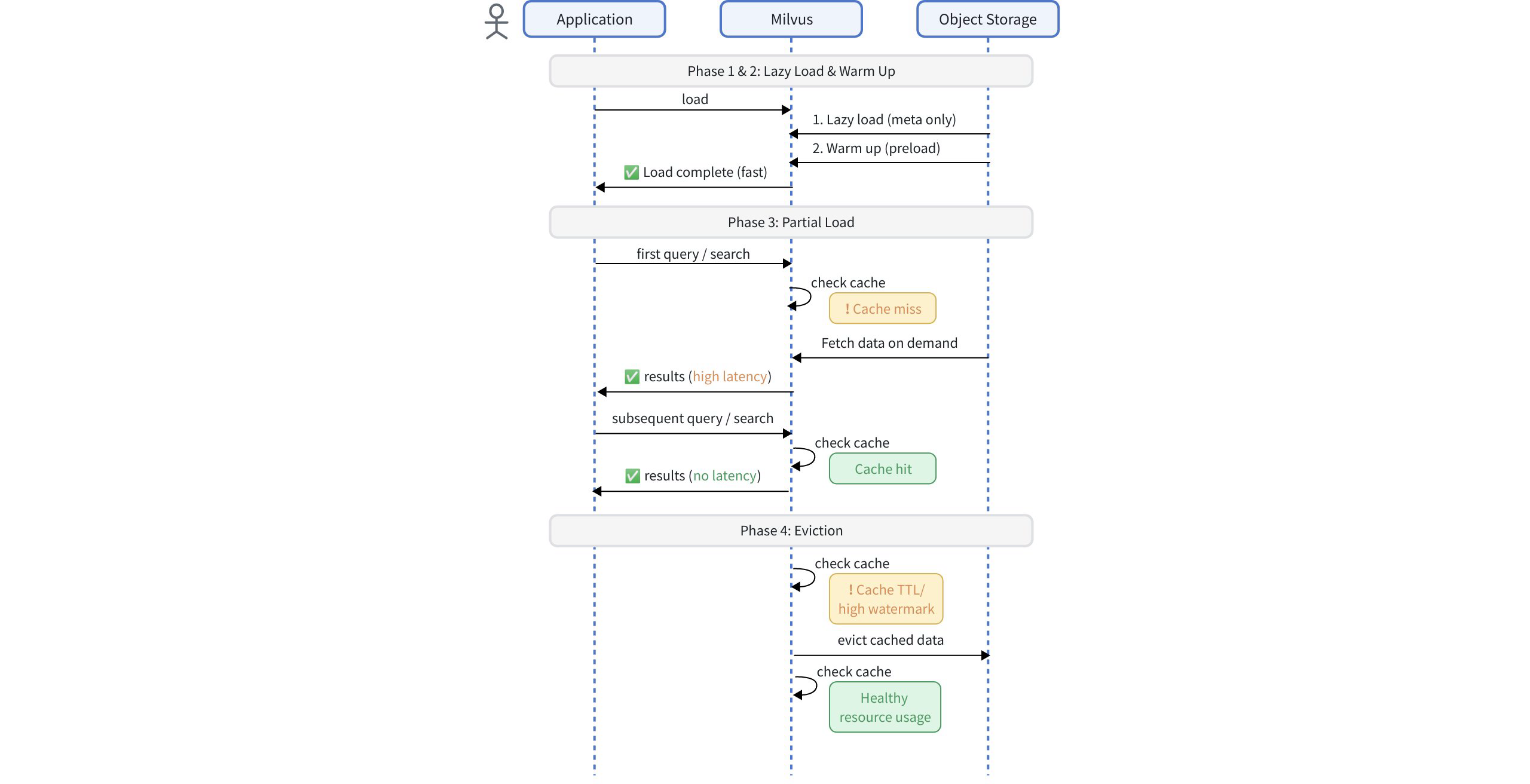
Under Tiered Storage, the workflow has these phases:
 Querynode Load Workflow
Querynode Load Workflow
Phase 1: Lazy load
At initialization, Milvus performs a lazy load, caching only segment-level metadata such as schema definitions, index information, and chunk mappings.
No actual field data or index files are cached at this stage. This allows collections to become queryable almost immediately after startup while keeping memory and disk consumption minimal.
Because field data and index files remain in remote storage until first accessed, the first query may experience additional latency as required data must be fetched on demand. To mitigate this effect for critical fields or indexes, you can use the Warm Up strategy to proactively preload them before the segment becomes queryable.
Configuration
Automatically applied when Tiered Storage is enabled. No manual setting is required.
Phase 2: Warm up
To reduce the first-hit latency introduced by lazy load, Milvus provides a Warm Up mechanism.
Before a segment becomes queryable, Milvus can proactively fetch and cache specific fields or indexes from object storage, ensuring that the first query directly hits cached data instead of triggering on-demand loading.
During warmup, fields will be preloaded at the chunk level, while indexes will be preloaded at the segment level.
Configuration
Warm Up settings are defined in the Tiered Storage section of milvus.yaml. You can enable or disable preloading for each field or index type and specify the preferred strategy. See Warm Up for detailed configurations.
Phase 3: Partial load
Once queries or searches begin, the QueryNode performs a partial load, fetching only the required data chunks or index files from object storage.
Fields: Loaded on demand at the chunk level. Only data chunks that match the current query conditions are fetched, minimizing I/O and memory use.
Indexes: Loaded on demand at the segment level. Index files must be fetched as complete units and cannot be split across chunks.
Configuration
Partial load is automatically applied when Tiered Storage is enabled. No manual setting is required. To minimize first-hit latency for critical data, combine with Warm Up.
Phase 4: Eviction
To maintain healthy resource usage, Milvus automatically releases unused cached data when specific thresholds are reached.
Eviction follows a Least Recently Used (LRU) policy, ensuring that infrequently accessed data is removed first while active data remains in cache.
Eviction is governed by the following configurable items:
Watermarks: Define memory or disk thresholds that trigger and stop eviction.
Cache TTL: Removes stale cached data after a defined duration of inactivity.
Configuration
Enable and tune eviction parameters in milvus.yaml. See Eviction for detailed configuration.
Getting started
Prerequisites
Milvus 2.6.4+
QueryNodes with dedicated memory and disk resources
Object storage backend (S3, MinIO, etc.)
QueryNode resources should not be shared with other workloads. Shared resources can cause Tiered Storage to misjudge available capacity, leading to crashes.
Basic configuration template
Edit the Milvus configuration file (milvus.yaml) to configure Tiered Storage settings:
# milvus.yaml
queryNode:
segcore:
tieredStorage:
# Warm Up Configuration
warmup:
scalarField: sync # Preload scalar field data
scalarIndex: sync # Preload scalar indexes
vectorField: disable # Don't preload vector field data (large)
vectorIndex: sync # Preload vector indexes
# Eviction Configuration
evictionEnabled: true
backgroundEvictionEnabled: true
# Memory Watermarks
memoryLowWatermarkRatio: 0.75 # Stop evicting at 75%
memoryHighWatermarkRatio: 0.80 # Start evicting at 80%
# Disk Watermarks
diskLowWatermarkRatio: 0.75
diskHighWatermarkRatio: 0.80
# Cache TTL (7 days)
cacheTtl: 604800
Next steps
Configure Warm Up - Optimize preloading for your access patterns. See Warm Up.
Tune Eviction - Set appropriate watermarks and TTL for your resource constraints. See Eviction.
Monitor Performance - Track cache hit rates, eviction frequency, and query latency patterns.
Iterate Configuration - Adjust settings based on observed workload characteristics.
FAQ
Can I change Tiered Storage parameters at runtime?
No. All parameters must be set in milvus.yaml before starting Milvus. Changes require a restart to take effect.
Does Tiered Storage affect data durability?
No. Data persistence is still handled by remote object storage. Tiered Storage only manages caching on QueryNodes.
Will queries always be faster with Tiered Storage?
Not necessarily. Tiered Storage reduces load time and resource usage, but queries that touch uncached (cold) data may see higher latency. For latency-sensitive workloads, full-load mode is recommended.
Why does a QueryNode still run out of resources even with Tiered Storage enabled?
Two common causes:
The QueryNode was configured with too few resources. Watermarks are relative to available resources, so under-provisioning amplifies misjudgment.
QueryNode resources are shared with other workloads, so Tiered Storage cannot correctly assess actual available capacity.
To resolve this, we recommend you allocate dedicated resources for QueryNodes.
Why do some queries fail under high concurrency?
If too many queries hit hot data at the same time, QueryNode resource limits may still be exceeded. Some threads may fail due to resource reservation timeouts. Retrying after the load decreases, or allocating more resources, can resolve this.
Why does search/query latency increase after enabling Tiered Storage?
Possible causes include:
Frequent queries to cold data, which must be fetched from storage.
Watermarks set too close together, causing frequent synchronous eviction.